朴素贝叶斯(Naive Bayesian, NB)
对于给定的训练集,首先基于特征条件独立学习输入、输出的联合概率分布 P(X, Y),然后基于此模型,对给定的输入 x ,利用贝叶斯定理求出后验概率最大的输出 y
假设P(X, Y)独立分布,通过训练集合学习联合概率分布 P(X, Y)
根据上面的等式可得贝叶斯理论的一般形式
分母是根据全概率公式得到
因此,朴素贝叶斯可以表示为:
为了简化计算,可以将相同的分母去掉
优点:实现简单,学习与预测的效率都很高
缺点:分类的性能不一定很高
逻辑回归(Logistic Regression, lR)
一种对数线性模型,它的输出是一个概率,而不是一个确切的类别
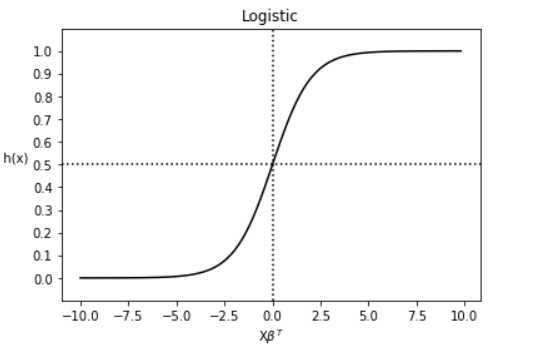
逻辑斯蒂函数:
图像:
对于给定数据集,应用极大似然估计方法估计模型参数
优点:实现简单、分类时计算量小、速度快、存储资源低等
缺点:容易欠拟合、准确率不高等
支持向量机(Support Vector Machine, SVM)
在特征空间中寻找到一个尽可能将两个数据集合分开的超平面(hyper-plane)
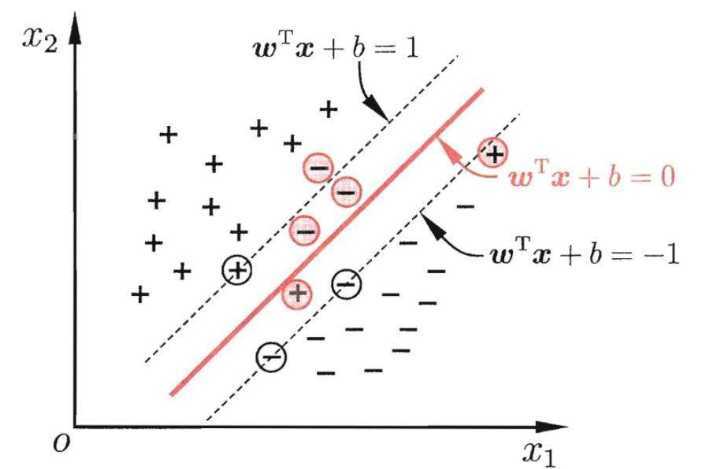
对于线性不可分的问题,需要引入核函数,将问题转换到高维空间中
优点:可用于线性/非线性分类,也可以用于回归;低泛化误差;容易解释;计算复杂度低;推导过程优美
缺点:对参数和核函数的选择敏感
数据集分为:ham_data.txt 和 Spam.data.txt , 对应为 正常邮件和垃圾邮件
其中每行代表着一个邮件
主要过程为:
代码放在 GitHub 上了
https://github.com/CuveeFer/my-nlp
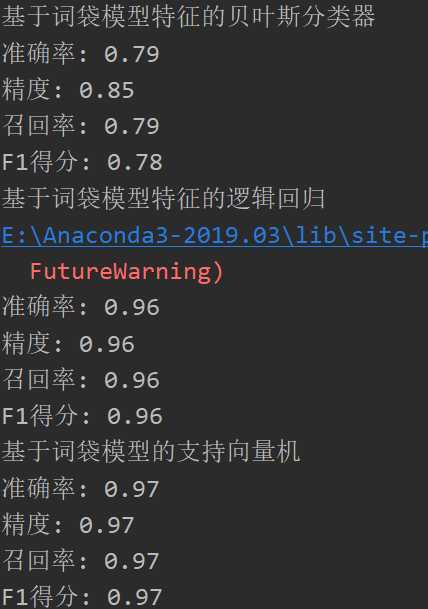
结果:

原文:https://www.cnblogs.com/alivinfer/p/12892147.html