函数式编程基础
1)函数定义/声明
3)递归//难点 [最短路径,邮差问题,迷宫问题, 回溯]
4)过程
5)惰性函数和异常
函数式编程高级
1)值函数(函数字面量)
2)高阶函数
3)闭包
4)应用函数
5)柯里化函数,抽象控制...
def 函数名 ([参数名: 参数类型], ...)[[: 返回值类型] =] {
语句...
return 返回值
}
方法声明关键字为def (definition)
[参数名: 参数类型], ...:表示方法的输入(就是参数列表), 可以没有。 如果有多个参数使用逗号间隔
方法中的语句:表示为了实现某一功能代码块
方法可以有返回值,也可以没有
返回值形式1: : 返回值类型 =
返回值形式2: = 表示返回值类型不确定,使用类型推导完成
返回值形式3: 表示没有返回值,return 不生效
如果没有return ,默认以执行到最后一行的结果作为返回值
package com.rzp.functioncoding ? object FuctionDemo { def main(args: Array[String]): Unit = { println(getRes(2,3,‘0‘)) } ? def getRes(n1: Int, n2: Int, cal: Char) = { if (cal == ‘+‘) { n1 + n2 } else if (cal == ‘-‘) { n1 - n2 } else { null } } }
Scala中,方法和函数的定义、使用、运行机制都一样。
函数更加灵活
方法可以转换成函数
package com.rzp.functioncoding ? object Method2Fuction { def main(args: Array[String]): Unit = { val dog = new Dog println(dog.sum(10,20)) //方法转换成函数 val f1=dog.sum _ println(s"f1=${f1}") println(s"f1=${f1(50,60)}") ? //函数 val f2 = (n1:Int,n2:Int) => n1+n2 println(s"f2=${f2}") println(s"f2=${f2(4,4)}") } } class Dog{ def sum(n1:Int,n2:Int):Int = { n1+n2 } }
和lambda表达式对比
Lambda需要有函数式接口,再通过Lambda表达式写实现。
和方法对比差不多,但是函数的写法明显简单太多了。
package com.rzp; ? public class servicedemo { public static void main(String[] args) { Count count = (int i,int j) ->{ return i+j; }; System.out.println(count.lamdba(1,2)); } ? } interface Count{ int lamdba(int i,int j); }
从上面例子可以看出,函数和方法的本质其实是一样的,归根结底也就是输入->输出。
所谓函数式编程只是我们的写代码的方式改变了,把原来写的方法简化成了这种形式:
val f2 = (n1:Int,n2:Int) => n1+n2
在Java中我们也可以写函数,但是要依赖于接口、类、方法。
但是在Scala中我们没有依赖这些,函数就是函数,只要这种写法,就叫函数。
因此Scala中是把函数式编程和面向对象编程融合在一起,
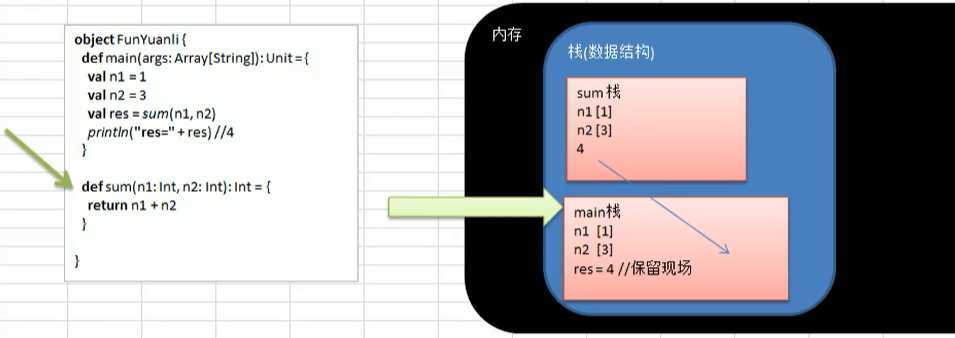
示意图:
其实就和JVM中讲的一样,这里把所有东西都放在栈里好说明,实际对象还是在堆里。
相同的地方就是每个方法就在栈里占一块内存,记录了下一个栈帧。
main方法执行后会跳到sum方法,sum方法执行完回到main方法,sum这块区域不再引用,相当于弹出栈了。


package com.rzp.functioncoding ? object OwnMethod { def main(args: Array[String]): Unit = { println(plus(6)) } def plus(n: Int): Int = { plus(n,1,0) } def plus(n: Int, or: Int, of: Int): Int = { if (n > 1) { val ar = or + of plus(n - 1, ar, or) } else { or } } } ?
示例答案:


package com.rzp.functioncoding ? object OwnMethod2 { def main(args: Array[String]): Unit = { println(functionF(5)) } def functionF(n: Int): Int = { if (n==1){ 1 }else{ functionF(n - 1) * 2 + 1 } } }
没有形参时,调用时可以不带()
最后一行不写return会把最后一行结果返回
def getSum(n1: Int, n2: Int): Int = { n1 + n2 }
不写返回值类型,会自行推断
def getSum(n1: Int, n2: Int) = { n1 + n2 }
如果不写返回值类型,也不写等号,会表示该函数没有返回值,这时候即使写了return也没用。
不写返回值相当于返回Unit
//返回() def getSum2(n1:Int,n2:Int){ return n1+n2 }
如果写了return,必须要明确写返回值类型

如果明确函数无返回值或不确定返回值类型,那么返回值类 型可以省略或声明为Any(所有类的父类)
def f4(s: String): Any = { if(s.length >= 3) s + "123" else 3}
?Scala语法中任何的语法结构都可以嵌套其他语法结构(灵活),即:函数中可以再声明/定义函数,类中可以再声明类 ,方法中可以再声明/定义方法
package com.rzp.functioncoding ? object Detail01 { def main(args: Array[String]): Unit = { println("123") //虽然下面定义了内部方法,但是没有调用就不会执行 def f1(){println("f1")} //编译后的类文件,这个方法会变成这个类的方法,private final ? def sayOk(): Unit ={ //private final sayOk$1 def sayOk(): Unit ={ //private final sayOk$2 ? } } } ? def sayOk(): Unit ={ println("ok") ? } ? }
Scala函数的形参,在声明参数时,直接赋初始值,这时调用函数时,如果没有指定实参,则会使用默认值。如果指定了实参,则实参会覆盖默认值
def sayOk(name : String = "jack"): String = { return name + " ok! " }
?如果函数存在多个参数,每一个参数都可以设定默认值,那么这个时候,传递的参数到底是覆盖默认值,还是赋值给没有默认值的参数,就不确定了(默认按照声明顺序[从左到右])。在这种情况下,可以采用带名参数
def mysqlCon(add:String = "localhost",port : Int = 3306, user: String = "root", pwd : String = "root"): Unit = { println("add=" + add) println("port=" + port) println("user=" + user) println("pwd=" + pwd) } //调用的时候,如果不输入参数,就很简单,全部使用默认参数 mysqlCon() //输入普通参数,会从左到右覆盖 mysqlCon("127.0.0.1",3308) //可以输入带名参数 mysqlCon(user="tom",pwd="123")
?Scala 函数的形参默认是val的,因此不能在函数中进行修改.
递归函数未执行之前是无法推断出来结果类型,在使用时必须有明确的返回值类型
def f8(n: Int) = { // 错误,递归不能使用类型推断,必须指定返回的数据类型
if(n <= 0){
1
}else{
n * f8(n - 1)
}
}
?Scala函数支持可变参数
//支持0到多个参数 def sum(args :Int*) : Int = { } //支持1到多个参数 def sum(n1: Int, args: Int*) : Int = { } //args 是集合, 通过 for循环 可以访问到各个值。 //可变参数需要写在形参列表的最后。
?函数简写
虽然下面例子f1看起来很像一个变量,但是本质是一个函数。
object Hello01 { def main(args: Array[String]): Unit = { def f1 = "venassa" // println(f1) } } 题1 //输出 venassa def f1 = "venassa" 等价于 def f1() = { "venassa" }
?
?过程就是一个定义,返回类型是Unit的方法,就叫过程。
开发工具的自动代码补全功能,虽然会自动加上Unit,但是考虑到Scala语言的简单,灵活,最好不加.

