JML是一种行为接口规格语言,从我个人使用的感受来看,它主要下列用处。
int max(),我们会说这个方法返回最大的数,但是如果我们用JML描述,我们就会写成/* @ ensures (\result == a) && (\forall int i; 0<=i && i<list.length; list[i]<=a)&&(\exists int i; 0<=i&&i<list.length; list[i] == a);
@ */
显然后者揭示出了实际上的逻辑结构,当然,实现的时候不一定要按照这种方法去实现。
针对现有的代码,书写规格,从而提高代码的可维护性。
可以根据jml展开构造更为全面的测试用例,对于进行单元测试有指导作用。
实现自动化系统化的测试,规格化的JML不仅有利于开发人员理解方法,同时也让程序自动生成测试样例,自动化测试成为了可能,从而避免人类思维的死角。当然了目前JML应用工具功能还有限,只能针对比较简单的方法进行自动测试。
JML的表达式是对Java表达式的扩展,新增了一些操作符和原子表达式。表达式包含原子表达式,量化表达式,集合表达式。这些表达式构成了JML的基础语法,所有的规格都是通过表达式书写的。
方法规格的核心内容包括三个方面,前置条件、后置条件和副作用约定。其中前置条件是对方法输入参数的限制,如果不满足前置条件,方法执行结果不可预测,或者说不保证方法执行结果的正确性;后置条件是对方法执行结果的限制,如果执行结果满足后置条件,则表示方法执行正确,否则执行错误。副作用指方法在执行过程中对输入对象或this对象进行了修改。
类型规格指针对Java程序中定义的数据类型所设计的限制规则,包含不变式和状态变化约束,它们和方法规格一起,决定了数据类型在程序运行时的bug。
目前JML的应用工具还不成熟,实际应用时总会出现各种各样的错误,我个人最终只用了OpenJML,其他应用工具由于各种原因不明的bug不能够运行。
OpenJML主要有两个作用,第一个检测JML的语法是否正确,另一个是利用JML自动生成测试用例,实现自动化测试。
