优秀的库表设计是高性能数据库的基础。如何才能设计出高性能的库表结构呢?这里必须要提到数据库范式。范式是基础规范,反范式是针对性设计。
范式是设计数据库结构过程中所要遵循的规则和指导方法
其实范式有很多,目前关系数据库有六种范式:第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、巴斯-科德范式(BCNF)、第四范式(4NF)和第五范式(5NF,又称完美范式)。满足最低要求的范式是第一范式(1NF)。在第一范式的基础上进一步满足更多规范要求的称为第二范式(2NF),其余范式以次类推。一般来说,数据库只需满足第三范式(3NF)就行了。但是一般我们就用到前三个范式
第一范式是最基本的范式。如果数据库表中的所有字段值都是不可分解的原子值,就说明该数据库表满足了第一范式。
第一范式的合理遵循需要根据系统的实际需求来定。比如某些数据库系统中需要 用到“地址”这个属性,本来直接将“地址”属性设计成一个数据库表的字段就行。 但是如果系统经常会访问“地址”属性中的“城市”部分,那么就
非要将“地址”这个属 性重新拆分为省份、城市、详细地址等多个部分进行存储,这样在对地址中某一 部分操作的时候将非常方便。这样设计才算满足了数据库的第一范式,如下表所 示。
上表所示的用户信息遵循了第一范式的要求,这样在对用户使用城市进行分类的 时候就非常方便,也提高了数据库的性能。
第二范式在第一范式的基础之上更进一层。第二范式需要确保数据库表中的每一 列都和主键相关,而不能只与主键的某一部分相关(主要针对联合主键而言)。 也就是说在一个数据库表中,一个表中只能保存一种数据,
不可以把多种数据 保存在同一张数据库表中。
比如要设计一个订单信息表,因为订单中可能会有多种商品,所以要将订单编 号和商品编号作为数据库表的联合主键。
第三范式需要确保数据表中的每一列数据都和主键直接相关,而不能间接相关。
比如在设计一个订单数据表的时候,可以将客户编号作为一个外键和订单表建立 相应的关系。而不可以在订单表中添加关于客户其它信息(比如姓名、所属公司 等)的字段。
总结:1NF:无重复的列,属性不可以拆分(强调列的原子性,比如家庭电话和个人电话需要拆开)
2NF:属性完全依赖于主键
3NF:属性不传递依赖于其他非主属性
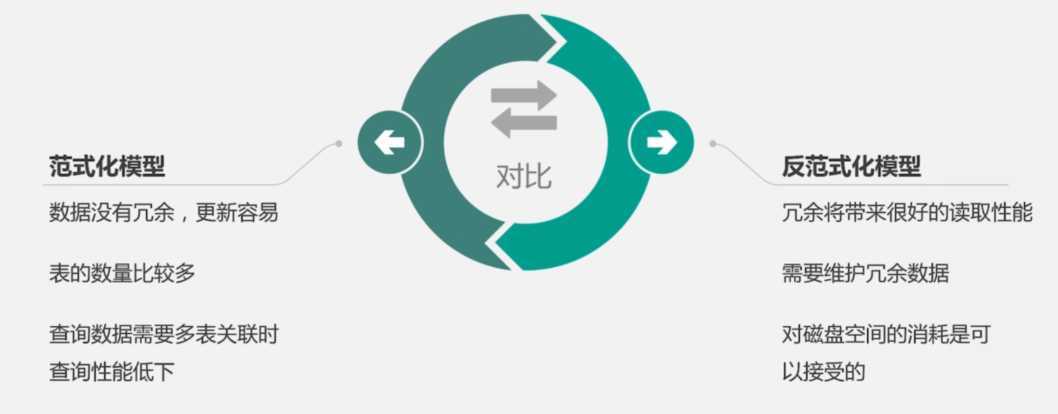
