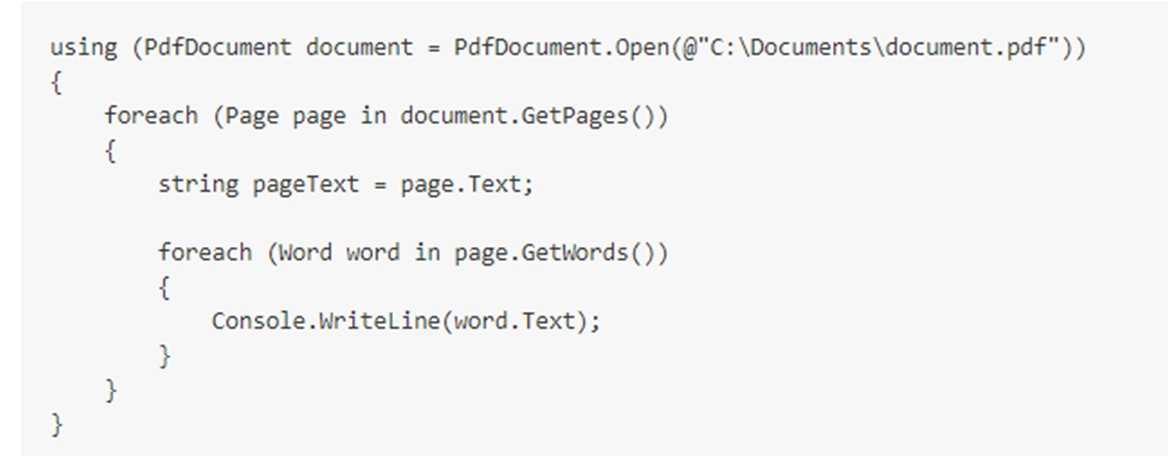
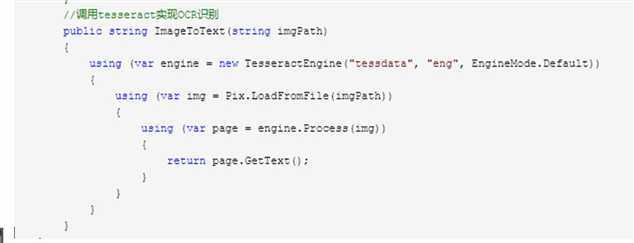
对于读取识别pdf全文库 使用pdfpig 代码如下:
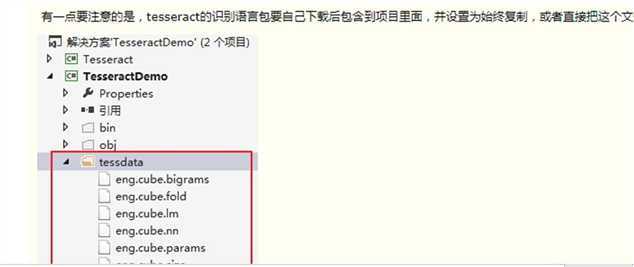
图片orc识别使用 Tesseract
全文检索 识别pdf 图片OCR识别
原文:https://www.cnblogs.com/zwbsoft/p/12884516.html