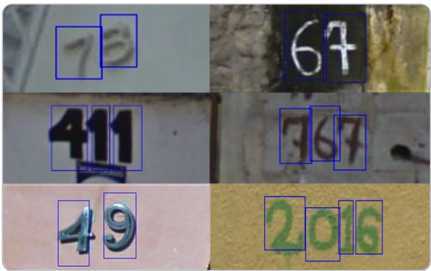
街景字符识别以计算机视觉中字符识别为背景,对真实场景下的字符进行预测识别。本篇主要对数据的理解,包括对数据的读取以及根据标签数据对字符进行分割
赛题数据源自Google街景图像中的门牌号数据集(The Street View House Numbers Dataset,SVHN),并根据一定方式采样得到此比赛数据集
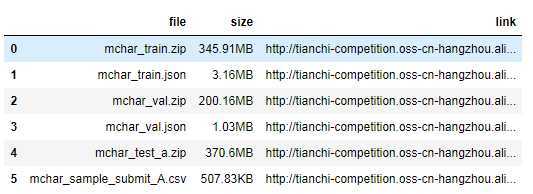
根据官网提供的数据地址,进行下载,解压
links = pd.read_csv(‘./mchar_data_list_0515.csv‘)
links
创建数据存储目录
dir_name = ‘dataset/‘
local_path = ‘./‘
if not os.path.exists(local_path + dir_name):
os.makedirs(dir_name)
下载数据并存入指定文件夹
参考:https://cn.python-requests.org/zh_CN/latest/user/quickstart.html#id3
但这里,没有指定每次写入的大小,程序会根据情况来决定
for i,link in enumerate(links[‘link‘]):
file_name = links[‘file‘][i]
file_path = local_path + dir_name + file_name
if os.path.exists(file_path):
response = requests.get(link,stream= True)
print(response.raw)
with open(file_path,‘wb‘) as f:
for chunk in response.iter_content():
f.write(chunk)
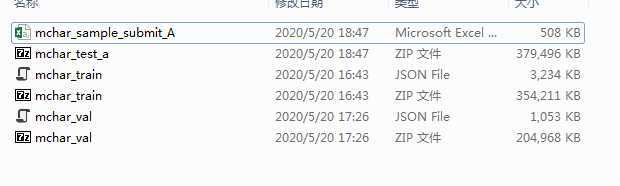
获取压缩文件名并存入列表中
zip_list=[]
list_dir = os.listdir(local_path+dir_name)
for list_name in list_dir:
if list_name.endswith(‘.zip‘):
zip_list.append(list_name)
print(zip_list)

解压
for zip_file in zip_list:
zip_path = local_path+dir_name+zip_file
if os.path.exists(zip_path):
zip_files = zipfile.ZipFile(zip_path)
zip_files.extractall(local_path+dir_name)
删除无用文件__MACOSX(该文件是上传者mac压缩文件时自动生成,类似图片封面的文件)
采用shutil.rmtree()可递归删除文件内的所有内容,python的文件操作
if os.path.exists(local_path+dir_name+‘__MACOSX‘):
print(‘存在‘)
shutil.rmtree(local_path+dir_name+‘__MACOSX‘)
在数据解压中发生个小插曲,当对"下载好的"数据进行解压时,总是出现
File is not a zip file,我就纳闷了,这怎么就不是.zip文件了??大大的问号,各种度,一开始以为是python中的压缩模块zipfile有问题,又是各种度,虽也查到了,但药不对症,但注意到zipfile是python的自带模块,那这不应该了,所以想着也许应该是数据的问题,结果发现,训练集数据大小竟然是0K,哎~,终于找到病因了,那就好办了,原来是数据没有下完的原因。
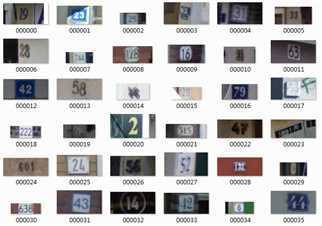
训练集中包括3W张照片,验证集中包括1W张照片,每张照片包括了颜色图像和其对应的编码类别和具体位置;此外,官方为不保证比赛的公平性,测试集A包括4W张照片,测试集B包括4W张照片。
对于训练数据每张图片都给出了对应的编码标签和具体的字符框的位置(训练集、测试集和验证集都给出了字符位置),可用于模型的训练
读取json数据(以训练集为例):
1、利用pandas进行json文件的读取,返回值为Series或DataFrame类型的:
train_data = pd.read_json(‘./dataset/mchar_train.json‘)
train_data
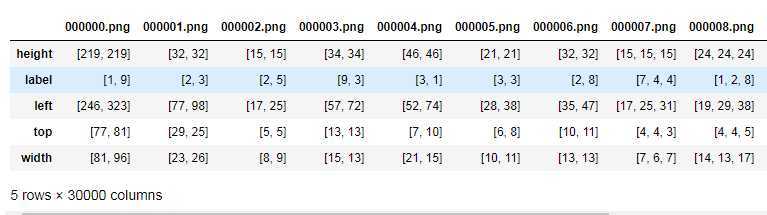
2、利用json模块对json文件进行读取,返回值为python字典类型:
import json
train_data= json.load(open(‘./dataset/mchar_train.json‘))
train_data