惰性计算(尽可能延迟表达式求值)是许多函数式编程语言的特性。
惰性集合在需要时提供其元素,无需预先计算它们,这带来了一些好处.
可以将耗时的计算推迟到绝对需要的时候。
可以创造无限个集合,只要它们继续收到请求,就会继续提供元素。
函数的惰性让代码更高效。Java 并没有为惰性提供原生支持,Scala提供了。
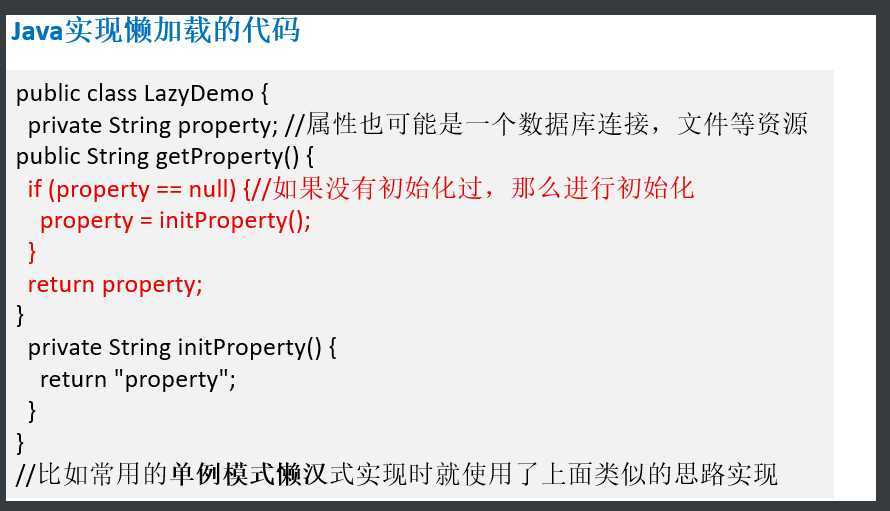
在调用函数的时候,加入lazy关键字,就可以在真正使用的时候再计算。
lazy 不能修饰 var 类型的变量
声明一个变量时,给 lazy,分配也会推迟。 比如 lazy val i = 10
package com.rzp.lazy1 ? object LazyDemo01 { def main(args: Array[String]): Unit = { //如果不加lazy,那么在这行代码就执行了 lazy val res = sum(10, 20) println("-----------------") //加了lazy以后,在调用的时候才执行 println("res=" + res) ? //sum函数 def sum(n1: Int, n2: Int): Int = { println("sum() 执行了..") return n1 + n2 } } } //输出 ----------------- sum() 执行了.. res=30 ?
?Scala提供try和catch块来处理异常。
try块用于包含可能出错的代码。catch块用于处理try块中发生的异常。
可以根据需要在程序中有任意数量的try...catch块。
语法处理上和Java类似
Java异常处理的注意点.
java语言按照try—catch-catch...—finally的方式来处理异常
不管有没有异常捕获,都会执行finally, 因此通常可以在finally代码块中释放资源
可以有多个catch,分别捕获对应的异常,这时需要把范围小的异常类写在前面,把范围大的异常类写在后面,否则编译错误。会提示 "Exception ‘java.lang.xxxxxx‘ has already been caught"
我们将可疑代码封装在try块中。
catch处理程序来捕获异常。如果发生任何异常,程序将不会异常终止。
catch子句是按次序捕捉的。因此越具体的异常越要靠前。
如果把越普遍的异常写在前,在Scala中也不会报错,但不推荐。
不同点:Scala没有“checked(编译期)”异常,即Scala没有编译异常这个概念,异常都是在运行的时候捕获处理。
try { val r = 10 / 0 } catch { case ex: ArithmeticException=> println("捕获了除数为零的算数异常") case ex: Exception => println("捕获了异常") } finally { // 最终要执行的代码 println("scala finally...") } } ?
?用throw关键字,抛出一个异常对象。所有异常都是Throwable的子类型。
throw表达式是有类型的,就是Nothing,因为Nothing是所有类型的子类型,所以throw表达式可以用在需要类型的地方
Scala提供了throws关键字来声明异常。可以使用方法定义声明异常。 它向调用者函数提供了此方法可能引发此异常的信息。 它有助于调用函数处理并将该代码包含在try-catch块中,以避免程序异常终止。在scala中,可以使用throws注释来声明异常
相当于Java中方法后的Throw
def main(args: Array[String]): Unit = { f11() } @throws(classOf[NumberFormatException])//等同于NumberFormatException.class def f11() = { "abc".toInt } ?
打印三角形

package com.rzp.pratice01 ? object PracticeDemo { def main(args: Array[String]): Unit = { printTri(5) } ? //n=1 def printTri(n: Int): Unit = { for (i <- 1 to n) { for (j <- 1 to (n-i)) print(" ") for (j <- 1 to (2*i-1))print("*") println("") } } } ?
Scala语言是面向对象的
Java是面向对象的编程语言,由于历史原因,Java中还存在着非面向对象的内容:基本类型 ,null,静态方法等。
Scala语言来自于Java,所以天生就是面向对象的语言,而且Scala是纯粹的面向对象的语言,即在Scala中,一切皆为对象。
属性在编译的时候是private的,并且会自动生成get和set方法
Class编译后和object不同,只会生成1个类。
定义的Class默认就是public的
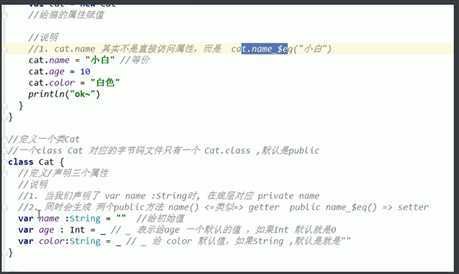

