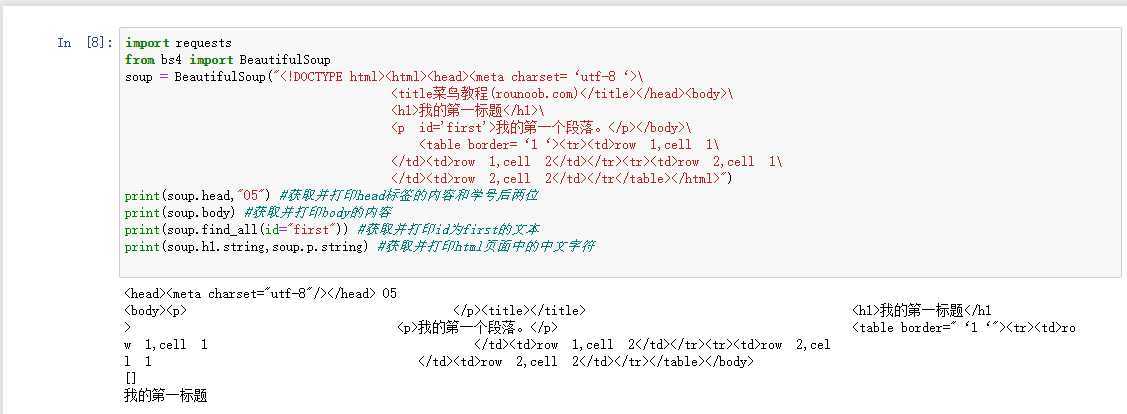
5第一个爬虫和测试
一:完善球赛程序,测试函数
1、测试printInfo()(程序的介绍性信息)
1 def printInfo():
2 print("这个程序模拟两个选手A和B的羽毛球竞技比赛")
3 print("程序需要两个选手的能力值0-1")
4 print("规则:三局两胜--21分制")
5
6 printInfo()
2、测试getInput()(输入函数)
1 def getInput():
2 a = eval(input("请输入选手A的能力值(0-1):"))
3
4 b = eval(input("请输入选手B的能力值(0-1):"))
5
6 m=eval(input("比赛的局数:"))
7
8 n = eval(input("模拟比赛的场次:"))
9 return a,b,m,n
10
11 getInput()
3、测试printfSummary(打印结果)
1 def printSummary(winsA,winsB):
2
3 n = winsA + winsB
4
5 print("竞技分析开始,共模拟{}场比赛".format(n))
6
7 print("选手A获胜{}场比赛,占比{:0.1%}".format(winsA,winsA/n))
8
9 print("选手B获胜{}场比赛,占比{:0.1%}".format(winsB,winsB/n))
10
11 winA=eval(input())
12 winB=eval(input())
13 printSummary(winA,winB)
4、测试simNGames()(计算赢得比赛的场数)
1 def simNGames(m,n,probA,probB):
2
3 winsA,winsB = 0,0
4 wa,wb=0,0
5
6 for i in range(n):
7 for i in range(m):
8
9 #scoreA,scoreB = simOneGame(probA,probB)
10 scoreA,scoreB=probA,probB
11 if scoreA > scoreB:
12 wa += 1
13 else:
14 wb += 1
15
16 if wa==2:
17 winsA+=1
18 wa,wb=0,0
19 break
20 if wb==2:
21 winsB+=1
22 wa,wb=0,0
23 break
24 return winsA,winsB
25
26 m=eval(input())
27 n=eval(input())
28 probA=eval(input())
29 probB=eval(input())
30 print(simNGames(m,n,probA,probB))
5、测试simOneGame()(统计一局比赛的分数)
1 from random import random
2 def simOneGame(probA,probB):
3
4 scoreA,scoreB = 0,0
5
6 serving = "A"
7 while not gameOver(scoreA,scoreB):
8
9 if serving == "A":
10
11 if random() < probA:
12
13 scoreA += 1
14 else:
15 serving = "B"
16 else:
17 if random() < probB:
18 scoreB += 1
19 else:
20 serving = "A"
21 return scoreA,scoreB
22
23 def gameOver(a,b):
24 24 if(a>=20 or b>=20):
25 25 if(abs(a-b)==2 and a<=29 and b<=29):
26 26 return True
27 27 else:
28 28 return a==30 or b==30
29 29 else:
30 30 return False
31 31
32 32 #for i in range(10):
33 33 a=eval(input())
34 34 b=eval(input())
35 35 print(gameOver(a,b))
36 36
37 37 probA=eval(input())
38 38 probB=eval(input())
39 39 print(simOneGame(probA,probB))
二:用requests的get()函数访问一个网站(google)
import requests
response = requests.get("http://www.google.cn/")
print(type(response))
status_code = response.status_code
print(status_code)
text = response.text
print(text)
encoding = response.encoding
print(encoding)
encoding1 = response.encoding = ‘utf-8‘
print(encoding1)
text1 = response.text
print("text内容为:{}".format(text1))
print("\n")
print("text内容长度为:{}".format(len(text1)))
结果:
<class ‘requests.models.Response‘>
