在线正则表达式解析:https://regexper.com/
正则表达式在线测试:https://regex101.com/
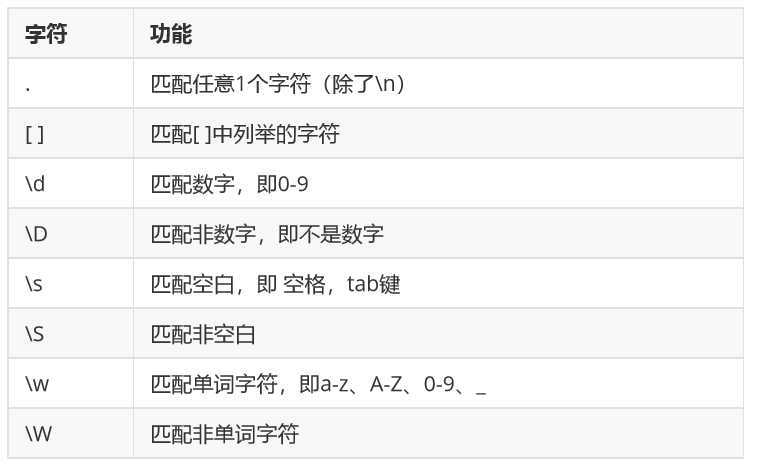

\ba\w*\b匹配以字母a开头的单词-先是某个单词开始处(\b),然后是字母a,然后是任意数量的字母或数字(\w*),最后是单词结束处(\b)。
\d+匹配1个或更多连续的数字。这里的+是和*类似的特殊代码,不同的是*代表重复任意次(可能是0次),而+则代表重复1次或更多次。
\b\w{6}\b 匹配刚好6个字母/数字的单词
例如:deerchao\.cn匹配deerchao.cn,c:\\windows匹配c:\windows,2\^8匹配2^8(通常这是2的8次方的书写方式)。
Windows\d+匹配Windows后面跟1个或更多数字
13\d{9}匹配以13后面跟9个数字(中国的手机号)
^\w+匹配一行的第一个单词(或整个字符串的第一个单词,具体代表哪个意思得看选项设置)
例子:\S+代表不包含空白符的字符串。
<a[^>]+>代表用尖括号括起来的以a开头的字符串。
0\d{2}-\d{8}|0\d{3}-\d{7}这个表达式能匹配两种以连字号分隔的电话号码:一种是三位区号,8位本地号(如010-12345678),一种是4位区号,7位本地号(0376-2233445)。
\(0\d{2}\)[- ]?\d{8}|0\d{2}[- ]?\d{8}这个表达式匹配3位区号的电话号码,其中区号可以用小括号括起来,也可以不用,区号与本地号间可以用连字号或空格间隔,也可以没有间隔。你可以试试用替换|把这个表达式扩展成也支持4位区号的。
\d{5}-\d{4}|\d{5}这个表达式用于匹配美国的邮政编码。美国邮编的规则是5位数字,或者用连字号间隔的9位数字。之所以要给出这个例子是因为它能说明一个问题:使用替换时,顺序是很重要的。如果你把它改成\d{5}|\d{5}-\d{4}的话,那么就只会匹配5位的邮编(以及9位邮编的前5位)。原因是匹配替换时,将会从左到右地测试每个条件,如果满足了某个条件的话,就不会去管其它的替换条件了。
(\d{1,3}\.){3}\d{1,3}是一个简单的IP地址匹配表达式--- >> 符类来描述一个正确的IP地址:((2[0-4]\d|25[0-5]|[01]?\d\d?)\.){3}(2[0-4]\d|25[0-5]|[01]?\d\d?)
# 系统自带的re模块实现正则 import re # 正则表达式& 创建待匹配的字符串 src_str = "python is very best ,bestttt" #正则表达式,往往在python中,需要在前面加上r # 默认为贪婪模式匹配,尽量多匹配 #re_str =r".+best" # 匹配第一个就行 re_str = r".+?best" #进行匹配 #match # 只能从头开始匹配 # 如果匹配不上,那就返回None,能匹配上,那么会返回Match的匹配对象 result = re.match(re_str,src_str) # 可以使用match对象中的group()方法获取返回值 result.group() pass #从头开始查找,满足要求的内容就返回 #search #从头开始查找,找到所有满足正则表达式条件的所有内容返回,返回列表 #findall #从头开始查找,找到所有满足正则表达式条件的所有内容返回迭代器 #finditer
原文:https://www.cnblogs.com/shishibuwan/p/12885677.html