在使用机器学习模型对数据进行训练的时候,需要考虑数据量和数据维度,在很多情况下并不是需要大量的数据和大量的数据维度,这样会造成机器学习模型运行慢,且消耗硬件设备。除此之外,在数据维度较大的情况下,还存在”维度灾难“的问题。在本篇博客里不对数据质量的判定,以及数据的增删做详细的介绍,只介绍对于数据的降维方法。
在开展特征工程时,数据的降维方法思想上有两种,一种是例如主成分分析方法(PCA)破坏数据原有的结构从而提取数据的主要特征,另一种是对数据进行相关性分析,按照一定的法则来对数据的属性进行取舍达到降维的目的。
在实际的工程问题中,由仪器设备采集到的数据具有很重要的意义,如果不是万不得已在进行建模的时候不建议破坏数据原有的结构,因为采集到的数据本身就具有很重要的物理意义与研究价值,提取出主要特征后会破坏原有数据的信息。因此在篇中介绍在实际的工程应用中使用相关性分析方法进行数据的降维。
相关性分析方法主要考量的是两组数据之间的相关性,以一种指标来判定,看看数据中的哪些属性与目标数据的相关性较强,从而做出保留,哪些较弱,进行剔除。
相关性分析方法也分为线性相关性分析与非线性相关性分析两种,分别应用于不同的场合。
一、线性相关性分析
1.数据可视化方法:
数据可视化方法在某些情况下可以简单且直观的判定数据之间的相关性,但是无法很好的展现出数据之间的关系。
2.皮尔逊相关性分析(Pearsion)(还有斯皮尔曼,原理与皮尔逊接近)
皮尔逊相关性分析的数学公式如下:
求两变量x和y之间的相关性:

对于结果的分析与判断:
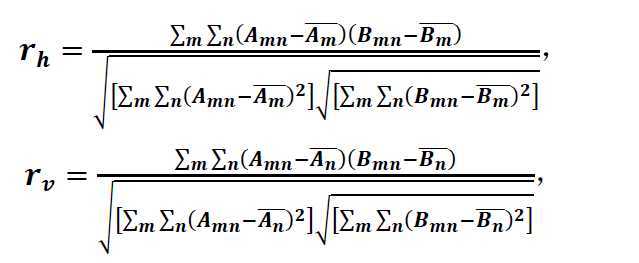
其中rh代表水平方向上的相关性,rv代表竖直方向上的相关性。在公式中A和B有着相同的尺寸,![]() 是矩阵A在行方向上的平均值,
是矩阵A在行方向上的平均值, ![]() 是矩阵A在列方向上的平均值,同理,
是矩阵A在列方向上的平均值,同理, ![]() 是矩阵 B在行方向上的平均值,
是矩阵 B在行方向上的平均值, ![]() 是矩阵B在列方向上的平均值。 rh和rv的取值范围均是从-1到+1,并且rh和rv的绝对值越大则代表相关性越强,同时相关性的判定标准与皮尔逊相关性分析一致。
是矩阵B在列方向上的平均值。 rh和rv的取值范围均是从-1到+1,并且rh和rv的绝对值越大则代表相关性越强,同时相关性的判定标准与皮尔逊相关性分析一致。
二、非线性相关性分析
1.灰色关联分析
灰色关联分析适用于探究非线性相关性。灰色关联分析是指对一个系统发展变化态势的定量描述和比较的方法,其基本思想是通过确定参考数据列和若干个比较数据列的几何形状相似程度来判断其联系是否紧密,它反映了曲线间的关联程度。
灰色关联分析的计算思路如下:
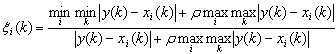
通常取ρ=0.5此时的分辨效果较好,按照相关性的大小可以得知关联的程度。
2.最大信息系数(Maximal Information Coefficient,MIC)
最大信息系数是一种现代的相关性分析方法,该方法可以考察两个变量(大量数据,通常数据量在500条以上)之间的线性关系和非线性关系。
最大信息系数的思路如下:
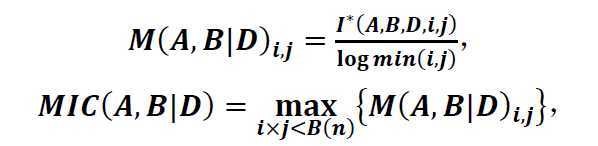

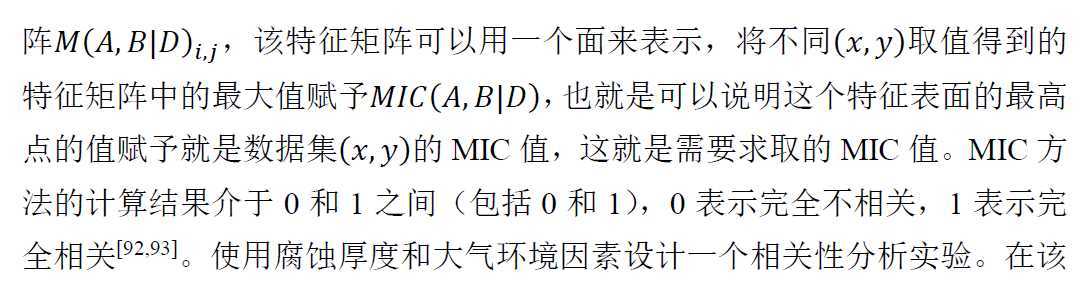
程序代码:
1.皮尔逊相关性分析:
function coeff = myPearson(X , Y)
% 本函数实现了皮尔逊相关系数的计算操作
%
% 输入:
% X:输入的数值序列
% Y:输入的数值序列
%
% 输出:
% coeff:两个输入数值序列X,Y的相关系数
%
if length(X) ~= length(Y)
error(‘两个数值数列的维数不相等‘);
return;
end
fenzi = sum(X .* Y) - (sum(X) * sum(Y)) / length(X);
fenmu = sqrt((sum(X .^2) - sum(X)^2 / length(X)) * (sum(Y .^2) - sum(Y)^2 / length(X)));
coeff = fenzi / fenmu;
end
2.二维相关性分析代码:
function [ r , rh , rv ] = TwoDimensionCorrelation( A , B )
