有人说SQL语句难学,其实并不难!只要掌握了基本的语句执行顺序,用程序化的思维分析结构,再难的问题也会迎刃而解!
假设有如下表emp
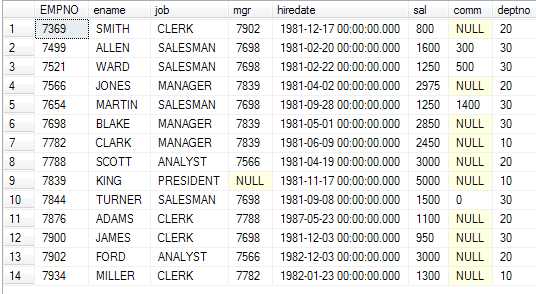
现在要求 列出员工姓名(ename)中不含A的所有人按照部门编号(deptno)分组后,每个部门的平均工资大于2000的部门的编号、工资、人数
分析上题,罗列出具体要求
1.员工姓名(ename)中不含A
2.将所有员工按照部门分组
3.找出平均工资大于2000的所有部门
4.列出部门编号、人数、平均工资
如果分别解决这些问题,那么很简单

1. select * from emp where ename not like ‘%A%‘ 2. select deptno from emp group by deptno 3. select deptno from emp group by deptno having avg(sal)>2000 4. select deptno,count(*),avg(sal) from emp group by deptno
接着考虑把步骤合在一块儿之前,必须了解sql语句的执行顺序
SQL Select语句完整的执行顺序:
如果放在SQL语句上,将这些步骤用SQL语句描述,则更加直观
再回到题目
列出员工姓名(ename)中不含A的所有人按照部门编号(deptno)分组后,每个部门的平均工资大于2000的部门的编号、工资、人数
现在可以按照SQL语句处理思维,重新描述解决步骤,每个子句执行完毕都生成了一张临时表
1.from子句定位到emp表
from emp
执行完这句,系统创建的临时表如下
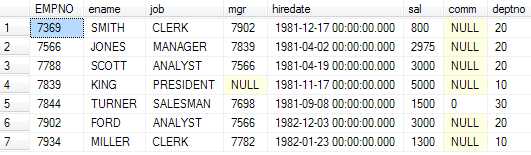
2.从上面的临时表中 筛选出所有ename中不包含A的
from emp
where ename not like ‘%A%‘
执行完,临时表变成了:
3.再根据deptno对上面的临时表进行分组(为了便于理解,这里提前显示了部门编号 人数和平均工资)
from emp
where ename not like ‘%A%‘
group by deptno
执行完这句,临时表变成了:

4.再从上一张临时表中 找出平均工资大于2000的部门,并选择要显示那些列(部门编号 部门人数 部门平均工资)
select deptno "部门编号",count(*) "部门人数",avg(sal) "部门平均工资"
from emp
where ename not like ‘%A%‘
group by deptno
having avg(sal)>2000
执行完这坨代码,临时表又变成了

5.好了,到这里sql语句全部执行完毕,系统自动将上面临时表显示在客户端
最终结果,也就是你看到的
说说我对SQL语句执行顺序的理解,以SQL Server为例
原文:http://www.cnblogs.com/hoosway/p/3554203.html