我是用win10的linux子系统来使用jml的,也可以把OpenJML作为一个插件导入IDEA中。
我们来看一个简单的例子:
public class HelloWorld {
public static void main(String[] args) {
}
/*@
@ ensures \result = a+b;
@*/
int sum(int a,int b){
return a+b;
}
}
在linux中输入openjml HelloWorld.java
我们会看到输出为

很明显发现了错误,我们把原本的jml进行修改
public class HelloWorld {
public static void main(String[] args) {
}
/*@
@ ensures \result == a+b;
@*/
int sum(int a,int b){
return a+b;
}
}
再次检测后就能够通过OpenJML的检测了。
接下来我们用jml进行一下程序功能的测试
输入命令
openjml -esc -verboseness=3 HelloWorld.java
我们会看到大量输出,这里截取一部分解释下
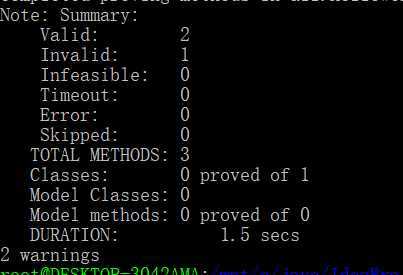
比较好理解,就是说测试了3个,通过了2个,有一个没有通过。如果我们去看前面的输出,我们会看到它构造的测试样例,比如

可见,OpenJML比较倾向于对于边界进行测试。
这里我只用了一个很简单的程序做例子,一方面是出于方便,另一方面是因为OpenJML的功能还很不完善,除了对于jdk的兼容性差,没有图形化的操作界面等缺陷外,对于一些复杂度较高的方法,OpenJML并不能实现真正的自动化测试,比如我们作业中遇到的StrongLinked,因此即使使用过OpenJML测试,我们也必须自己构造测试样例进行单元测试。
使用JMLunitNG进行测试
截取部分输出为
