1、要爬取的网站 : http://www.zuihaodaxue.com/zuihaodaxuepaiming2015_0.html
2、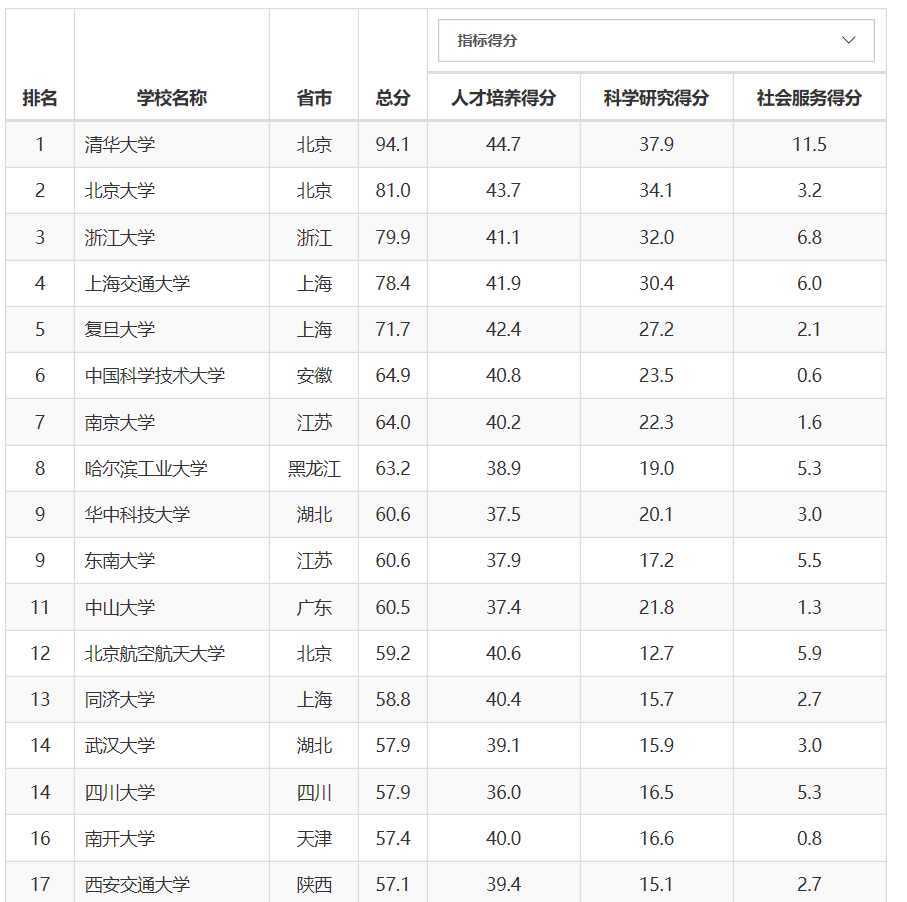
3代码如下:
1 import requests 2 from bs4 import BeautifulSoup 3 import bs4 4 info = []#用来存放爬取信息 5 url = "http://www.zuihaodaxue.com/zuihaodaxuepaiming2015_0.html" 6 try: 7 r=requests.get(url,timeout=100) 8 r.raise_for_status()#检查链接是否正确正常返回200,异常返回404 9 r.encoding=r.apparent_encoding 10 soup = BeautifulSoup(r.text,"html.parser")#r.text,网页的代码text形式返回,用beautifulsoup解析text,解析的方式是html.parse 11 for tr in soup.find("tbody").children:#遍历tbody标签里的所有子标签 12 if isinstance(tr,bs4.element.Tag): 13 tds=tr.find_all("td") #找到每一行的td标签 14 #tds[0].string不能写成tds[0].String,否则会返回None 15 info.append([tds[0].string,tds[1].string,tds[2].string,tds[3].string,tds[4].string,tds[5].string,tds[6].string]) 16 print("{0:^10}\t{1:^10}\t{2:^10}\t{3:^10}\t{4:^10}\t{5:^10}\t{6:^2}".format("排名","学校名称","省市","总分","人才培养得分","科学研究得分","社会服务得分",chr(12288))) 17 for i in range(50):#爬取排名前五十 18 print("{0:^10}\t{1:^10}\t{2:^10}\t{3:^10}\t{4:^10}\t{5:^10}\t{6:^2}".format(info[i][0],info[i][1],info[i][2],info[i][3],info[i][4],info[i][5],info[i][6],chr(12288))) 19 except Exception as e : #捕获异常,网址是否正常,后期调试 20 print(e) 21
结果如下
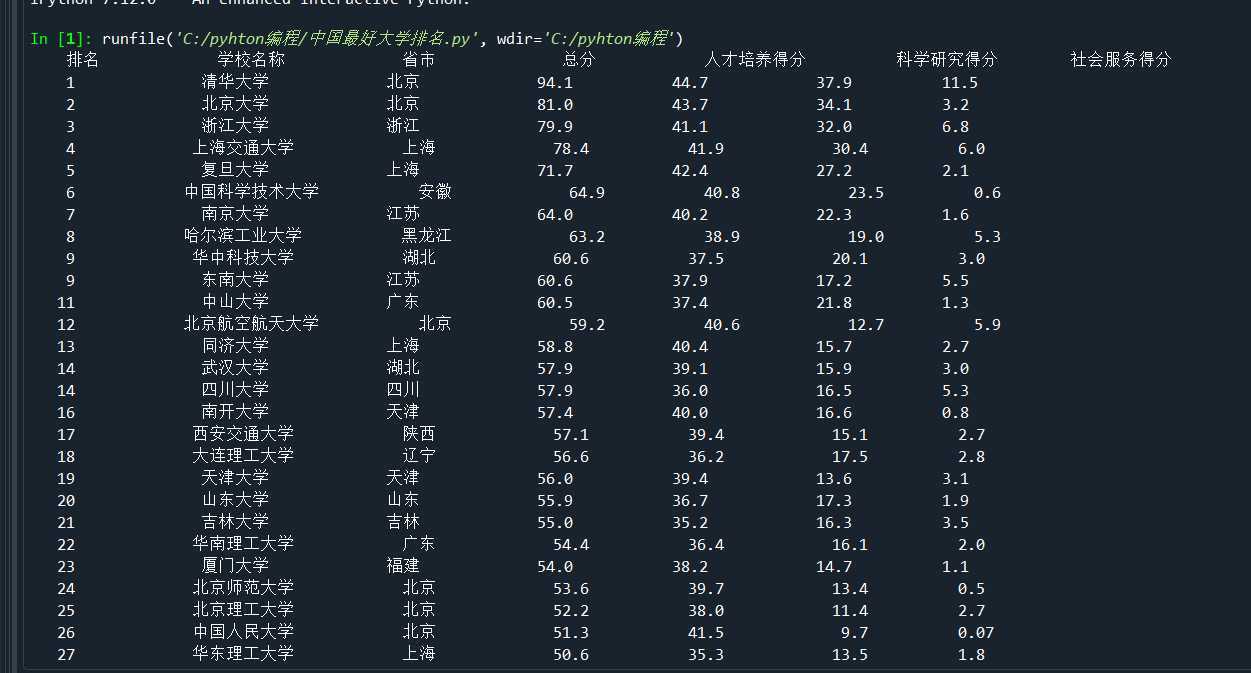
内容太多,没有全部截出来。。。。
原文:https://www.cnblogs.com/qinlai/p/12902134.html