【说在前面】本人博客新手一枚,象牙塔的老白,职业场的小白。以下内容仅为个人见解,欢迎批评指正,不喜勿喷![认真看图][认真看图]
【补充说明】异常检测,又称离群点检测,有着广泛应用。例如金融反欺诈、工业损毁检测、电网窃电行为等!
关于时间序列分析的介绍,欢迎浏览我的另一篇博客:时间序列分析中预测类问题下的建模方案,这里不再赘述。
适合数据呈周期性规律的场景中。例如:
当上述比值超过一定阈值,则判定出现异常。

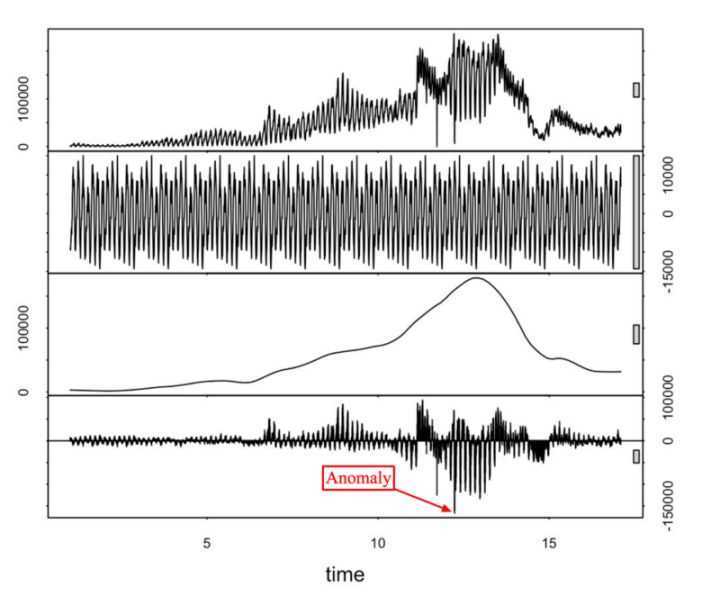
移动平均MA是一种分析时间序列的常用工具,它可过滤高频噪声和检测异常点。
当然,还有ARMA、ARIMA、SARIMA等适用于时间序列分析的统计学模型,可以预测信号并指出其中的异常值。
STL是一种单维度时间指标异常检测算法。大致思路是:
(1)先将指标做STL时序分解,得到seasonal、trend、residual成分。
(2)用ESD算法对trend+residual成分进行异常检测。
(3)为增强对异常点的鲁棒性,将ESD算法中的mean、std等统计量用median, MAD替换。
(4)异常分输出:abnorm_score = (value - median)/MAD,负分表示异常下跌,正分表示异常上升。
当然,还有其他的时间序列分解算法,例如STL、X12-ARIMA、STAMP等。
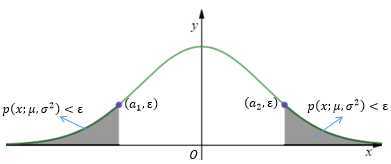
一般会构建一个概率分布模型,并计算对象符合该模型的概率,把具有低概率的对象视为异常点。
还记得不,机器学习特征工程中的RobustScaler方法,在做数据特征值缩放的时候,利用数据特征的分位数分布,将数据根据分位数划分为多段,只取中间段来做缩放(例如只取25%分位数到75%分位数的数据做缩放等),这样减小了异常数据的影响。
在正态分布的假设下,如果有一个新样本x,当x的正态分布值小于某个阈值时,就可以认为这个样本是异常的。
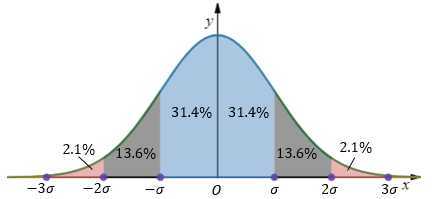
在正态分布中,μ-3σ<=x<=μ+3σ的区域包含了绝大部分数据,可以以此为参考,调整ε的值:
值得一提的是,如果有些特征不符合高斯分布,可以通过一些函数变换,使其符合高斯分布,再使用基于统计的方法。
可以直接对每个独立特征都进行单特征下的异常检测(参考1)。
可以通过以下函数判断一个样本是否是异常的:
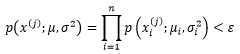
目的是设法根据训练集求得μ和σ,以得到一个确定的多元分正态布模型。具体来说,通过最大似然估计量可以得出下面的结论:
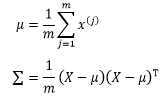
其中Σ是协方差对角矩阵,最终求得的多元正态分布模型可以写成:
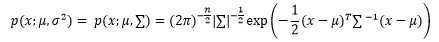
关于最大似然估计量、协方差矩阵和多元正态分布最大似然估计的具体推导过程,这里不详细介绍。
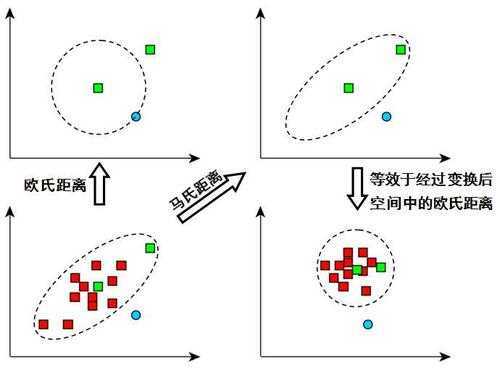