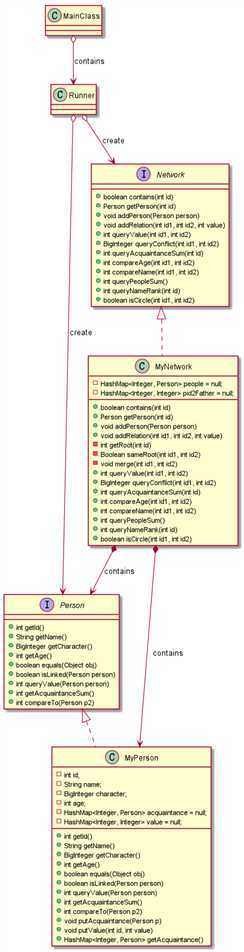
采用的就是基本架构
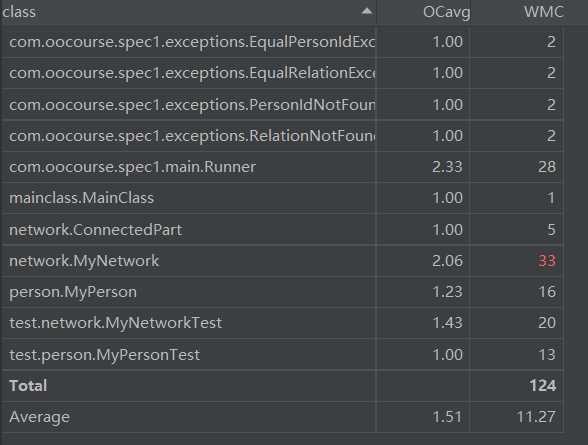
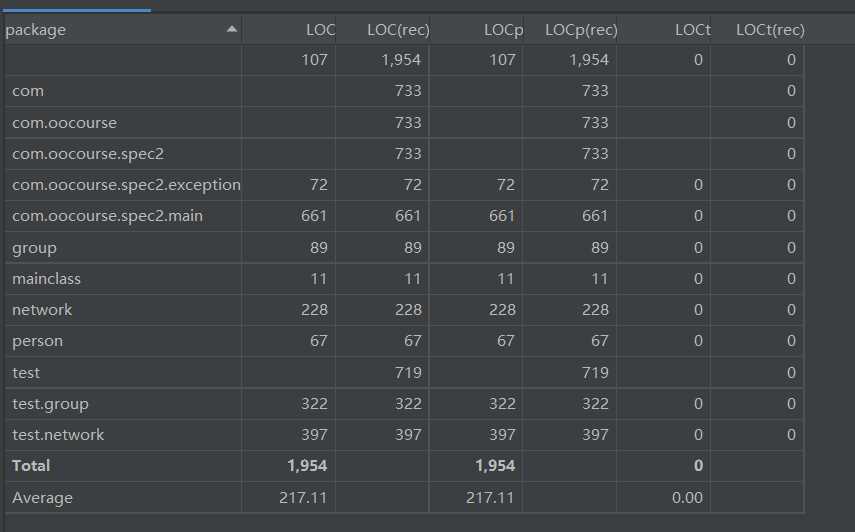
度量分析:
行数

复杂度
采用的是基本架构
UML图:
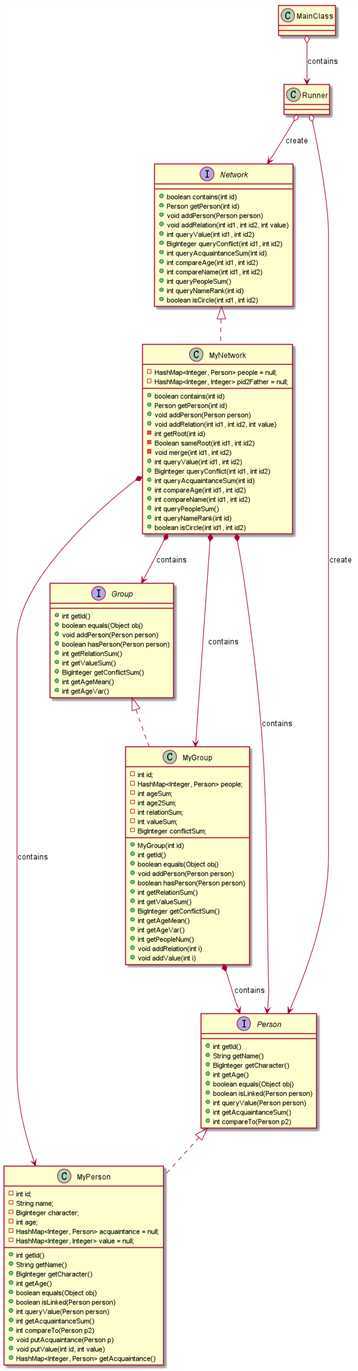
度量分析:
行数
复杂度
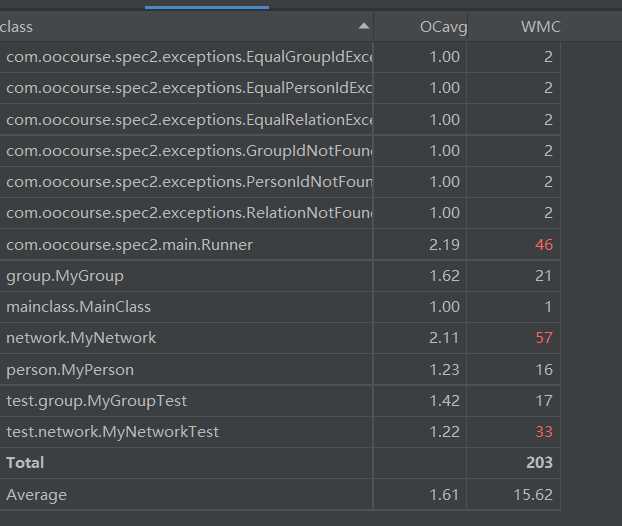
增加了一个EdgeData类来实现迪杰斯特拉算法。
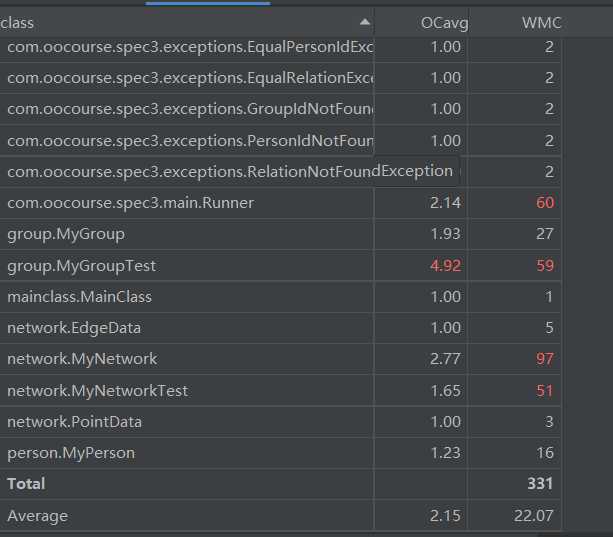
类图:
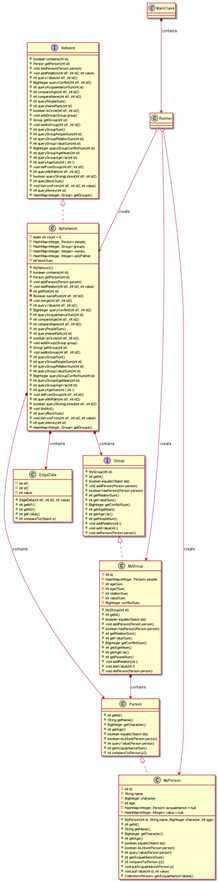
度量分析:
行数:
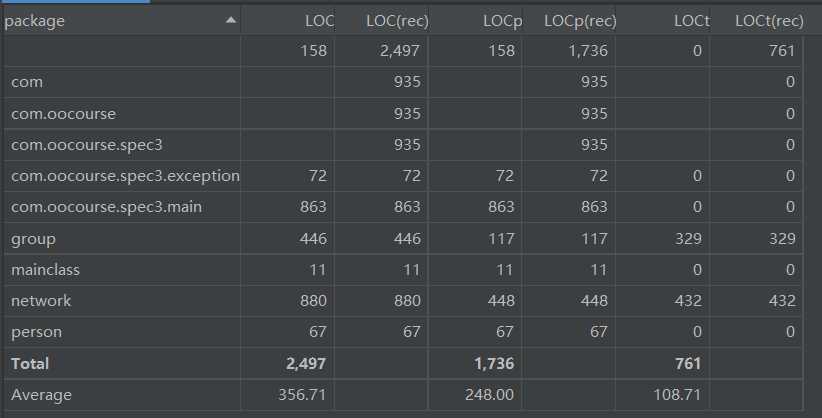
复杂度:
前两次作业没有什么严重bug
主要说一下第三次作业,有一个bug,截止到我写这篇博客,仍然没有妥善的解决。这个bug属于stronglink方法,我使用双连通分量的算法来实现这个方法。我们对于一个图,先生成它的dfs生成树。并且标注每个点是第几次读取到的。
举个例子
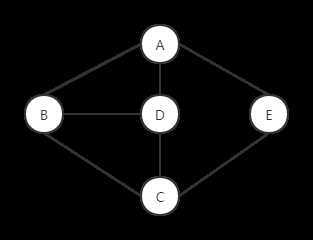
它的dfs生成树为
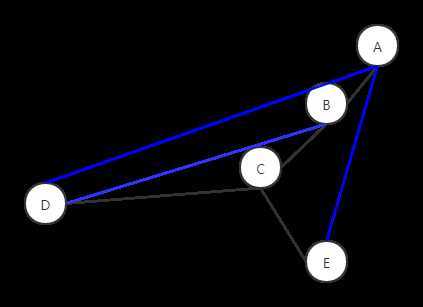
黑色的线时搜索路径,蓝色的线不在dfs树中,但是却在原图中,我们称之为回归路径
接下来,对每一个点,我们标注上它是第几次被dfs树搜索到的,同时标志它通过搜索路径和至多一个回归路径能够到达的最早的点
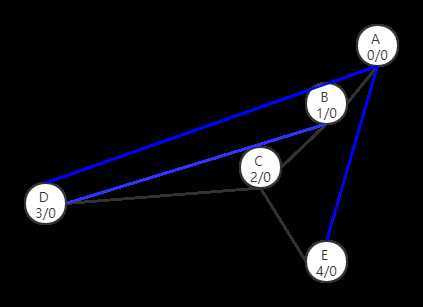
我们发现,所有的点通过一个回归路径都能够返回0号点。
这样就说明这个图是一个双连通分量,是任意两个点之间都有两条通路。
那么bug在哪里呢?
