一、python之测试函数
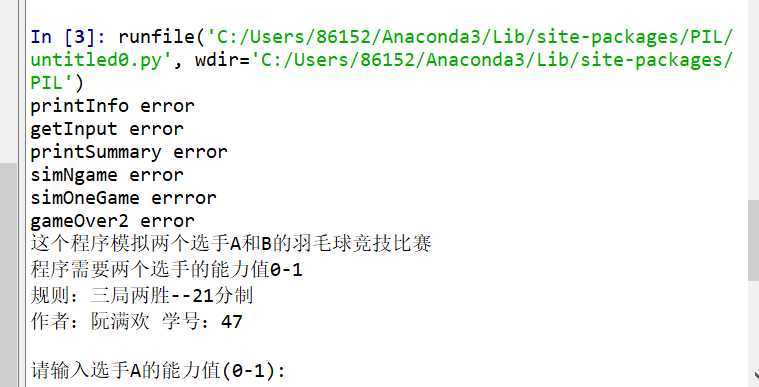
from random import random def main(): printInfo() probA,probB,m,n = getInput() winsA,winsB = simNGames(m,n,probA,probB) printSummary(winsA,winsB) def printInfo(): print("这个程序模拟两个选手A和B的羽毛球竞技比赛") print("程序需要两个选手的能力值0-1") print("规则:三局两胜--21分制") print("作者:阮满欢 学号:47") try: printInfo(x) except: print(‘printInfo error‘) def getInput(): a = eval(input("请输入选手A的能力值(0-1):")) b = eval(input("请输入选手B的能力值(0-1):")) m=eval(input("比赛的局数:")) n = eval(input("模拟比赛的场次:")) return a,b,m,n try: getInput(x) except: print(‘getInput error‘) def printSummary(winsA,winsB): n = winsA + winsB print("竞技分析开始,共模拟{}场比赛".format(n)) print("选手A获胜{}场比赛,占比{:0.1%}".format(winsA,winsA/n)) print("选手B获胜{}场比赛,占比{:0.1%}".format(winsB,winsB/n)) try: printSummary(500) except: print(‘printSummary error‘) def simNGames(m,n,probA,probB): winsA,winsB = 0,0 wa,wb=0,0 for i in range(n): for i in range(m): scoreA,scoreB = simOneGame(probA,probB) if scoreA > scoreB: wa += 1 else: wb += 1 if wa==2: winsA+=1 wa,wb=0,0 break if wb==2: winsB+=1 wa,wb=0,0 break return winsA,winsB try: simNGames(1000, 0.1) except: print(‘simNgame error‘) def simOneGame(probA,probB): scoreA,scoreB = 0,0 serving = "A" while not gameOver(scoreA,scoreB): if serving == "A": if random() < probA: scoreA += 1 else: serving = "B" else: if random() < probB: scoreB += 1 else: serving = "A" return scoreA,scoreB try: simOneGame( 0.1) except: print(‘simOneGame errror‘) def gameOver(a,b): if(a>=20 or b>=20): if(abs(a-b)==2 and a<=29 and b<=29): return True else: return a==30 or b==30 else: return False try: gameOver(10) except: print(‘gameOver2 error‘) main()
这个代码中,在每个函数后都有try.....except测试了一遍,如果有错误会分别对某个函数进行报错。
因为我在参数中故意写错,故会出现错误,因此运行结果:
二、第一次爬虫之访问360搜索主页网页
1、Requests库概述
requests库支持非常丰富的链接访问功能,包括:国际域名和URL获取、HTTP常链接和链接缓存、HTTP会话和Cookie保持、浏览器使用风格SSL验证、基本的摘要认证、有效的键值对Cookie记录、自动解压缩、文件分块上传、HTTP(S)代理功能、链接超时处理、流数据下载等。有关requests库更多的介绍可访问:http://docs.python-requests.org