其中S为二元高斯分布的协方差矩阵,为所有数据对象的均值。Mahalanobis距离越大,数据对象偏离均值越大,也就越异常。
Grubbs‘ Test可理解为检验最大值、最小值偏离均值的程度是否为异常。
![]()
其中,O为观测值,E为期望值。
为了将Grubbs‘ Test扩展到k个异常值检测,需要在数据集中逐步删除与均值偏离最大的值(即最大值或最小值),同步更新对应的t分布临界值,检验原假设是否成立。基于此,Rosner提出了Grubbs‘ Test的泛化版ESD。
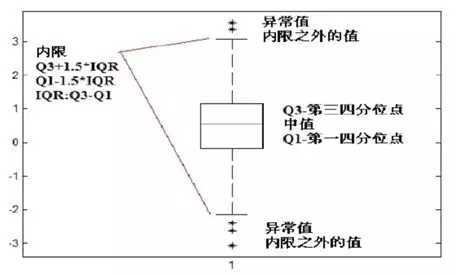
箱线图算法不需要数据服从特定分布。该方法需要先计算第一四分位数Q1(25%)和第三四分位数Q3(75%)。
令IQR=Q3-Q1,然后算出异常值边界点Q3+λIQR和Q1- λIQR,通常λ取1.5。
当然还有其他的统计方法,例如基于混合模型的异常检测方法(假设正常和异常数据分布不同,然后用G检验)等,这里不再展开。
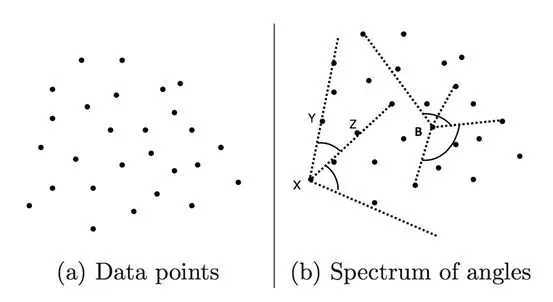
D是点集,则对于任意点,计算其K近邻的距离之和Dist(K,X)。Dist(K,X)越大的点越异常。
基于距离的方法中,阈值是一个固定值,属于全局性方法。但是有的数据集数据分布不均匀,有的地方比较稠密,有的地方比较稀疏,这就可能导致阈值难以确定。我们需要根据样本点的局部密度信息去判断异常情况。
基于密度的方法主要有LOF、COF、ODIN、MDEF、INFLO、LoOP、LOCI、aLOCI等,具体实现这里不具体介绍。
首先对于每一个数据点,找出它的K个近邻,然后计算LOF得分,得分越高越可能是异常点。
LOF是一个比值,分子是K个近邻的平均局部可达密度,分母是该数据点的局部可达密度。
LOF中计算距离是用的欧式距离,也是默认了数据是球状分布,而COF的局部密度是根据最短路径方法求出的,也叫做链式距离。
LOF容易将边界处的点判断为异常,INFLO在计算密度时,利用k近邻点和反向近邻集合,改善了LOF的这个缺点。
将LOF中计算密度的公式加了平方根,并假设近邻距离的分布符合正态分布。
关于聚类算法的介绍,欢迎浏览我的另一篇博客:机器学习中的聚类算法演变及学习笔记,这里不再赘述。
此类方法主要有三种假设,三种假设下有各自的方法。
主要方法:DBSCAN、SNN clustering、FindOut algorithm、WaveCluster Algorithm。
缺点:不能发现异常簇
主要方法:K-Means、Self-Organizing Maps(SOM)、GMM。
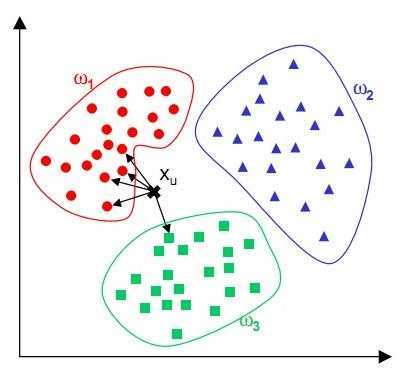
主要步骤:首先进行聚类,然后计算样例与其所属聚类中心的距离,计算其所属聚类的类内平均距离,用两者的比值衡量异常程度。
缺点:不能发现异常簇
主要方法:CBLOF、LDCOF、CMGOS。
主要步骤:首先进行聚类,然后启发式地将聚类簇分成大簇和小簇。
优点:考虑到了数据全局分布和局部分布的差异,可以发现异常簇
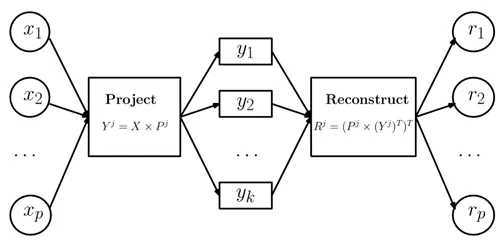
