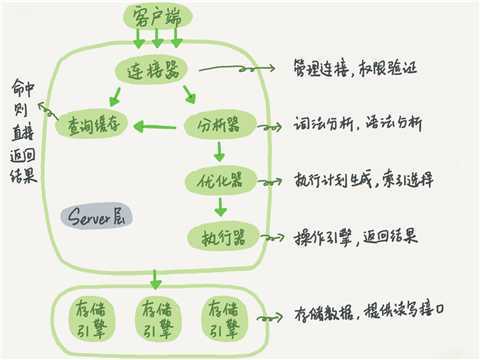
大体来说,MySQL 可以分为 Server 层和存储引擎层两部分。
Server 层包括连接?、查询缓存、分析?、优化?、执行?等,涵盖 MySQL 的大多数核心服务功能,以及所有的内置函数(如日期、时间、数学和加密函数等),所有跨存储引 擎的功能都在这一层实现,比如存储过程、触发?、视图等。
而存储引擎层负责数据的存储和提取。其架构模式是插件式的,支持 InnoDB、MyISAM、 Memory 等多个存储引擎。现在最常用的存储引擎是 InnoDB,它从 MySQL 5.5.5 版本开 始成为了默认存储引擎。
连接器
连接器负责跟客户端建立连接、获取权限、维持和管理连接
一个用户成功建立连接后,即使你用管理员账号对这个用户的权限做了修
改,也不会影响已经存在连接的权限。修改完成后,只有再新建的连接才会使用新的权限
设置。
show processlist查看连接状态
wait_timeoutSleep状态的连接在等待时间后自动断开,默认值8小时
长连接与短连接:建立连接的过程比较复杂,尽量减少建立连接的动作,使用长连接。长连接导致MySQL占用内存过大,考虑以下方案:
定期断开长连接。使用一段时间,或者程序里面判断执行过一个占用内存的大查询后,断开连接,之后要查询再重连。
如果你用的是 MySQL5.7或更新版本,可以在每次执行一个比较大的操作后,通过执行mysql_reset_connection来重新初始化连接资源。这个过程不需要重连和重新做权限验证,但是会将连接恢复到刚刚创建完时的状态。
查询缓存
查询结果会以 key-value 对的形式保存在查询缓存中。
查询缓存的失效非常频繁,更新操作会清空表上所有的查询缓存。因此查询缓存适用于更新很少的静态表。MySQL 8.0 版本将查询缓存的整块功能删掉了。
将参数 query_cache_type 设置成DEMAND,默认的 SQL 语句不使用查询缓存。用SQL_CACHE显式指定使用查询缓存:select SQL_CACHE * from T where ID=10
分析器
优化器
选择索引:优化器根据扫描行数并结合是否使用临时表、是否排序等因素进行综合判断
扫描行数->统计信息->索引“区分度”->索引“基数”:索引上不同值的个数
基数查看:show index from table
基数采样统计:N个数据页不同值的平均值*总页面数=基数。变更数据行数超过1/M的时候,会自动触发再次基数统计。MySQL有两种存储索引统计的方式,可以通过设置参数innodb_stats_persistent的值来选择:设置为on的时候,表示统计信息会持久化存储。默认的N是20,M是10。设置为off的时候,表示统计信息只存储在内存中。默认N是8,M是16。
选择表连接顺序
执行器
执行语句前会判断权限
打开表的时候,执行器就会根据表的引擎定义,去使用这个引擎提供的接口。
原文:https://www.cnblogs.com/zhaoyingchun/p/12942911.html