2、requests库中访问网页的请求函数
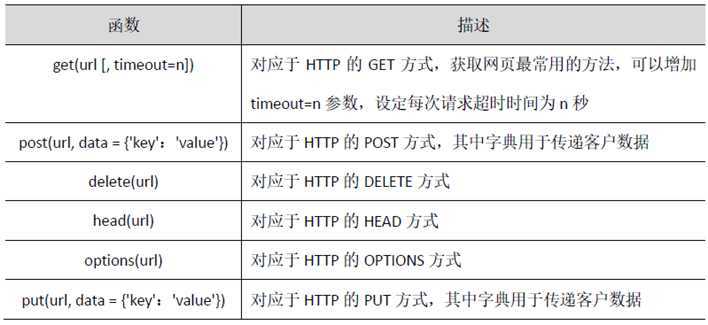
3、用requeses库的个体()函数访问必应主页20次,打印返回状态,text内容,并且计算text()属性和content属性返回网页内容的长度
import requests
def getHTMLText(self):
try:
for i in range(0,20): #访问20次
r = requests.get(url, timeout=30)
r.raise_for_status() #如果状态不是200,引发异常
r.encoding = ‘utf-8‘ #无论原来用什么编码,都改成utf-8
return r.status_code,r.text,r.content,len(r.text),len(r.content) ##返回状态,text和content内容,text()和content()网页的长度
except:
return ""
url = "http://www.so.com/"
print(getHTMLText(url))
其运行结果(因为运行结果过长,这里只展示一部分):
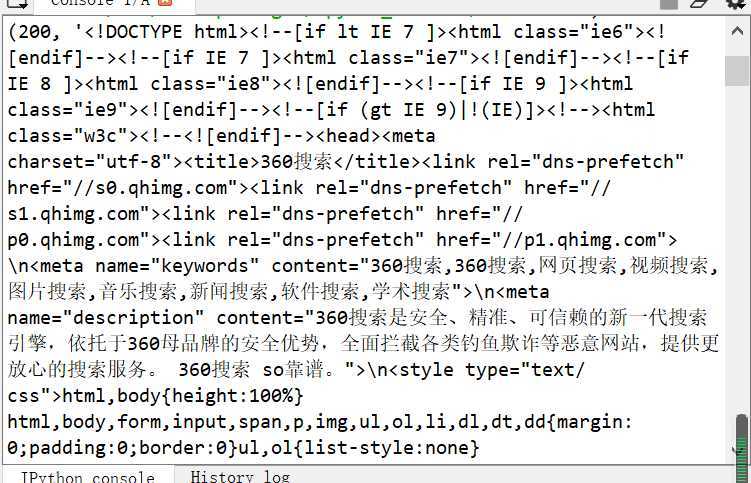
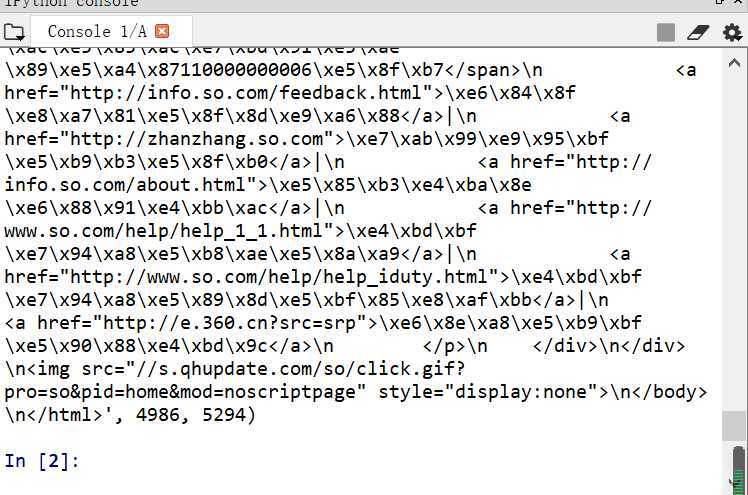
三、HTML页面
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title>菜鸟教程(runoob.com)47</title> </head> <body> <h1>我的第一个标题</h1> <p id="first">我的第一个段落。</p > </body> <table border = "1"> <tr> <td> row 1,cell 1</td> <td> row 1,cell 2</td> </tr> <tr> <td> row 2,cell 1</td> <td> row 2,cell 2</td> </tr> </table> </html>
运行结果:

四、爬虫大学排名
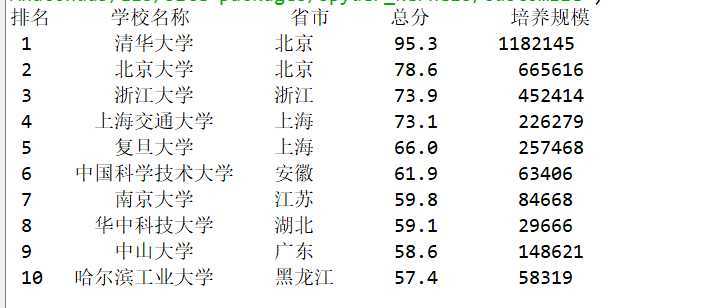
import requests from bs4 import BeautifulSoup allUniv = [] def getHTMLText(url): try: r = requests.get(url,timeout=30) r.raise_for_status() r.encoding = ‘utf-8‘ return r.text except: return "" def fillUnivList(soup): data = soup.find_all(‘tr‘) for tr in data: ltd = tr.find_all(‘td‘) if len(ltd) == 0: continue singleUniv = [] for td in ltd: singleUniv.append(td.string) allUniv.append(singleUniv) def printUnivList(num): print("{1:^2}{2:{0}^10}{3:{0}^6}{4:{0}^4}{5:{0}^10}".format(chr(12288),"排名","学校名称","省市","总分","培养规模")) for i in range(num): u = allUniv[i] print("{1:^4}{2:{0}^10}{3:{0}^5}{4:{0}^8.1f}{5:{0}^10}".format(chr(12288),u[0],u[1],u[2],eval(u[3]),u[6])) def main(num): url = "http://www.zuihaodaxue.com/zuihaodaxuepaiming2018.html" html = getHTMLText(url) soup = BeautifulSoup(html,"html.parser") fillUnivList(soup) printUnivList(num) main(10)
运行结果:
原文:https://www.cnblogs.com/ruanmh/p/12884243.html