基于矩阵分解的异常点检测方法的主要思想是利用主成分分析(PCA)去寻找那些违反了数据之间相关性的异常点。
为了找到这些异常点,基于主成分分析的算法会把数据从原始空间投影到主成分空间,然后再从主成分空间投影回原始空间。
这是因为第一主成分反映了正常点的方差,最后一个主成分反映了异常点的方差。
即对比基准数据和待检测数据的某个特征的分布。
相对熵(KL散度)可以衡量两个随机分布之间的距离。
卡方检验通过检验统计量来比较期望结果和实际结果之间的差别,然后得出实际结果发生的概率。
检验统计量提供了一种期望值与观察值之间差异的度量办法,最后根据设定的显著性水平查找卡方概率表来判定。
该类方法假设我们用一个随机超平面来切割数据空间,每切一次便可以生成两个子空间。接着继续用一个随机超平面来切割每个子空间,循环下去,直到每个子空间里面只有一个数据点为止。
此类方法不受球形邻近的限制,可以划分任意形状的异常点。不同的方法区别主要在三个地方:特征的选取、分割点的选取和分类空间打标签的方案。此类方法主要包括iForest、SCiForest、RRCF。
此方法适用于异常点较少的情况,采用构造多个决策树的方式进行异常检测。
iForest只适合检测全局异常点,不适合检测局部异常点。


传统iForest方法在选择特征是随机选取的,SCiForest在选择特征时利用了方差。
传统iForest选择分割点后形成的分割超平面是平行于坐标轴的,SCiForest可以生成任意角度的分割超平面。
可以动态增删树种的节点,适用于流数据异常检测。
在无向图G中,若从顶点A到顶点B有路径相连,则称A和B是连通的。在图G中存在若干子图,其中每个子图中所有顶点之间都是连通的,但不同子图间不存在顶点连通,那么称图G的这些子图为最大连通子图。

标签传播图聚类算法是根据图的拓扑结构,进行子图的划分,使得子图内部节点的连接较多,子图之间的连接较少。
标签传播算法的基本思路是:节点的标签依赖其邻居节点的标签信息,影响程度由节点相似度决定,通过传播迭代更新达到稳定。
标签传播聚类的子图间可以有少量连接。适用场景:节点之间“高内聚低耦合”。

如图所示,用户在搜索引擎上有5个行为状态:页面请求(P),搜索(S),自然搜索结果(W),广告点击(O),翻页(N)。状态之间有转移概率,由若干行为状态组成的一条链可以看做一条马尔科夫链。
统计正常行为序列中任意两个相邻的状态,然后计算每个状态转移到其他任意状态的概率,得状态转移矩阵。针对每一个待检测用户行为序列,易得该序列的概率值,概率值越大,越像正常用户行为。

此类方法适用于标注的数据全都是正常数据,常用方法有one-class SVM、SVDD、AutoEncoder、GMM、Naïve Bayes等。
此类方法与无监督方法有些重合,因为无监督方法的基本假设就是数据集中正常数据远远多于异常数据。
利用核函数将数据映射到高维空间,寻找超平面使得数据和坐标原点间隔最大。
利用核函数将数据映射到高维空间,寻找尽可能小的超球体包裹住正常数据。
对正常数据进行训练Encoder和Decoder,进行异常检测时,如果Decoder出来的向量与原始向量差别很大,就认为是异常数据。