200
<!DOCTYPE html>
<html lang="zh">
<meta charset="utf-8">
<title>Google</title>
<style>
html { background: #fff; margin: 0 1em; }
body { font: .8125em/1.5 arial, sans-serif; text-align: center; }
h1 { font-size: 1.5em; font-weight: normal; margin: 1em 0 0; }
p#footer { color: #767676; font-size: .77em; }
p#footer a { background: url(//www.google.cn/intl/zh-CN_cn/images/cn_icp.gif) top right no-repeat; padding: 5px 20px 5px 0; }
ul { margin: 2em; padding: 0; }
li { display: inline; padding: 0 2em; }
div { -moz-border-radius: 20px; -webkit-border-radius: 20px; border: 1px solid #ccc; border-radius: 20px; margin: 2em auto 1em; max-width: 650px; min-width: 544px; }
div:hover, div:hover * { cursor: pointer; }
div:hover { border-color: #999; }
div p { margin: .5em 0 1.5em; }
img { border: 0; }
</style>
<div>
<a href="http://www.google.com.hk/webhp?hl=zh-CN&sourceid=cnhp">
<img src="//www.google.cn/landing/cnexp/google-search.png" alt="Google" width="586" height="257">
</a>
<h1><a href="http://www.google.com.hk/webhp?hl=zh-CN&sourceid=cnhp"><strong id="target">google.com.hk</strong></a></h1>
<p>请æ?¶è??æ??们ç??ç½?å??
</div>
<ul>
<li><a href="http://translate.google.cn/?sourceid=cnhp">翻�</a>
</ul>
<p id="footer">©2011 - <a href="http://www.miibeian.gov.cn/">ICPè¯?å??å?B2-20070004å?·</a>
<script nonce="dhqnO3bekiHlxDG1hGYxtQ">
var gcn=gcn||{};gcn.IS_IMAGES=(/images\.google\.cn/.exec(window.location)||window.location.hash==‘#images‘||window.location.hash==‘images‘);gcn.HOMEPAGE_DEST=‘http://www.google.com.hk/webhp?hl=zh-CN&sourceid=cnhp‘;gcn.IMAGES_DEST=‘http://images.google.com.hk/imghp?‘+‘hl=zh-CN&sourceid=cnhp‘;gcn.DEST_URL=gcn.IS_IMAGES?gcn.IMAGES_DEST:gcn.HOMEPAGE_DEST;gcn.READABLE_HOMEPAGE_URL=‘google.com.hk‘;gcn.READABLE_IMAGES_URL=‘images.google.com.hk‘;gcn.redirectIfLocationHasQueryParams=function(){if(window.location.search&&/google\.cn/.exec(window.location)&&!/webhp/.exec(window.location)){window.location=String(window.location).replace(‘google.cn‘,‘google.com.hk‘)}}();gcn.replaceHrefsWithImagesUrl=function(){if(gcn.IS_IMAGES){var a=document.getElementsByTagName(‘a‘);for(var i=0,len=a.length;i<len;i++){if(a[i].href==gcn.HOMEPAGE_DEST){a[i].href=gcn.IMAGES_DEST}}}}();gcn.listen=function(a,e,b){if(a.addEventListener){a.addEventListener(e,b,false)}else if(a.attachEvent){var r=a.attachEvent(‘on‘+e,b);return r}};gcn.stopDefaultAndProp=function(e){if(e&&e.preventDefault){e.preventDefault()}else