使用_下划线赋予默认值的时候,必须要声明类型。

和Java一样
1、一个数字如果为正数,则它的signum为1;如果是负数,则signum为-1;如果为0,则signum为0.编写一个函数来计算这个值 def isPositive(n: Int): Int = { if (n > 0) { 1 } else if (n < 0) { -1 } else { 0 } 2、一个空的块表达式{}的值是什么?类型是什么? def whatIsBit: Unit = { println({}) var n = {} println(n.isInstanceOf[Unit]) } ? 3、针对下列Java循环编写一个Scala版本: for(int i=10;i>=0;i–)System.out.println(i); def printI(n: Int) { for (i <- Range(n, 0, -1)) { println(s"i=${i}") } for (i<- 0 to 10 reverse){ println(i) } } ? ? ? 9、编写函数计算 ,其中n是整数,使用如下的递归定义: • = x* ,如果n是正数的话 • = 1 • = 1/ ,如果n是负数的话 • 不得使用return语句 def countXn(x:Int,n: Int): Int = { if (n == 0) { 1 } else if (n > 0) { x * countXn(x,n-1) }else { 1 / countXn(x,-n) } } ?
?5、编写一个for循环,计算字符串中所有字母的Unicode代码(toLong方法)的乘积。举例来说,"Hello"中所有字符串的乘积为9415087488L
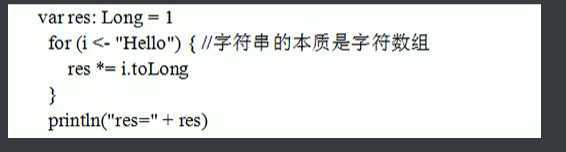
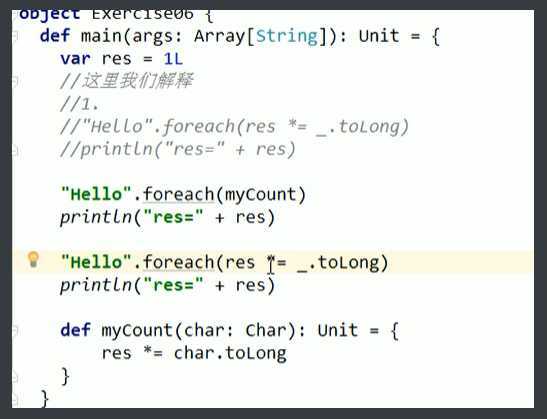
6、同样是解决前一个练习的问题,请用StringOps的foreach方式解决。
注意这里Foreach的用法:
Hello实际上就是一个字符数组,因此.foreach会自动遍历这个数组,把每个字符传进去。
()内部相当于一个方法,这个方法的输入形参为_,实际输入的参数就是每个字符。
因此每次遍历就是res = res * 每个字符
最后输出res即可。
7、编写一个函数product(s:String),计算字符串中所有字母的Unicode代码(toLong方法)的乘积
def product(s: String): Long = { var b = 1l for (i <- 0 until s.length) { val a: Long = s.charAt(i) b = a * b println(b) } b }
8、把7练习中的函数改成递归函数
def productMy(s: String): Long = { if (s != null && s.length > 0) { val a: Long = s.charAt(0) * productMy(s.substring(1)) a } else { 1 } }

Object是一个对象。
通过在同包下创建同名Class,我们可以创建显式的创建伴生类,而Object就叫伴生对象。
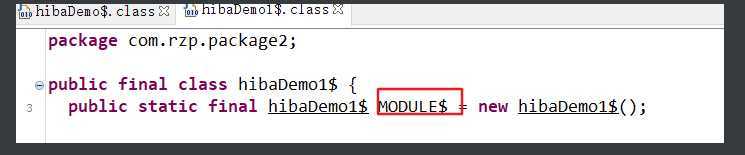
显式是指我们在第一章就学到,Scala自动会创建伴生类和伴生对象,hibaDemo1$.class 和 hibaDemo1.class。
比如下面例子的hibaDemo1,在同一个包里面有同名的Object和Class。
编译后,Object就是hibaDemo1$.class,class就是hibaDemo1.class
编译后的文件中:伴生类的内容是非静态的,伴生对象的内容是静态的。
因为Scala的设计者把static拿掉了,因为他认为static不是面向对象的。但是为了和Java兼容,所以设计了这么一个结构。
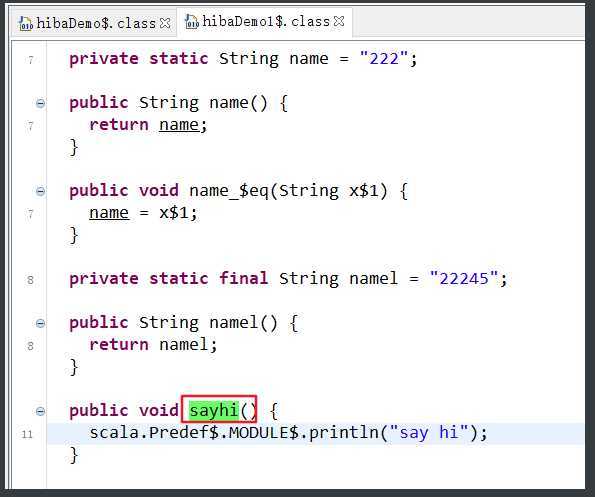
package com.rzp.package2 ? object hibaDemo1 { var age: Int = _ val agel: Int = 20 ? var name = "222" val namel = "22245" ? def sayhi(): Unit = { println("say hi") } ? class hibaClass { var hiba = "123" } ? def main(args: Array[String]): Unit = { println(name) val demo = new hibaDemo1 println(demo.name) } } ? class hibaDemo1 { var name = "123" private var age = 20 protected var sal = 20 ? } ? object Test { private val demo = new hibaDemo1 ? def main(args: Array[String]): Unit = { val person = new Person println(person.name) println(person.age) } } ? class Person { //增加包范围权限:可以指定哪个包及其子包下的类/对象也能访问private属性 private[package2] var name = "tom" protected[package2] var age = 123 }
编译后的文件:
可以看到Object($)中的属性是静态的,Class中是非静态的。
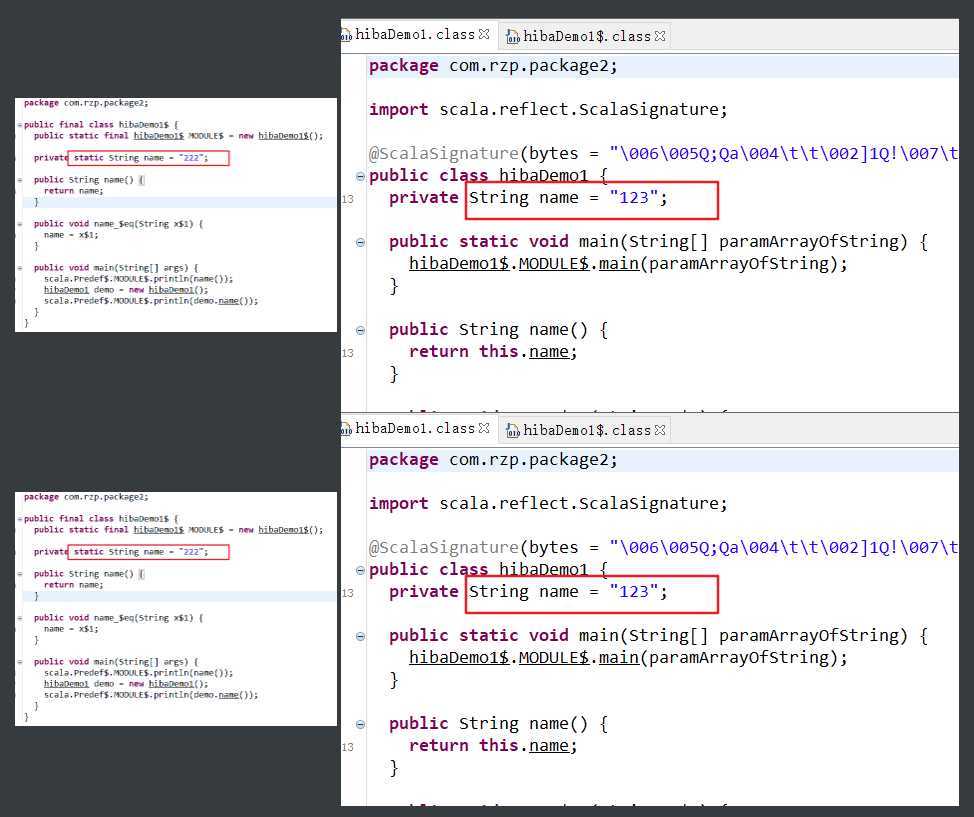
但是方法不是静态的,是通过静态对象module实现的
Scala中伴生对象采用object关键字声明,伴生对象中声明的全是 "静态"内容,可以通过伴生对象名称直接调用。
伴生对象中的属性和方法都可以通过伴生对象名(类名)直接调用访问。
scala实际是将伴生对象生成了一个新的类,实现静态属性和方法的调用,而不是直接声明static。
从底层原理看,伴生对象实现静态特性是依赖于 public static final MODULE$ 实现的。
伴生对象的声明应该和伴生类的声明在同一个源码文件中(如果不在同一个文件中会运行错误!)。
如果 class A 独立存在,那么A就是一个类, 如果 object A 独立存在,那么A就是一个"静态"性质的对象[即类对象], 在 object A中声明的属性和方法可以通过 A.属性 和 A.方法 来实现调用
当一个文件中,存在伴生类和伴生对象时,文件的图标会发生变化
伴生对象-apply方法
在伴生对象中定义apply方法,可以实现: 类名(参数) 方式来创建对象实例.
package com.rzp.objectorient ? object ApplyDemo { def main(args: Array[String]): Unit = { val pig = Pig("rzp") val pig2 = Pig() ? println(pig.name) println(pig2.name) } } ? ? class Pig(aname:String){ var name :String = aname } ? object Pig{ def apply(aname:String):Pig = new Pig(aname) ? def apply(): Pig = new Pig("匿名小duidui") }