%TwoDimensionCorrelation 此处显示有关此函数的摘要
% 此处显示详细说明
%% 输入矩阵
[m,n] = size(A);
[m1,n1] = size(B);
disp(‘输入矩阵特征:‘);
disp(m);
disp(n);
%% 判断矩阵的维度是否相同
if m~=m1 || n~=n1
disp(‘Hava the wrong inputs!‘);
end
%% 求矩阵的平均
A1 = mean(A(:)); %全部平均
A2 = mean(A,2); %按行平均
A3 = mean(A,1); %按列平均
B1 = mean(B(:)); %全部平均
B2 = mean(B,2); %按行平均
B3 = mean(B,1); %按列平均
%% 与运算有关的部分
a = 0; %与A1和B1有关
b = 0; %与A2和B2有关
c = 0; %与A3和B3有关
d = 0; %与r分母有关
e = 0; %与r分母有关
f = 0; %与rh分母有关
g = 0; %与rh分母有关
h = 0; %与rv分母有关
k = 0; %与rv分母有关
for i = 1:m
for j = 1:n
sum1 = (A(i,j) - A1)*(B(i,j) - B1); %r分子
sum2 = (A(i,j) - A2(i,:))*(B(i,j) - B2(i,:)); %rh分子
sum3 = (A(i,j) - A3(:,j))*(B(i,j) - B3(:,j)); %rv分子
sum4 = (A(i,j) - A1)^2; %r分母
sum5 = (B(i,j) - B1)^2; %r分母
sum6 = (A(i,j) - A2(i,:))^2; %rh分母
sum7 = (B(i,j) - B2(i,:))^2; %rh分母
sum8 = (A(i,j) - A3(:,j))^2; %rv分母
sum9 = (B(i,j) - B3(:,j))^2; %rv分母
a = a + sum1;
b = b + sum2;
c = c + sum3;
d = d + sum4;
e = e + sum5;
f = f + sum6;
g = g + sum7;
h = h + sum8;
k = k + sum9;
end
end
disp(‘部分计算值:‘)
disp(a);
disp(d);
disp(e);
%% 求r、rh和rv
r = a/(sqrt(d*e)); %r
rh = b/(sqrt(f*g)); %rh
rv = c/(sqrt(h*k)); %rv
3.灰色关联分析代码:
clc;
close;
clear all;
x=xlsread(‘data.xlsx‘);
x=x(:,2:end)‘;
column_num=size(x,2);
index_num=size(x,1);
% 1、数据均值化处理
x_mean=mean(x,2);
for i = 1:index_num
x(i,:) = x(i,:)/x_mean(i,1);
end
% 2、提取参考队列和比较队列
ck=x(1,:)
cp=x(2:end,:)
cp_index_num=size(cp,1);
%比较队列与参考队列相减
for j = 1:cp_index_num
t(j,:)=cp(j,:)-ck;
end
%求最大差和最小差
mmax=max(max(abs(t)))
mmin=min(min(abs(t)))
rho=0.5;
%3、求关联系数
ksi=((mmin+rho*mmax)./(abs(t)+rho*mmax))
%4、求关联度
ksi_column_num=size(ksi,2);
r=sum(ksi,2)/ksi_column_num;
%5、关联度排序
[rs,rind]=sort(r,‘descend‘);
4.最大信息系数:
需要安装包,参照https://minepy.readthedocs.io/en/latest/index.html#
机器学习案例三:数据降维与相关性分析(皮尔逊(Pearson),二维相关性分析(TDC),灰色关联分析,最大信息系数(MIC))
原文:https://www.cnblogs.com/zhuozige/p/12891600.html