我们看下面的图
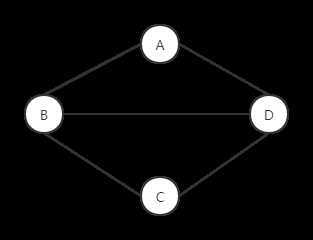
对于这个图按照abcd,生成dfs生成树,我们会得到
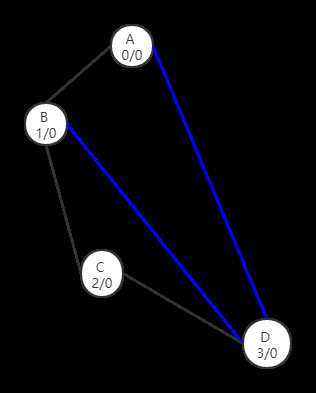
整个图是一个双连通分量,也符合我们的直觉,确实是个双连通分量。
但是,如果我们把图的dfs顺序变成abdc,就会生出的dfs树
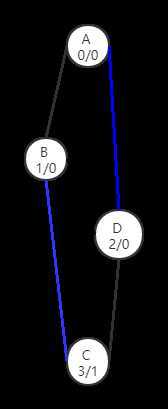
这样这图中点C能够到达的最早点是1号点(点B),C不再是原本的双连通分量中的点了。
这显然是一个bug,它说明我们判断一个图是不是双连通分量,和dfs的顺序有很深的联系。
同样的如果我们不用双连通分量,而是采用一次dfs找到第一条路径,去掉第一条路径后再次dfs找到第二条路径的方法,
只要我们第一次找到的路径为图中红色路径,那么我们也无法找到应该存在的另一条路径。
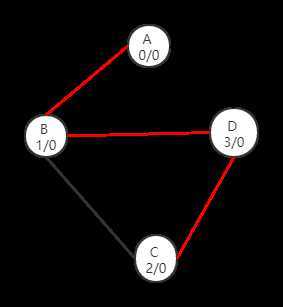
因为在进行第二次dfs时,我们的图变成了
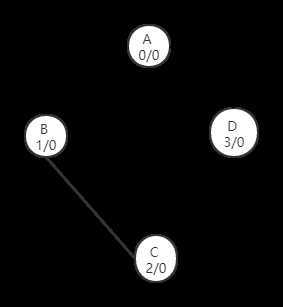
即使我们规定dfs时应该尽量避免横向移动————也就是说,如果一个点和当前的点的父节点连接,那么就最后在遍历它————只要把图稍微改变一点,我们一样会出bug。
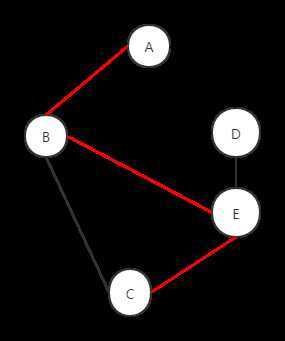
这个问题,我目前还没有解决的办法。
JML极大地降低了编程的难度,避免了对方法理解的歧义,也有利于更好的开展测试。编写jml的过程本身,就是进行架构设计,抽象逻辑的过程,当然编写jml本身也有一定难度,对与一些复杂的方法,想要抽象出jml本身就比较困难。
在实现jml的时候,按照jml本身来实现往往不是一个好的策略,我们要根据需求设计新的算法和数据结构才能取得一个比较好的性能,但是同时我们也要保证完成规格的要求,这样能保证正确性。
原文:https://www.cnblogs.com/riyuejiuzhao/p/12925821.html