Scala构造器也可以重载

?
?
Scala构造器作用是完成对新对象的初始化,构造器没有返回值。
主构造器的声明直接放置于类名之后
主构造器会执行类定义中的所有语句,这里可以体会到Scala的函数式编程和面向对象编程融合在一起,即:构造器也是方法(函数),传递参数和使用方法和前面的函数部分内容没有区别
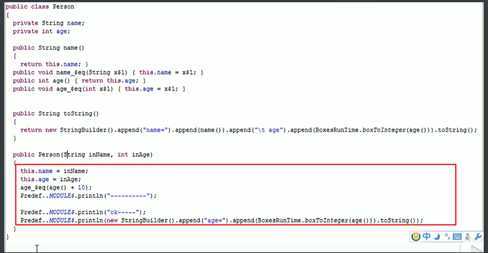
如果主构造器无参数,小括号可省略,构建对象时调用的构造方法的小括号也可以省略
辅助构造器名称为this,多个辅助构造器通过不同参数列表进行区分, 在底层就是f构造器重载。
使用辅助构造器,要先调用主构造器,并且执行类定义的所有语句,最后再执行辅助构造器。
和Java一样,执行主构造器的时候也是先调用父类的构造器。
Scala中,辅助构造器里面不能直接调用父类构造器,为了调用父类构造器,必须先调用主构造器。
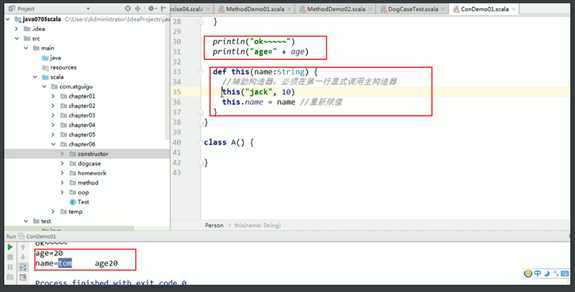
如果想让主构造器变成私有的,可以在()之前加上private,这样用户只能通过辅助构造器来构造对象了。
package com.rzp.practice02 ? object ConstructorDemo { def main(args: Array[String]): Unit = { val worker = new Worker3("javk") println(worker.inName) println(worker.name) } } ? //1.普通的构造器,inName只是作为构造器的一个输入参数 class Worker(inName:String){ var name = inName } //2.用val修饰,编译后inName是一个private final属性,并且只提供了get方法 class Worker2(val inName:String){ var name = inName } //3.用var修改,编译后inName是一个private属性,有get/set方法,就相当于在类里直接加了var inName class Worker3(var inName:String){ var name = inName } ?
Java中我们给get和set方法。
Scala中通过增加注解BeanProperty可以自动生成。
自动生成的get和set方法和原来底层自动生成的类get/set并不冲突,两者会共存。
object ConstructorDemo { def main(args: Array[String]): Unit = { val car = new Car car.setName("asdf") car.getName } } ? ? class Car { @BeanProperty var name :String = null } ?

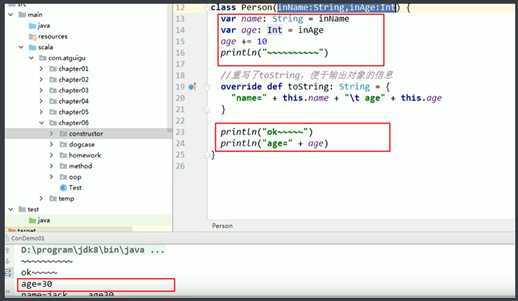
var p : Person = new Person("小倩",20) 流程分析
加载类的信息(属性信息,方法信息)
在内存中(堆)开辟空间
使用父类的构造器(主和辅助)进行初始
使用主构造器对属性进行初始化 【age:90, naem nul】
使用辅助构造器对属性进行初始化 【 age:20, naem 小倩 】
将开辟的对象的地址赋给 p这个引用
区分相同名字的类
当类很多时,可以很好的管理类
控制访问范围
实际上就是创建不同的文件夹来保存类文件
java中包名和源码所在的系统文件目录结构要一致,编译后的字节码文件路径也和包名保持一致。
package com.atguigu;
通过import注入
import java.util.Scanner;
引入不同包下同名类和Java一样,写全限定名
var cat1 = new com.atguigu.chapter02.xh.Cat()
var cat2 = new com.atguigu.chapter02.xm.Cat()
?
?
Scala中包名和源码所在的系统文件目录结构要可以不一致,但是编译后的字节码文件路径和包名会保持一致(这个工作由编译器完成)。
//比如这个包,和源码目录可以不一样
//不一样的部分编译器会自动生成文件夹
package com.rzp.lazy1

