例题
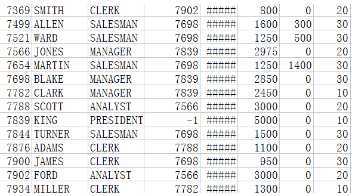
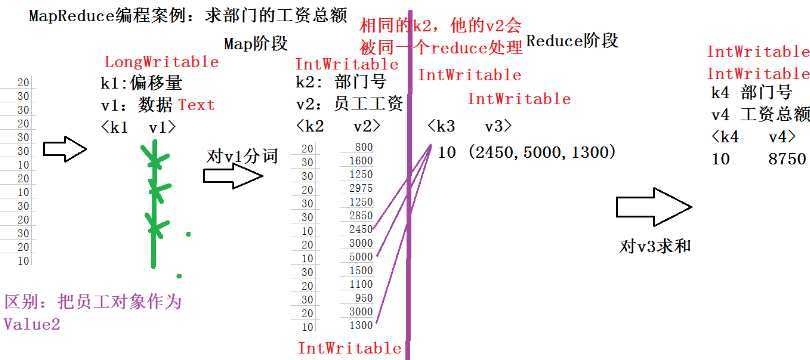
SalaryTotalMapper.java
 View Code
View CodeSalaryTotalReducer.java
View CodeSalaryTotalMain.java
View CodeDistinctMain.java
View CodeDistinctMapper.java
View CodeDistinctReducer.java
View Code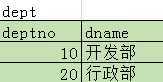
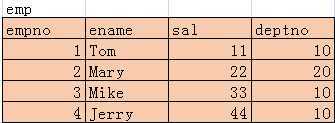
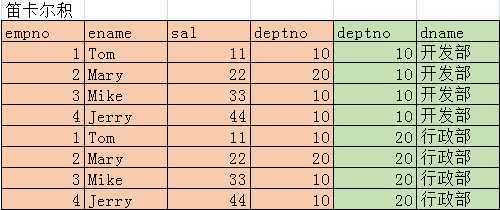
EqualJoinMain.java
View CodeEqualJoinMapper.java
View CodeEqualJoinReducer.java
View Code
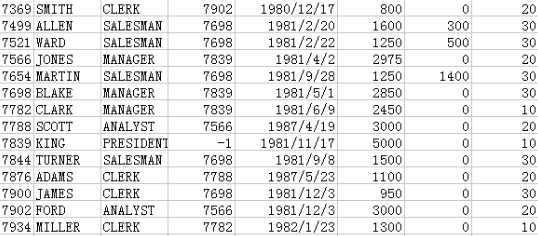

SelfJoinMain.java
View CodeSelfJoinMapper.java
View CodeSelfJoinReducer.java
View Code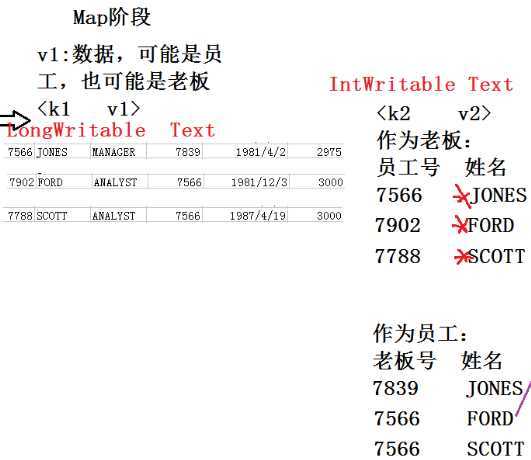
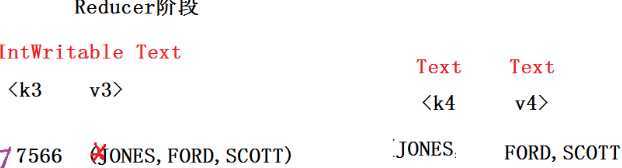




RevertedIndexMain.java
1 import java.io.IOException; 2 3 import org.apache.hadoop.conf.Configuration; 4 import org.apache.hadoop.fs.Path; 5 import org.apache.hadoop.io.IntWritable; 6 import org.apache.hadoop.io.Text; 7 import org.apache.hadoop.mapreduce.Job; 8 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 9 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 10 11 12 public class RevertedIndexMain { 13 14 public static void main(String[] args) throws Exception { 15 //1、创建一个任务 16 Job job = Job.getInstance(new Configuration()); 17 job.setJarByClass(RevertedIndexMain.class); //任务的入口 18 19 //2、指定任务的map和map输出的数据类型 20 job.setMapperClass(RevertedIndexMapper.class); 21 job.setMapOutputKeyClass(Text.class); //k2的数据类型 22 job.setMapOutputValueClass(Text.class); //v2的类型 23 24 //指定任务的Combiner 25 job.setCombinerClass(RevertedIndexCombiner.class); 26 27 //3、指定任务的reduce和reduce的输出数据的类型 28 job.setReducerClass(RevertedIndexReducer.class); 29 job.setOutputKeyClass(Text.class); //k4的类型 30 job.setOutputValueClass(Text.class); //v4的类型 31 32 //4、指定任务的输入路径、任务的输出路径 33 FileInputFormat.setInputPaths(job, new Path(args[0])); 34 FileOutputFormat.setOutputPath(job, new Path(args[1])); 35 36 //5、执行任务 37 job.waitForCompletion(true); 38 } 39 40 }
RevertedIndexMapper.java
