基础知识
1. 感受野计算--为什么VGG模型在feature层的感受野是228 = 196+16*2
https://www.cnblogs.com/objectDetect/p/5947169.html
该链接中还给出计算感受野的python小程序。
我们接下来的分析以Faster rcnn网络中的使用的backbone网络VGG16。
首先VGG16网络参数
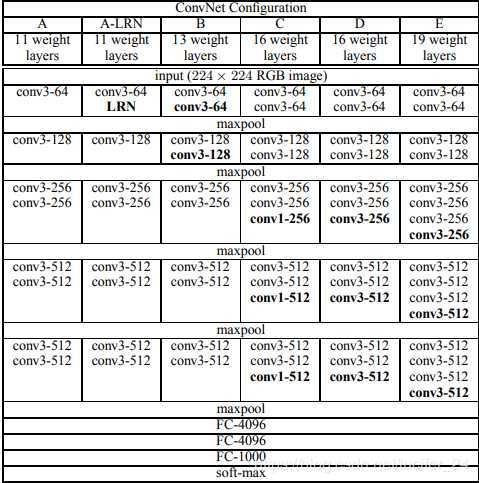
Faster rcnn论文中使用的是D型网络。
计算得到:vgg中最后一个conv5_3 得到的参数如下:
conv13:
n features: 14.0
jump: 16
receptive size: 196 start: 0.5
con5_3的感受野是196。
然后RPN网络的组成中有一个3*3的conv layer,因此在anchor所在的feature map层所看到的感受野=196+jmpu(16)*(kernel(3)-1) = 228 !
2. vgg+rpn网络的构建如何理解?
详细的请参考:https://blog.csdn.net/Mr_health/article/details/84953759
【tensorflow + Faster RCNN】构建vgg前端和RPN网络
3. anchors相关
关于多尺度目标检测。
可以看有三的深度学习中的多尺度模型设计!
https://zhuanlan.zhihu.com/p/74710464
那么,faster rcnn中其实提出的是一种pyramids of anchors.
关于如何理解pyramids of anchors?
https://zhuanlan.zhihu.com/p/32230004
anchor的本质是什么,本质是将相同尺寸的 conv5_3 层的输出,倒推得到不同尺寸的输入。接下来是anchor的窗口尺寸,详细说下这个尺寸的来源,最基本的anchor只有一个尺寸,是16*16的尺寸,然后设定了基本的面积scale是(8,16,32),用这三个scale乘以16就得到了三个面积尺寸(128^2,256^2,512^2),然后在每个面积尺寸下,取三种不同的长宽比例(1:1,1:2,2:1).这样一来,我们得到了一共9种面积尺寸各异的anchor。
4. Faster-RCnn中RPN网络中卷积核大小与AnchorBox对应不同尺度是否有关
RPN网络的3*3卷积只是一个滑窗的概念,每个点的9个anchor共享3*3窗口的感受野区域。
第一层是固定的3x3卷积,对所有的9个anchor来说是一样的。这个3x3卷积的感受野,映射到原图上,就是228x228的区域(VGG网络)。只有在第2层的2个1x1卷积,是分别针对不同anchor的,它们的输出通道串起来就是2k和4k这个数量了。所以,anchor的scale和ratio都只是跟1x1卷积的输出通道相关的,参数是学出来的,但输入的3x3卷积特征都是一样的。
5. 如何正确理解RPN网络的3*3卷积的作用?
https://www.zhihu.com/question/376333386
这个其实个人觉得没有什么特别的原因。先针对你的问题进行解答:
至于RPN加3x3 Conv其实给我感觉就是一种偏直觉做法。backbone的特征图拿来,其pretrain时包含的都是较强的分类特征。在此特征基础上,3x3卷积对特征进行二次变换。之后加入两个支路,这样貌似更合理,直接将两个支路加在backbone的conv5特征图上可能会使得conv5特征图分布发生巨大的变化。从增量逻辑上看不见得好。加入3x3 Conv起码给了网络另一条潜在的优化路线:即backbone分布不太剧烈变化,通过3x3 conv将分类特征迁移到两个task所需的分布上来。这样应该会更好?以上只是我自己的拙见,恳请大家批评指正
问题一:
1,3*3的卷积你可以理解为增加了局部上下文信息,如果用1*1的卷积代替,其实没有那么丰富的周边信息了。
2,关于感受野,可以参考一篇文章:cnn中的感受野。3*3的卷积会增加理论感受野,当网络训练好之后,有可能会增大有效感受野,但是1*1对有效感受也没有影响,但是3*3卷积增加其他参数后,对增大有效感受野也会有帮助,从而检测不同大小目标,具体可以参考另一篇文章:目标检测中的Anchor分析之再谈Anchor
问题二:
这个问题可以参考一篇文章:一文读懂RPN和ROI Align。如这篇文章所说,楼主说的问题出现在anchor target generator过程,超过图像边界的anchor会直接删除。在proposal generator过程,对于网络预测框,越过图像边界的框,会根据图像大小进行截断。这是两个过程,给你解释的人弄混了,建议仔细阅读一下推荐的文章。
必读好文
1. https://blog.csdn.net/mljsuc/article/details/90447800
faster rcnn具体参数。这篇文章梳理里faster rcnn中使用到的所有参数信息,十分详细。
其中描述到:
| 171 | ZF模型在feature层的感受野 |
| 228 | VGG模型在feature层的感受野 |
2. 一文读懂faster rcnn
https://zhuanlan.zhihu.com/p/31426458
知乎上关于faster rcnn的入门好文。
原文:https://www.cnblogs.com/durui0558/p/12953940.html