属性说明:
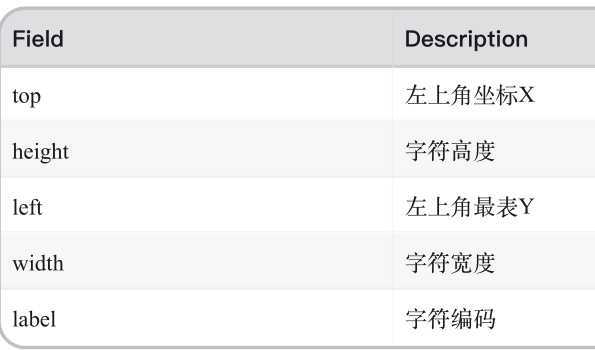
字符的坐标:
JSON 数据解析
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,它基于ECMAScript的一个子集。
python3中可以使用json模块对JSON数据进行编解码,包含两个函数:
- json.dumps():对数据进行编码
- json.loads():对数据进行解码
# 写入 JSON 数据 with open(‘data.json‘, ‘w‘) as f: json.dump(data, f) # 读取数据 with open(‘data.json‘, ‘r‘) as f: data = json.load(f)参考:Python3 JSON 数据解析
根据提供的标签编码和具体字符框的位置,将字符从图片中进行分离:
img = cv2.imread(‘./dataset/mchar_train/000001.png‘)
arr = parse_json(train_data[‘000001.png‘])
print(arr)
plt.figure(figsize=(10,10))
plt.subplot(1,arr.shape[1]+1,1)
plt.imshow(img)
plt.xticks([]);plt.yticks([])
print(arr.shape[1])
print(range(arr.shape[1]))
for idx in range(arr.shape[1]):
print(arr[0,idx])
print(arr[1,idx])
plt.subplot(1,arr.shape[1]+1,idx+2)
plt.imshow(img[arr[0,idx]:arr[0,idx]+arr[1,idx],arr[2,idx]:arr[2,idx]+arr[3,idx]])
plt.title(arr[4,idx])
plt.xticks([]);plt.yticks([])

赛题本质是分类问题,需要对图片中的字符进行识别。但对所给数据集中图片观察发现,图片中的字符数量不等。
既然属于分类识别任务,无非就是对其进行检测、识别、提高准确率。首先对字符的位置进行检测,提取到字符之后,就是识别的问题了,此时就感觉有点类似于cifar数字识别了。
根据提供的文档所列的思路:
定长字符识别:
将赛题抽象为一个定长字符识别问题,在赛题中大部分图像中的字符个数为2-4个,最多为6个,因此,对所有的图像都抽象为6个字符的识别问题,字符23填充为23xxxx,235填充为235xxx
不定长字符识别
在字符识别研究中,有特定的方法来解决此种不定长的字符识别问题,比较典型的有CRNN字符识别模型。本赛题给定的图像数据比较规整,可以视为一个单词或一个句子
检测再识别
在赛题数据中已经给出了训练集、验证集所有图片中字符的位置,因此可以先对字符的位置进行识别,利用物体检测的思路完成。
此思路需要构建字符检测模型,对测试集中的字符进行识别。可参考检测模型SSD或YOLO完成。
原文:https://www.cnblogs.com/whiteBear/p/12927033.html