虽然自动引入了Scala包,但是子包没有自动引入,比如Scala.io下的,要重新引入。
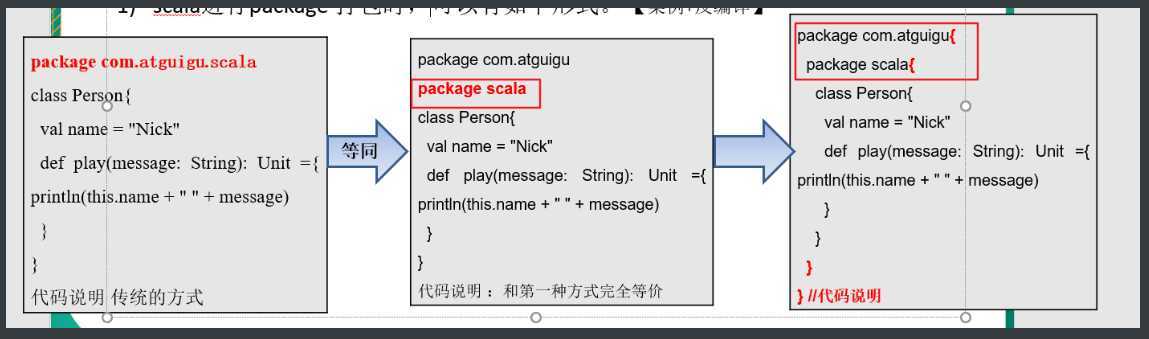
有三种:
第三种做法的好处是我们可以在1个文件里创建多个包
一般建议嵌套的包不要超过3层。
很好理解,和Java一样
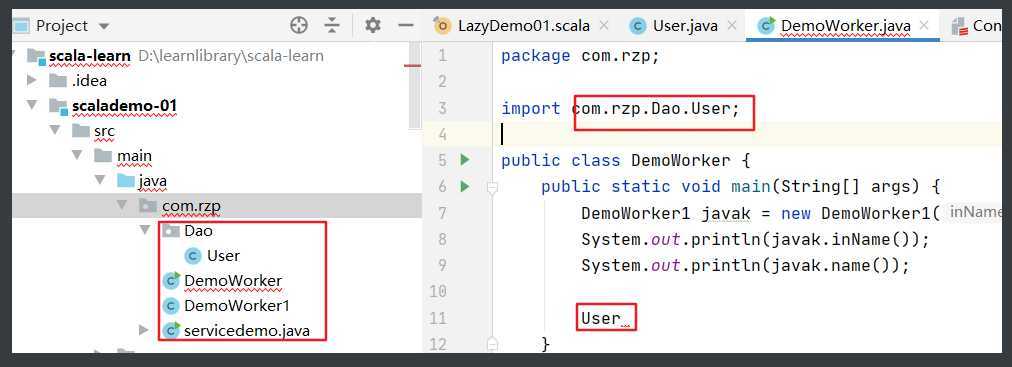
和Java不同,Java中子包使用父包的类,需要import。
在子包和父包类重名时,默认采用就近原则,如果希望指定使用某个类,则带上包名即可。
package com.rzp.testdemo ? package com.atguigu { //这个类就是在com.atguigu包下 class User { println("Father") } class Dog { println("dog") } package scala { //这个类就是在com.atguigu.scala包下 class User { println("son") } //这个Test 类对象 object TestDemo { def main(args: Array[String]): Unit = { //子类可以直接访问父类的内容 var dog = new Dog() //在子包和父包 类重名时,默认采用就近原则. var u = new User() //在子包和父包 类重名时,如果希望指定使用某个类,则带上包路径 var u2 = new com.atguigu.User() } } } }
?访问BeanProperty的绝对路径是:_root_. scala.beans.BeanProperty ,在一般情况下:我们使用相对路径来引入包,只有当包名冲突时(我们自己写的包名和Scala的包名冲突),使用绝对路径来处理
//第一种形式 @BeanProperty var age1: Int = _ //第二种形式, 和第一种一样,都是相对路径引入 @scala.beans.BeanProperty var age2: Int = _ //第三种形式, 是绝对路径引入,可以解决包名冲突 @_root_. scala.beans.BeanProperty var age3: Int = _ ?
包可以包含类、对象和特质trait,但不能包含函数/方法或变量的定义。这是Java虚拟机的局限。
为了弥补这一点不足,scala提供了包对象的概念来解决这个问题。
通过package + object关键字,可以声明一个包对象。包对象里就可以声明变量和方法、trait。
再另外声明一个同名的包,包对象中定义的变量和方法可以直接使用。
包对象和包一定要在同一个包下,1个包只能有1个包对象。
声明包对象后,编译后会在同名包中创建package.class和package$.class,里面承载的内容见下文。
package com.rzp.packagedemo ? ? package object fatherpackage{ val name = "" def sayHi(){} trait TraitDemo{ } //包对象的方法和属性,内部可以直接使用 object Demo01 { private val car = new Car sayHi() } class Car{ sayHi() } ? } package fatherpackage{ object fpObject{ def main(args: Array[String]): Unit = { //可以在同名子包下直接使用,不需要注入 val car = new Car sayHi() } } } ?
?
?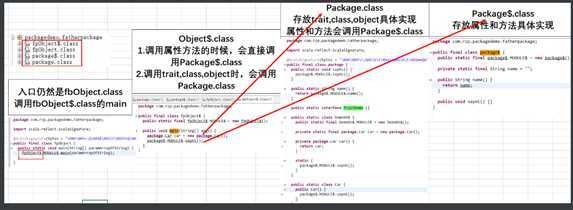
ppdp -->内包子外
修饰符可以用来修饰类中的属性,成员方法以及类
只有默认的和public才能修饰类!,并且遵循上述访问权限的特点。
伴生对象可以使用伴生类中的private属性。
其他规则一样,private只有类内部可以使用。
底层实现:private属性的get/set方法也是private
不写关键字就是default,Scala中不能显式定义default
var name : String = "jack"
Default在属性和方法的表现不同:
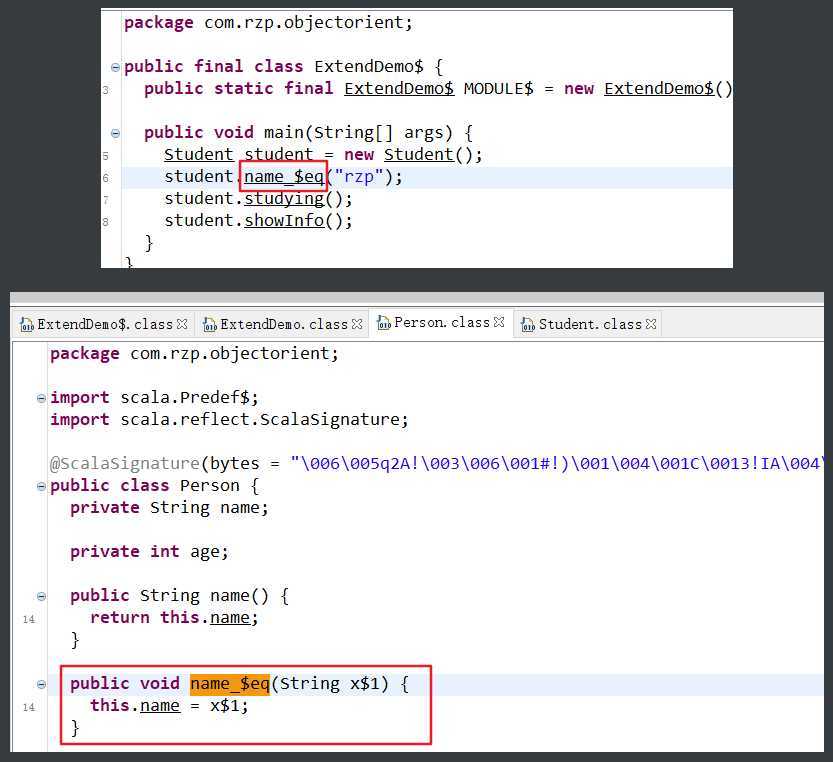
属性:从底层看属性是private的,但是因为提供了xxx_$eq()[类似setter]/xxx()[类似getter] 方法,因此从使用效果看是任何地方都可以访问)
方法:默认为public访问权限
子类可以访问,同包无法访问 。
是由编译器控制的,在编译的层面上控制只能子类访问,所以编译出来的class文件中,protected变成了public。
Scala 中不能显式定义public。
本来private和protected在正常情况下,Test是不能访问的,但是可以指定包名
这个包及其子包下的类/对象也能访问private/protected属性
package com.rzp.package2 ? object Test{ def main(args: Array[String]): Unit = { val person = new Person println(person.name) println(person.age) } } ? class Person{ //增加包范围权限:可以指定哪个包及其子包下的类/对象也能访问private/protected属性 private[package2] var name = "tom" protected [package2] var age = 123 } ? ?
这种语法的好处是:在需要时在引入包,缩小import 包的作用范围,提高效率
def test(): Unit = { import scala.collection.mutable.{HashMap, HashSet} var map = new HashMap() var set = new HashSet() }
?
?import java.util.{ HashMap=>JavaHashMap, List} import scala.collection.mutable._ var map = new HashMap() // 此时的HashMap指向的是scala中的HashMap var map1 = new JavaHashMap(); // 此时使用的java中hashMap的别名 ?
import java.util.{ HashMap=>_, _} // 含义为 引入java.util包的所有类,但是忽略 HahsMap类. var map = new HashMap() // 此时的HashMap指向的是scala中的HashMap, 而且idea工具,的提示也不会显示java.util的HashMaple ?
封装、继承和多态
封装(encapsulation)就是把抽象出的数据和对数据的操作封装在一起,数据被保护在内部,程序的其它部分只有通过被授权的操作(成员方法),才能对数据进行操作。
隐藏实现细节
提可以对数据进行验证,保证安全合理
对类中的属性进行封装
通过成员方法,包实现封装
和Java一样,属性private,提供公共的get/set 的def
Scala中声明属性时,自动提供了setter/getter实现封装,因此如果只是简单的set/get,不需要显式的再封装。
如果属性声明为private的,那么自动生成的setter/getter方法也是private的,如果属性省略访问权限修饰符,那么自动生成的setter/getter方法是public的
有了上面的特性,目前很多新的框架,在进行反射时,也支持对属性的直接反射
继承可以解决代码复用,让我们的编程更加靠近人类思维
当多个类存在相同的属性(变量)和方法时,可以从这些类中抽象出父类(比如Student),在父类中定义这些相同的属性和方法,所有的子类不需要重新定义这些属性和方法,只需要通过extends语句来声明继承父类即可
写法用法其实和Java一样,extend继承父类所有的属性和方法,可以访问非私有的。
package com.rzp.objectorient ? object ExtendDemo { def main(args: Array[String]): Unit = { val student = new Student student.name = "rzp" student.studying() student.showInfo() } } ? ? class Person { var name : String = _ var age : Int = _ def showInfo(): Unit = { println("学生信息如下:") println("名字:" + this.name) } } ? class Student extends Person { def studying(): Unit = { println(this.name + "学习 scala中....") } } ?
分析编译后的文件,可以看到实际上调用的父类的public方法。
scala明确规定:
重写一个非抽象方法需要用override修饰符
重写抽象的方法不需要override(这时候不算重写,算实现)
调用超类的方法使用super关键字(如果没有重写,不需要super关键字直接调用即可)
package com.rzp.objectorient ? object OverrideDemo { def main(args: Array[String]): Unit = { val emp = new Emp1 emp.printName() } } class Person1 { var name : String = "tom" def printName() { println("Person printName() " + name) } def sayHi(): Unit ={ println("say hi") } } class Emp1 extends Person1 { //这里需要显式的使用override override def printName() { println("Emp printName() " + name) super.printName() sayHi() } }
?和Java一样的方法判断是什么类型,在Any中定义了isInstanceOf 和asInstanceOf
classOf[String] --获取对象的类名
obj.isInstanceOf [T] --判断obj是不是T类型
obj.asInstanceOf[T] --将obj的引用强转成T类型。
类型检查的价值在于输入的是多态时,可以通过类型判断,转换成不同的子类执行不同的方法。
package com.rzp.objectorient ? object TypeConvert { def main(args: Array[String]): Unit = { val emp = new Emp2 //获取类的全限定名 println(classOf[Emp2]) //反射获取类名 println(emp.getClass.getName) var p1 = new Person2 val emp2 = new Emp2 //讲子类引用给父类 p1 = emp2 //将父类引用重新转给子类引用 var emp3 = p1.asInstanceOf[Emp2] //能够调用子类特有方法,说明转换成功 emp3.sayHello() } } class Person2 { var name : String = "tom" def printName() { println("Person printName() " + name) } def sayHi(): Unit ={ println("say hi") } } class Emp2 extends Person2 { //这里需要显式的使用override override def printName() { println("Emp printName() " + name) super.printName() super.sayHi() sayHi() } def sayHello(): Unit ={ println("say hello") } } ?
?在Java中,创建子类对象时,子类的构造器总是去调用一个父类的构造器(显式或者隐式调用)。