优点:避免数据冗余,减少数据的空间,数据变更速度更快
缺点:范式等级越高,表的数量越多,获取数据时表关联过多,性能较差
范式设计的表无法满足性能需求时,需要根据业务场景,在范式的基础上灵活设计
1.业务场景
2.响应时间
3.字段冗余
想要发挥 MySQL 的最佳性能,需要遵循 3 个基本使用原则。
大事务:运行步骤较多,涉及的表和字段较多,容易造成资源的争抢,甚至形成死锁。一旦事务回滚,会导致资源占用时间过长。
大 SQL:复杂的 SQL 意味着过多的表的关联,MySQL 数据库处理关联超过 3 张表以上的 SQL 时,占用资源多,性能低下。
大批量:意味着多条 SQL 一次性执行完成,必须确保进行充分的测试,并且在业务低峰时段或者非业务时段执行。
大字段:blob、text 等大字段,尽量少用。必须要用时,尽量与主业务表分离,减少对这类字段的检索和更新。
这里在实践中有个小问题,如何让系统中区分大小写的库表转换为不区分大小写的库表呢?因为要修改底层数据,还是比较麻烦的,操作步骤如下:
MySQL dump 导出数据库。
修改参数 lower_case_tables_name=1。
导入备份数据时,必须停止数据库,停止业务,影响非常大。
MySQL 数据库提供的功能很全面,但并不是所有的功能性能都高效。
存储过程、触发器、视图、event。为了存储计算分离,这类功能尽量在程序中实现。这些功能非常不完整,调试、排错、监控都非常困难,相关数据字典也不完善,存在潜在的风险。一般在生产数据库中,禁止使用。
lob、text、enum、set。这些字段类型,在 MySQL 数据库的检索性能不高,很难使用索引进行优化。如果必须使用这些功能,一般采取特殊的结构设计,或者与程序结合使用其他的字段类型替代。比如:set 可以使用整型(0,1,2,3)、注释功能和程序的检查功能集合替代。
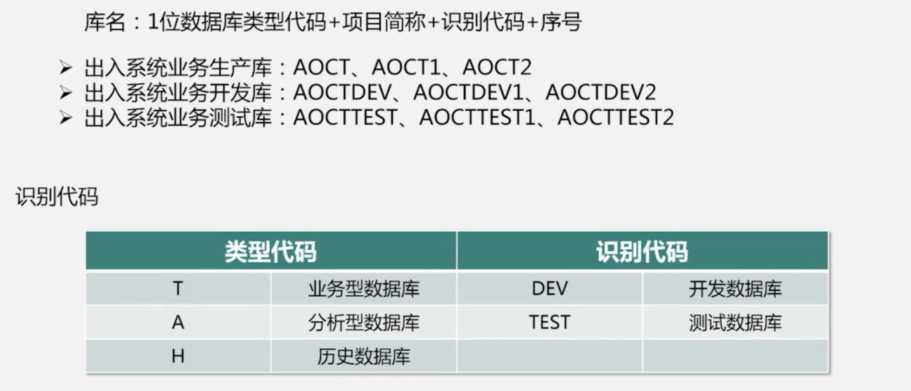
库名:1位数据库类型代码+项目简称+识别代码+序号
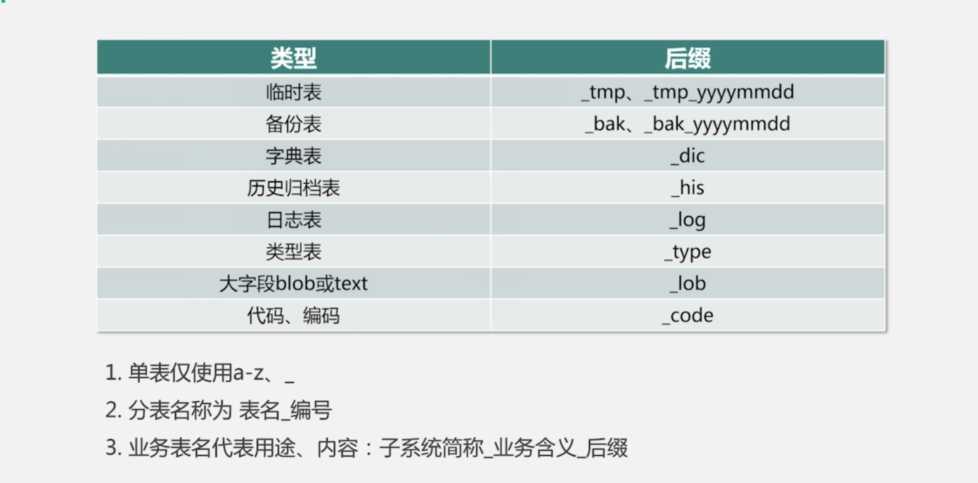
表名:
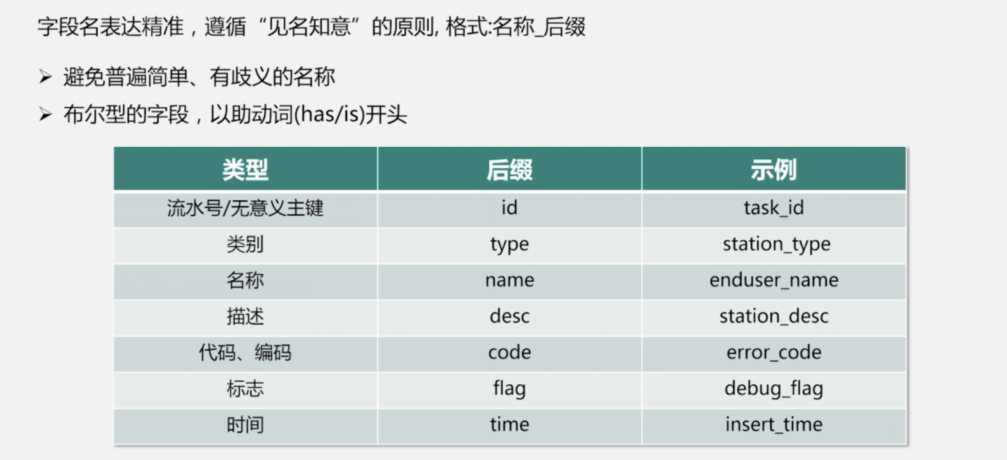
字段名:
数据值进行参考
总结
原文:https://www.cnblogs.com/dmzna/p/12936505.html