if(window.event&&window.event.returnValue){window.eventReturnValue=false;return false}if(e&&e.stopPropagation){e.stopPropagation()}else if(window.event&&window.event.cancelBubble){window.event.cancelBubble=true;return false}};gcn.resetChildElements=function(a){var b=a.childNodes;for(var i=0,len=b.length;i<len;i++){gcn.listen(b[i],‘click‘,gcn.stopDefaultAndProp)}};gcn.redirect=function(){window.location=gcn.DEST_URL};gcn.setInnerHtmlInEl=function(a){if(gcn.IS_IMAGES){var b=document.getElementById(a);if(b){b.innerHTML=b.innerHTML.replace(gcn.READABLE_HOMEPAGE_URL,gcn.READABLE_IMAGES_URL)}}};
gcn.listen(document, ‘click‘, gcn.redirect);
gcn.setInnerHtmlInEl(‘target‘);
</script>
ISO-8859-1
utf-8
text内容为:<!DOCTYPE html>
<html lang="zh">
<meta charset="utf-8">
<title>Google</title>
<style>
html { background: #fff; margin: 0 1em; }
body { font: .8125em/1.5 arial, sans-serif; text-align: center; }
h1 { font-size: 1.5em; font-weight: normal; margin: 1em 0 0; }
p#footer { color: #767676; font-size: .77em; }
p#footer a { background: url(//www.google.cn/intl/zh-CN_cn/images/cn_icp.gif) top right no-repeat; padding: 5px 20px 5px 0; }
ul { margin: 2em; padding: 0; }
li { display: inline; padding: 0 2em; }
div { -moz-border-radius: 20px; -webkit-border-radius: 20px; border: 1px solid #ccc; border-radius: 20px; margin: 2em auto 1em; max-width: 650px; min-width: 544px; }
div:hover, div:hover * { cursor: pointer; }
div:hover { border-color: #999; }
div p { margin: .5em 0 1.5em; }
img { border: 0; }
</style>
<div>
<a href="http://www.google.com.hk/webhp?hl=zh-CN&sourceid=cnhp">
<img src="//www.google.cn/landing/cnexp/google-search.png" alt="Google" width="586" height="257">
</a>
<h1><a href="http://www.google.com.hk/webhp?hl=zh-CN&sourceid=cnhp"><strong id="target">google.com.hk</strong></a></h1>
<p>请收藏我们的网址
</div>
<ul>
<li><a href="http://translate.google.cn/?sourceid=cnhp">翻译</a>
</ul>
<p id="footer">©2011 - <a href="http://www.miibeian.gov.cn/">ICP证合字B2-20070004号</a>
<script nonce="dhqnO3bekiHlxDG1hGYxtQ">
var gcn=gcn||{};gcn.IS_IMAGES=(/images\.google\.cn/.exec(window.location)||window.location.hash==‘#images‘||window.location.hash==‘images‘);gcn.HOMEPAGE_DEST=‘http://www.google.com.hk/webhp?hl=zh-CN&sourceid=cnhp‘;gcn.IMAGES_DEST=‘http://images.google.com.hk/imghp?