类有一个主构器和任意数量的辅助构造器,而每个辅助构造器都必须先调用主构造器(也可以是间接调用)
继承的时候在主构造器以前先执行父类的构造器
子类中只有主构造器可以调用父类构造器,在调用的时候可以传任意参数。
package com.rzp.objectorient ? object ExtendContructor { def main(args: Array[String]): Unit = { ? val emp = new Emp4("rzp") //Scala先构建父类,所以先执行父类构造器 println("Person...") //再执行子类的主构造器 println("Emp ....") //最后执行子类的辅助构造器 println(emp.name) } } ? class Person4(pName:String) { var name = pName println("Person...") def this(){ this("默认名字") println("父类辅助构造器") } } ? class Emp4 extends Person4 { println("Emp ....") ? def this(name: String) { this // 必须调用主构造器 this.name = name println("Emp 辅助构造器~") } } ?
在Scala中,子类改写父类的字段,我们称为覆写/重写字段。覆写字段需使用 override修饰。
在Java中,只有方法有重写和多态,属性是没有重写的,访问属性时总是看引用属性。
动态绑定:
如果调用的是方法,则JVM会把方法和对象的内存地址绑定。
如果调用的是属性,则没有动态绑定机制。
package com.rzp.objectorient; ? ? public class DaynamicBind { public static void main(String[] args) { A a = new B(); //方法调用的时候,使用的是对象的属性,而不是引用的属性 System.out.println(a.getI());//20 System.out.println(a.i);//10 System.out.println(a.sum1());//30 } ? } class A { public int i = 10; public int sum() { return getI() + 10; } public int sum1() { return i + 10; } public int getI() { return i; } } class B extends A { public int i = 20; public int sum() { return i + 20; } public int getI() { return i; } public int sum1() { return i + 10; } } ?
scala中,子类访问的总是子类的属性。
因为看起来是访问属性,但是实际上是调用age的get方法,所以会返回对象的属性
package com.rzp.objectorient ? object ScalaFiledOverride { def main(args: Array[String]): Unit = { val obj : C = new D() val obj2 : D = new D() ? //看起来是访问属性,但是实际上是调用age的get方法,所以会返回对象的属性 println(obj.age) println(obj2.age) } } ? class C{ val age :Int = 10 } ? class D extends C { override val age : Int = 20 } ?
def只能重写另一个def(即:方法只能重写另一个方法)
val只能重写另一个val 属性 或 重写不带参数的def
class A { def sal(): Int = { return 10 }} ? class B extends A { override val sal : Int = 0 } ?
?
?
?var只能重写另一个抽象的var属性
抽象属性:声明未初始化的变量就是抽象的属性,抽象属性在抽象类
编译后抽象属性其实没有属性,只有抽象的方法。
抽象属性在编译时,会自动生成抽象方法,所以类必须声明为抽象类
如果是覆写一个父类的抽象属性,那么override 关键字可省略.
本质上是实现父类的抽象方法。