对正常数据进行高斯混合模型建模,最大似然估计参数。进行异常检测时,将其特征带入模型,可得出它属于正常数据的概率。
过程同高斯混合模型。
最直观的理解:利用生成对抗的思想,生成器从随机噪声中生成异常数据,判别器判别数据是生成的异常数据,还是原始的正常数据。
两者进行博弈,最终达到平衡。在异常检测过程中,对于给定数据,只需要利用判别器判别出是正常数据还是异常数据。
上述方法都是无监督方法,实现和理解相对简单。但是由于部分方法每次使用较少的特征,为了全方位拦截作弊,需要维护较多策略。
同时,上述部分方法组合多特征的效果取决于人工经验。而有监督模型能自动组合较多特征,具备更强的泛化能力。
关于机器学习算法的介绍,欢迎浏览我的另一篇博客:数据挖掘比赛/项目全流程介绍 ,这里不再赘述。
可以使用前面的无监督方法挖掘的作弊样本作为训练样本。如果作弊样本仍然较少,用SMOTE或者GAN生成作弊样本。
可以采用LR、SVM、GBDT、XGBOOST等机器学习算法进行回归,实现二分类,完成异常检测。
关于深度学习算法的介绍,欢迎浏览我的另一篇博客:深度学习中的序列模型演变及学习笔记,这里不再赘述。
关于深度学习组件的介绍,欢迎浏览我的另一篇博客:深度学习中的一些组件及使用技巧 ,这里不再赘述。
同样的,可以使用前面的无监督方法挖掘的作弊样本作为训练样本。如果作弊样本仍然较少,用SMOTE或者GAN生成作弊样本。
可以采用CNN、RNN、LSTM等深度学习模型及其融合进行回归,实现二分类,完成异常检测。
值得一提的是,其他随笔提到的很多深度学习模型,均适用于“异常检测”这个应用场景,细品!
举个例子,阿里的GEM模型实现了异构图网络在异常检测中的应用,采用图神经网络相关算法实现了“是否异常”的二分类。
同时,自然还有基于知识图谱、引入迁移学习、引入强化学习等新技术的推进。
随着信息流的不断发展,除了上文提到的时间序列数据、高维数据,目前有图像、视频、文本、日志等数据类型的异常检测方法。
可以使用Python异常检测工具库Pyod。这个工具库除了支持Sklearn上支持的模型外,还额外提供了很多模型。
本文参考了阿里巴巴的一篇文章:异常检测的N种方法,阿里工程师都盘出来了
如果您对人工智能算法感兴趣,欢迎浏览我的另一篇博客:人工智能新手入门学习路线和学习资源合集(含AI综述/python/机器学习/深度学习/tensorflow)、人工智能领域常用的开源框架和库(含机器学习/深度学习/强化学习/知识图谱/图神经网络)
如果你是计算机专业的应届毕业生,欢迎浏览我的另外一篇博客:如果你是一个计算机领域的应届生,你如何准备求职面试?
如果你是计算机专业的本科生,欢迎浏览我的另外一篇博客:如果你是一个计算机领域的本科生,你可以选择学习什么?
如果你是计算机专业的研究生,欢迎浏览我的另外一篇博客:如果你是一个计算机领域的研究生,你可以选择学习什么?
如果你对金融科技感兴趣,欢迎浏览我的另一篇博客:如果你想了解金融科技,不妨先了解金融科技有哪些可能?
之后博主将持续分享各大算法的学习思路和学习笔记:hello world: 我的博客写作思路
原文:https://www.cnblogs.com/zhengzhicong/p/12922836.html