‘+‘hl=zh-CN&sourceid=cnhp‘;gcn.DEST_URL=gcn.IS_IMAGES?gcn.IMAGES_DEST:gcn.HOMEPAGE_DEST;gcn.READABLE_HOMEPAGE_URL=‘google.com.hk‘;gcn.READABLE_IMAGES_URL=‘images.google.com.hk‘;gcn.redirectIfLocationHasQueryParams=function(){if(window.location.search&&/google\.cn/.exec(window.location)&&!/webhp/.exec(window.location)){window.location=String(window.location).replace(‘google.cn‘,‘google.com.hk‘)}}();gcn.replaceHrefsWithImagesUrl=function(){if(gcn.IS_IMAGES){var a=document.getElementsByTagName(‘a‘);for(var i=0,len=a.length;i<len;i++){if(a[i].href==gcn.HOMEPAGE_DEST){a[i].href=gcn.IMAGES_DEST}}}}();gcn.listen=function(a,e,b){if(a.addEventListener){a.addEventListener(e,b,false)}else if(a.attachEvent){var r=a.attachEvent(‘on‘+e,b);return r}};gcn.stopDefaultAndProp=function(e){if(e&&e.preventDefault){e.preventDefault()}else if(window.event&&window.event.returnValue){window.eventReturnValue=false;return false}if(e&&e.stopPropagation){e.stopPropagation()}else if(window.event&&window.event.cancelBubble){window.event.cancelBubble=true;return false}};gcn.resetChildElements=function(a){var b=a.childNodes;for(var i=0,len=b.length;i<len;i++){gcn.listen(b[i],‘click‘,gcn.stopDefaultAndProp)}};gcn.redirect=function(){window.location=gcn.DEST_URL};gcn.setInnerHtmlInEl=function(a){if(gcn.IS_IMAGES){var b=document.getElementById(a);if(b){b.innerHTML=b.innerHTML.replace(gcn.READABLE_HOMEPAGE_URL,gcn.READABLE_IMAGES_URL)}}};
gcn.listen(document, ‘click‘, gcn.redirect);
gcn.setInnerHtmlInEl(‘target‘);
</script>
text内容长度为:3216
三、将一个HTML页面保持为字符串,并完成以下计算要求
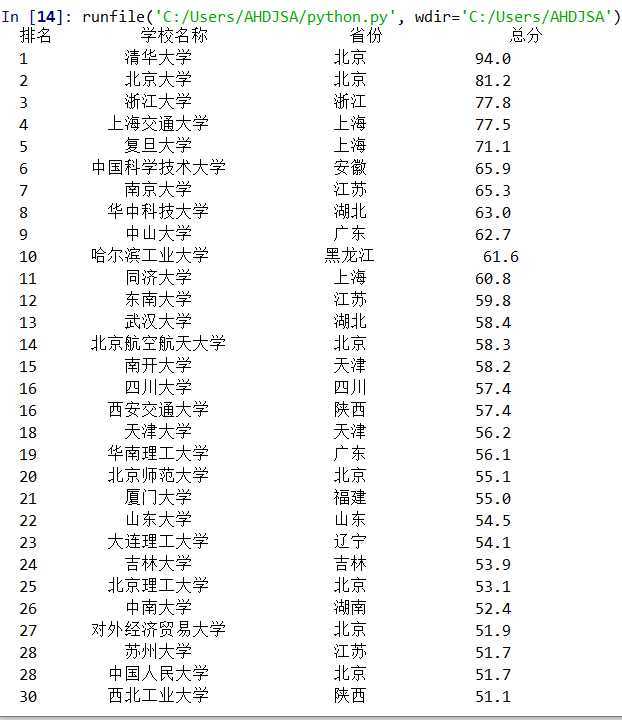
四:爬大学排名
1 import requests
2 from bs4 import BeautifulSoup
3 import bs4
4 def getHTMLText(url):
5 try:
6 r = requests.get(url, timeout = 30)
7 r.raise_for_status
8 r.encoding = r.apparent_encoding
9 return r.text
10 except:
11 return ""
12
13 def fillUnivList(ulist, html):
14 soup = BeautifulSoup(html, "lxml")
15 for tr in soup.find(‘tbody‘).children:
16 if isinstance(tr, bs4.element.Tag):
17 tds = tr(‘td‘)
18 ulist.append([tds[0].string, tds[1].string, tds[2].string,tds[3].string])
19
20 def printUnivList(ulist, num):
21 tplt = "{0:^6}\t{1:{4}^10}\t{2:^10}\t{3:^10}"
22 print(tplt.format("排名","学校名称","省份","总分",chr(12288)))
23 for i in range(num):
24 u = ulist[i]
25 print(tplt.format(u[0],u[1],u[2],u[3],chr(12288)))
26
27 def main():
28 uinfo = []
29 url = "http://www.zuihaodaxue.com/zuihaodaxuepaiming2017.html"
30 html = getHTMLText(url)
31 fillUnivList(uinfo, html)
32 printUnivList(uinfo, 30)
33
34 main()
第一个爬虫和测试
原文:https://www.cnblogs.com/linantelope/p/12883786.html