学海教育面试题
一、笔试题
1、spark代码运行流程。(源码级别)
答:1)、application启动之后,会在本地启动一个Driver进程,用于控制整个流程。
2)、首先初始化spark Context,spark Context会构建出DAG有向无环图,DAGScheduler根据宽窄依赖切分stage,每个stage根据分区数生成相应的task,将每个stage的task放入相应的set的集合,将taskSet提交到TaskScheduler,TaskScheduler向spark申请task、
3)、Task Scheduler将Task发放给Executor运行同时SparkContext将应用程序代码发放给Executor。
4)、Task在Executor上运行,运行完毕释放所有资源。
2、hdfs上传文件流程
答:1)、客户端向NameNode发送上传请求
2)、Namenode会进行一系列的检查
①、检查文件是否已经存在
②、父目录是否存在
③、是否有上传权限
④、如果检查没有问题,会返回允许上传的响应
3)、客户端发起真正的上传请求,包含重要的信息,文件的大小,长度等等
4)、namenode向客户端返回上传的节点。
①、节点数=上传文件大小/默认块大小128M*副本数3
②、返回的节点根据机架感知策略返回,一般是跟客户端相同的机器节点+相同机架节点+不同机架的节点
5)、客户端开始准备上传
6)、客户端对文件进行切块
7)、客户端上传第一个数据块
8)、客户端构建第一个数据块的pipline
①、客户端----节点1----节点2----节点3
②、同时开启一个阻塞服务,用来检测上传文件和源文件是否一样,等待客户端上传成功的响应
9)、客户端开始真正上传数据,最终上传成功之后,给客户端响应。
10)、关闭第一个数据块的pipline
11)、开始上传第二个数据块,然后执行8/9/10
12)、当所有的数据块上传完成之后,客户端会向namenode反馈
3、讲述一下MapReduce的流程
答:map阶段:
shuffle阶段:
reduce阶段:
4、介绍一下zookeeper,它的选举机制和集群的搭建
5、spark streming在实时处理会发生什么故障,如何停止,解决。

6、离线处理遇到什么问题?如何处理的?
7、hadoop生态圈的认识和理解
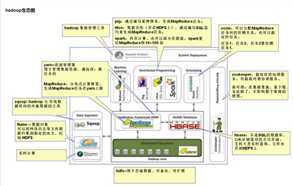
8、yarn是干什么的,在生态圈中主要扮演什么角色?
9、hive的udf、udaf、udtf的区别
udf:一进一出
udaf:多进一出,聚合函数(min/max/count/)
udtf:一进多出,later view explore
10、想看一个文件多少行,用一个linux命令
wc -l filename
11、谈谈对jvm的理解
12、你们的数据仓库的架构是什么样子的?
二、面试问题
1、什么是事实表,什么是维度表?
2、hive数仓与传统的数据库的区别?
3、数仓规范?
4、hashMap和hashTable的区别?
5、什么是线程安全?
6、项目中的需求?
7、写过udf吗?主要处理什么问题?
8、集群是云环境还是自己搭建的?
9、集群中调过什么参数?
10、增量数据是怎么处理的?
11、什么是拉链表?
博纳格面试题:
1、java中的时间类型在1.6之前有个问题,知道是什么问题吗?在1.8版本中,时间类型在那个包下?
2、java的多线程?
3、java设计模式有哪些?单利模式讲一下?
4、scala中的隐式转换用过没有?有没有自己写过隐式转换?
5、spark SQL 和hiveSQL有什么区别?
6、hadoop的二次排序讲一下?
7、spark Streaming消费kafka数据的容错机制?
8、hive数据是怎么加载到ES的,直接加载还是写程序?
9、数据建模说一下
10、元数据管理说一下
11、sqoop加载数据的脚本和airflow调度脚本,是手写的还是配置的?

原文:https://www.cnblogs.com/mayucheng123/p/12919240.html