1 import java.io.IOException; 2 3 import org.apache.hadoop.io.LongWritable; 4 import org.apache.hadoop.io.Text; 5 import org.apache.hadoop.mapreduce.Mapper; 6 import org.apache.hadoop.mapreduce.lib.input.FileSplit; 7 8 public class RevertedIndexMapper extends Mapper<LongWritable, Text, Text, Text> { 9 10 @Override 11 protected void map(LongWritable key1, Text value1, Context context) 12 throws IOException, InterruptedException { 13 //数据:/indexdata/data01.txt 14 //得到对应文件名 15 String path = ((FileSplit)context.getInputSplit()).getPath().toString(); 16 17 //解析出文件名 18 //得到最后一个斜线的位置 19 int index = path.lastIndexOf("/"); 20 String fileName = path.substring(index+1); 21 22 //数据:I love Beijing and love Shanghai 23 String data = value1.toString(); 24 String[] words = data.split(" "); 25 26 //输出 27 for(String word:words){ 28 context.write(new Text(word+":"+fileName), new Text("1")); 29 } 30 } 31 }
RevertedIndexCombiner.java
1 import java.io.IOException; 2 3 import org.apache.hadoop.io.Text; 4 import org.apache.hadoop.mapreduce.Reducer; 5 6 public class RevertedIndexCombiner extends Reducer<Text, Text, Text, Text> { 7 8 @Override 9 protected void reduce(Text k21, Iterable<Text> v21, Context context) 10 throws IOException, InterruptedException { 11 // 求和:对同一个文件中的单词进行求和 12 int total = 0; 13 for(Text v:v21){ 14 total = total + Integer.parseInt(v.toString()); 15 } 16 17 //k21是:love:data01.txt 18 String data = k21.toString(); 19 //找到:冒号的位置 20 int index = data.indexOf(":"); 21 22 String word = data.substring(0, index); //单词 23 String fileName = data.substring(index + 1); //文件名 24 25 //输出: 26 context.write(new Text(word), new Text(fileName+":"+total)); 27 } 28 }
RevertedIndexReducer.java
1 import java.io.IOException; 2 3 import org.apache.hadoop.io.Text; 4 import org.apache.hadoop.mapreduce.Reducer; 5 6 public class RevertedIndexReducer extends Reducer<Text, Text, Text, Text> { 7 8 @Override 9 protected void reduce(Text k3, Iterable<Text> v3, Context context) 10 throws IOException, InterruptedException { 11 String str = ""; 12 13 for(Text t:v3){ 14 str = "("+t.toString()+")"+str; 15 } 16 17 context.write(k3, new Text(str)); 18 } 19 20 }
原文:https://www.cnblogs.com/cxc1357/p/12763498.html