在Scala中,通过abstract关键字标记不能被实例化的类。
方法不用标记abstract,只要省掉方法体即可。
抽象类可以拥有抽象字段,抽象字段/属性就是没有初始值的字段
抽象类不能被实例
抽象类不一定要包含abstract方法。
抽象类可以没有abstract方法
但有抽象方法或者抽象属性的类必须声明为abstract
抽象方法不能有主体,不允许使用abstract修饰。
如果一个类继承了抽象类,则它必须实现抽象类的所有抽象方法和抽象属性,除非它自己也声明为abstract类。
抽象方法和抽象属性不能使用private、final 来修饰,因为这些关键字都是和重写/实现相违背的。
抽象类中可以有实现的方法.
子类重写抽象方法不需要override,写上也不会错.
和Java一样,可以通过包含带有定义或重写的代码块的方式创建一个匿名的子类.
var monster = new Monster { override var name: String = "牛魔王" override def cry(): Unit = { println("牛魔王哼哼叫唤..") } } abstract class Monster{ var name : String def cry()} ?
?interface 接口名
class 类名 implements 接口名1,接口2
在Java中, 一个类可以实现多个接口。
在Java中,接口之间支持多继承
接口中属性都是常量
接口中的方法都是抽象的
Scala语言中,采用特质trait(特征)来代替接口的概念,也就是说,多个类具有相同的特征(特征)时,就可以将这个特质(特征)独立出来,采用关键字trait声明。
trait就可以声明特质。
extends可以继承特质、类。
继承多个特质时,后续用with连接:
如果有父类,那么只能有1个父类,并且放第一位
trait testTrait{ } ? class A extends testTrait with xxx with xxx{ }
?
?具体方法是用默认方法实现的。
特质中没有实现的方法就是抽象方法。
既有抽象方法,又有具体方法的,有叫做富接口。
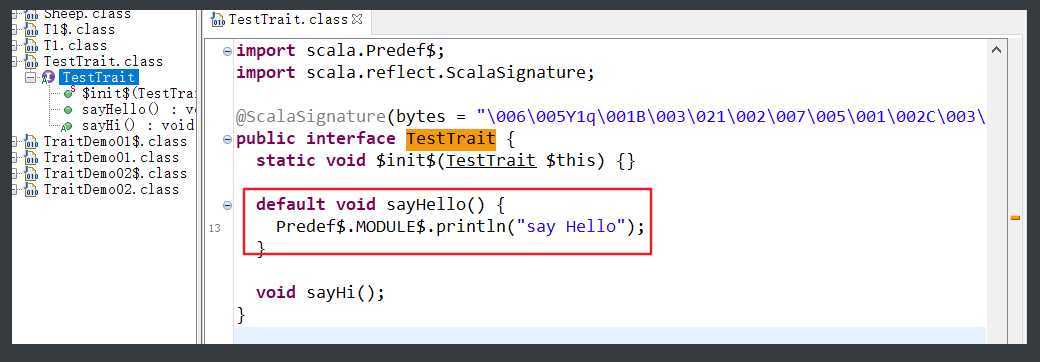
包括Serializable,Cloneable等常用接口。
即:如果继承多个特质,这些特质之间必须是同一个父类的子类(可以是间接的)。
除了可以在类声明时继承特质以外,还可以在构建对象时混入特质,扩展目标类的功能。
动态混入是Scala特有的方式(java没有动态混入),可在不修改类声明/定义的情况下,扩展类的功能,非常的灵活,耦合性低 。
动态混入可以在不影响原有的继承关系的基础上,给指定的类扩展功能。
实例化对象增加with关键字就可以动态混入
object MixInDemo03 { def main(args: Array[String]): Unit = { var oracle = new OracleDB with Operate3 oracle.insert(999) //MySQL3没有抽象方法,所以相当于实现了,所以可以直接实例化,这种用法我也是醉了 val mysql = new MySQL3 with Operate3 mysql.insert(4) //匿名内部类+动态混入 val mySQL4 = new MySQL4 with Operate3 { override def say(): Unit = { println("MySQL4 say") } } mySQL4.insert(3) mySQL4.say() ? } } ? trait Operate3 { def insert(id: Int): Unit = { println("插入数据 = " + id) } } ? class OracleDB { } abstract class MySQL3 { } ? abstract class MySQL4 { def say() }
?
?如果混入多个特质,称之为叠加特质
特质声明顺序是实例,然后特质从左到右,方法执行顺序从右到左(其实就是栈)。
方法执行,如果走到最左了,会执行父特质的方法。
object AddTraits { def main(args: Array[String]): Unit = { val mysql = new MySQL5 with DB4 with File4 //val mysql = new MySQL4 with File4 with DB4 mysql.insert(888) ? } } trait Operate4 { println("Operate4...") def insert(id : Int) } trait Data4 extends Operate4 { println("Data4") override def insert(id : Int): Unit = { println("插入数据 = " + id) } } trait DB4 extends Data4 { println("DB4") override def insert(id : Int): Unit = { print("向数据库") super.insert(id) } } trait File4 extends Data4 { println("File4") override def insert(id : Int): Unit = { print("向文件") super.insert(id) }} class MySQL5 {} ? ? //输出 Operate4... Data4 DB4 File4 向文件向数据库插入数据 = 888
?
?如果想要调用具体特质的方法,可以指定:super[特质].xxx(…)
其中的泛型必须是该特质的直接超类类型
一旦指定了,就不会再向左找了,直接执行完指定的特质方法就完了。
trait File4 extends Data4 { println("File4") override def insert(id : Int): Unit = { print("向文件") super[Data4].insert(id) }} ?
特质继承特质后,在重写的方法中再次调用父类的方法时,这个特质必须加上abstract override ,说明这是一个部分实现的特质,还需要进一步实现。
trait Operate5 { def insert(id : Int) } abstract override trait File5 extends Operate5 { def insert( id : Int ): Unit = { println("将数据保存到文件中..") super.insert(id) } } ?
?super关键字在动态叠加混入中使用时,不是调用父特质,而是调用左边叠加的特质的方法。
特质中可以定义具体字段,如果初始化了就是具体字段,如果不初始化就是抽象字段。混入该特质的类就具有了该字段,字段不是继承,而是直接加入类,成为自己的字段。

this:Exception =>就是我们说的自身类型声明,等价于extend Exception
这告诉编译器,所有继承Logger的具体类必须同时也是一个Exception
因为Logger的业务代码里已经调用了Exception的方法,如果具体类无法满足Logger的这一要求,编译就将失败。
作用在蛋糕模式中补充。
//Logger就是自身类型特质 trait Logger { // 明确告诉编译器,我就是Exception,如果没有这句话,下面的getMessage不能调用 this: Exception => def log(): Unit ={ // 既然我就是Exception, 那么就可以调用其中的方法 println(getMessage) } } trait Logger1 extends Exception{ // 明确告诉编译器,我就是Exception,如果没有这句话,下面的getMessage不能调用 def log(): Unit ={ // 既然我就是Exception, 那么就可以调用其中的方法 println(getMessage) } } ? class Console extends Logger1 { def aaa(): Unit ={ println(getMessage) } } class Console1 extends Exception with Logger ?
?在Scala中,几乎可以在任何语法结构中内嵌任何语法结构。如在类中可以再定义一个类,这样的类是嵌套类,其他语法结构也是一样。类似Java中的内部类。
val outer1 : ScalaOuterClass = new ScalaOuterClass(); val outer2 : ScalaOuterClass = new ScalaOuterClass(); ? // Scala创建内部类的方式和Java不一样,将new关键字放置在前,使用 对象.内部类 的方式创建 val inner1 = new outer1.ScalaInnerClass() val inner2 = new outer2.ScalaInnerClass() //创建静态内部类对象 val staticInner = new ScalaOuterClass.ScalaStaticInnerClass() println(staticInner) ? class ScalaOuterClass { class ScalaInnerClass { //成员内部类 } } object ScalaOuterClass { //伴生对象 class ScalaStaticInnerClass { //静态内部类 } }
?
?内部类如果想要访问外部类的属性,可以通过外部类对象访问。
即:访问方式:外部类名.this.属性名
class ScalaOuterClass { var name : String = "scott" private var sal : Double = 1.2 class ScalaInnerClass { //成员内部类 def info() = { // 访问方式:外部类名.this.属性名 // ScalaOuterClass.this 就相当于是 ScalaOuterClass 这个外部类的一个实例 // 然后通过 ScalaOuterClass.this 实例对象去访问 name 属性 // 只是这种写法比较特别,学习java的同学可能更容易理解 ScalaOuterClass.class 的写法. println("name = " + ScalaOuterClass.this.name + " age =" + ScalaOuterClass.this.sal) }}} ? object ScalaOuterClass { //伴生对象 class ScalaStaticInnerClass { //静态内部类 } } ? ?
class ScalaOuterClass { myOuter => //myOuter就是外部类的别名,相当于一个对象. class ScalaInnerClass { //成员内部类 //使用的时候可以直接用myOuter直接访问外部类属性 def info() = { println("name = " + ScalaOuterClass.this.name + " age =" + ScalaOuterClass.this.sal) println("-----------------------------------") println("name = " + myOuter.name + " age =" + myOuter.sal) }} // 当给外部指定别名时,需要将外部类的属性放到别名后. var name : String = "scott" private var sal : Double = 1.2 } ? ?
在Java中,内部类从属于外部类。
但是在Scala中,内部类从属于外部类的对象。
比如这个例子
object Touying { def main(args: Array[String]): Unit = { val out1 = new ScalaOuterClass3 val out2 = new ScalaOuterClass3 val inner1 = new out1.ScalaInnerClass3 val inner2 = new out2.ScalaInnerClass3 inner1.test(inner2) } } ? class ScalaOuterClass3 { myOuter => class ScalaInnerClass3 { //成员内部类 def test(ic: ScalaInnerClass3): Unit = { System.out.println(ic) } } }
这里就会报错:因为要求out1的inner1,不能注入inner2
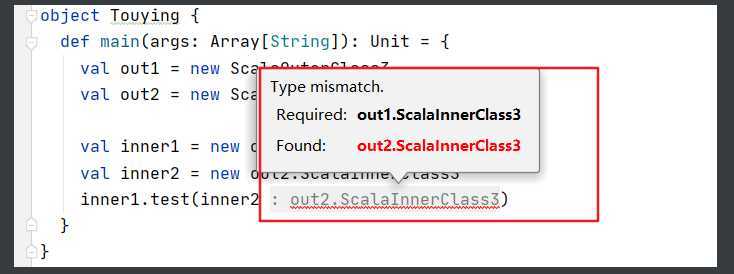
这时候可以增加类型投影 ScalaOuterClass3#:
增加类型投影后,可以屏蔽外部类对内部类的影响。
class ScalaOuterClass3 { myOuter => class ScalaInnerClass3 { // ScalaOuterClass3# def test(ic: ScalaOuterClass3#ScalaInnerClass3): Unit = { System.out.println(ic) } } }
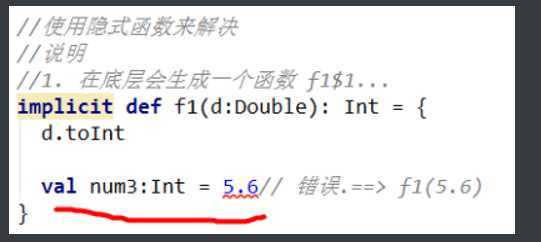
从低精度到高精度可以自动隐式转换,但是高精度到低精度就不能自动隐式转换了。
为了解决大量使用高精度到低精度的转换场景,可以使用隐式函数。
隐式转换函数是以implicit关键字声明的带有单个参数的函数。
这种函数将会自动应用,将值从一种类型转换为另一种类型
这个函数相当于方法,也就是能调用这个方法的地方,就是这个函数的作用范围。
比如下面个例子,隐式函数是一个类的方法,这个类的其他方法可以调用。
如果写在main方法里面,那么作用域就只有main方法里面,sayHi的方法里就报错了。
但是写在伴生对象中时,伴生类不会自动生效。
package com.rzp.implicitfunction ? object Demo01 { //编写一个隐式函数,转换Double->Int implicit def double2Int(d:Double):Int={ d.toInt } def main(args: Array[String]): Unit = { //那么作用域内,Double转换成Int就可以实现自动转换 val num :Int = 3.5 println(s"num = ${num}") } def sayHi(): Unit ={ val num :Int = 3.5 } }
?package com.rzp.implicitfunction ? object Demo02 { def main(args: Array[String]): Unit = { //通过隐式函数返回DB,让MySQl可以调用delete方法。 implicit def addDelete(mysql:MySQL): DB = { new DB // } val mysql = new MySQL mysql.insert() mysql.delete() //? } ? } class MySQL{ def insert(): Unit = { println("insert") } } class DB { def delete(): Unit = { println("delete") } }
?在方法中,我们可以在形参中给默认值。
def sayOk(name : String = "jack"): String = { return name + " ok! " }
使用隐式值,可以同时给多个方法赋予默认值
隐式值也叫隐式变量,将某个形参变量标记为implicit,编译器会在方法省略隐式参数的情况下去搜索作用域内的隐式值作为缺省参数。
package com.rzp.implicitfunction ? object Demo03 { implicit val str1: String = "jack" def main(args: Array[String]): Unit = { //掉用的时候,不能写小括号,因为写小括号了就是显式声明要调用无参的hello方法 hello hello1 hello("123") } //在形参中增加implicit,会自动搜索隐式值作为参数输入 def hello(implicit name: String): Unit = { println(name + " hello") } def hello1(implicit name: String): Unit = { println(name + " hello1") } }
?隐式值优先级比方法中的默认值优先级高。
如果有多个同类型的隐式值,会报错,因为不知道取哪个值,比如
object ImplicitVal02 { def main(args: Array[String]): Unit = { // 2个隐式变量(值)• implicit val name: String = "Scala" implicit val name1: String = "World" ? def hello(implicit content: String = "jack"): Unit = { println("Hello " + content) } //调用hello• hello } } ?
在scala2.10后提供了隐式类,可以使用implicit声明类,可以扩展类的功能,比前面使用隐式转换丰富类库功能更加的方便。
在集合中隐式类会发挥重要的作用。
隐式类的构造参数有且只能有一个
隐式类必须被定义在“类”或“伴生对象”或“包对象”里,即隐式类不能是顶级的(top-level objects)。
隐式类不能是case class(case class在后续介绍 样例类),作用域内不能有与之相同名称的标识符
实际:和方法一样
方法的时机回顾:当方法中的参数的类型与目标类型不一致时
当对象调用所在类中不存在的方法或成员时,编译器会自动将对象进行隐式转换(根据类型)
package com.rzp.implicitfunction ? object Demo04 { def main(args: Array[String]): Unit = { //DB1是一个隐式类,在作用域范围内,创建MySQL1中创建实例时,会对应生成隐式的对象 implicit class DB1(val m: MySQL1) { def addSuffix(): String = { m + " scala" } } val mysql1 = new MySQL1 mysql1.sayOk() //这时候Mysql1就可以调用DB1中的方法 //编译后实际上时调用DB1$2这个对象的方法 //mysql1.addSuffix() ==> scala.Predef$.MODULE$.println(DB1$2(mysql1).addSuffix()); println(mysql1.addSuffix()) ? } } class MySQL1 { def sayOk(): Unit = { println("sayOk") } } ?
隐式解析的机制:编译器是如何查找到缺失信息的,解析具有以下两种规则:
首先会在当前代码作用域下查找隐式实体(隐式方法、隐式类、隐式对象)。(一般是这种情况)
如果第一条规则查找隐式实体失败,会继续在隐式参数的类型的作用域里查找。类型的作用域是指与该类型相关联的全部伴生模块,一个隐式实体的类型T它的查找范围如下(第二种情况范围广且复杂在使用时,应当尽量避免出现): a) 如果T被定义为T with A with B with C,那么A,B,C都是T的部分,在T的隐式解析过程中,它们的伴生对象都会被搜索。 b) 如果T是参数化类型,那么类型参数和与类型参数相关联的部分都算作T的部分,比如List[String]的隐式搜索会搜索List的伴生对象和String的伴生对象。 c) 如果T是一个单例类型p.T,即T是属于某个p对象内,那么这个p对象也会被搜索。 d) 如果T是个类型注入S#T,那么S和T都会被搜索
在进行隐式转换时,需要遵守两个基本的前提:
不能存在二义性
隐式操作不能嵌套使用 // [举例:]如:隐式转换函数
原文:https://www.cnblogs.com/renzhongpei/p/12944895.html