迭代器模式是一种使用频率非常高的设计模式,迭代器用于对一个聚合对象进行遍历。通过引入迭代器可以将数据的遍历功能从聚合对象中分离出来,聚合对象只负责存储数据,聚合对象只负责存储数据,而遍历数据由迭代器来完成。
一个聚合对象,如一个列表(List)或者一个集合(Set),应该提供一种方法来让别人可以访问它的元素,而又不需要暴露它的内部结构。此外,针对不同的需要,可能还要以不同方式遍历整个聚合对象,但是我们不希在聚合对象的抽象层接口中充斥着各种不同遍历的操作。怎样遍历一个聚合对象,又不需要了解聚合对象的内部结构,还能提供多种不同的遍历方式,这就是迭代器模式所要解决的问题。
迭代器模式中,提供一个外部的迭代器来对聚合对象进行访问和遍历,迭代器定义一个访问该聚合元素的接口,并且可以跟踪当前遍历对象,了解哪些元素已经遍历过而哪些没有。
提供一种方法来访问聚合对象,而不用暴露这个对象的内部表示,其别名为游标(Cursor)。迭代器模式是一种对象行为模式。
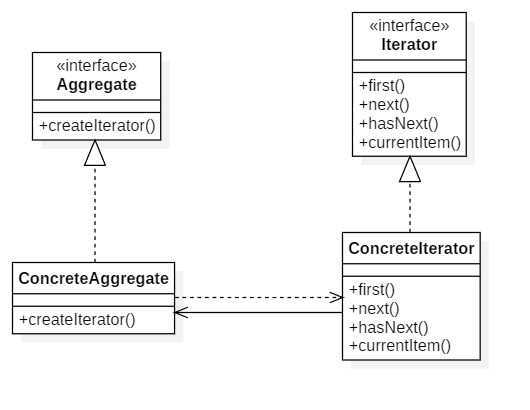
Iterator(抽象迭代器)
抽象迭代器定义了访问和遍历元素的接口,一般声明以下方法:
ConcreteIterator(具体迭代器)
具体迭代器实现了抽象迭代器接口,完成对聚合对象的遍历,同时在对聚合进行遍历时跟踪其当前位置
Aggregate(抽象聚合类)
抽象聚合类用于存储对象,并定义创建相应迭代器对象的接口,声明一个 createIterator() 方法用于创建一个迭代器对象
ConcreteAggregate(具体聚合类)
具体聚合类实现了创建相应迭代器的接口,实现了在聚合类中声明的 createIterator() 方法,该方法返回一个与具体聚合对应的具体迭代器 ConcreteIterator 实例
存储数据是聚合对象的最基本职责,其中包含存储数据的类型、存储空间的大小、存储空间的分配,以及存储的方式和顺序。然而,聚合对象除了能存储数据外,还必须提供遍历访问其内部数据的方式,同时这些遍历方式可能会根据不同的情形提供不同的实现。
因此,聚合对象主要有两个职责:一是存储内部数据;二是遍历内部数据。前者是聚合对象的基本功能,后者是可以分离的。根据单一职责原则,对象承担的职责越少,对象的稳定性就越好,我们将遍历聚合对象中数据的行为提取出来,封装到一个迭代器中,通过专门的迭代器来遍历聚合对象的内部数据。迭代器模式是单一职责原则的完美体现。
下面通过一个简单的自定义迭代器来分析迭代器模式的结构
首先定义一个简单的迭代器去接口
public interface MyIterator {
void first(); // 访问第一个元素
void next(); // 访问下一个元素
boolean isLast(); // 判断是否是最后一个元素
Object currentItem(); // 获取当前元素
}
然后需要定义一个聚合接口
public interface MyCollection {
// 返回一个 MyIterator 迭代器对象
MyIterator createIterator();
}
定义好抽象层之后,我们需要定义抽象迭代器接口和抽象聚合接口的实现类,一般将具体迭代器类作为具体聚合类的内部类,从而迭代器可以实现直接访问聚合类中的数据
public class NewCollection implements MyCollection {
private Object[] obj = {"dog", "pig", "cat", "monkey", "pig"};
public MyIterator createIterator() {
return new NewIterator();
}
private class NewIterator implements MyIterator {
private int currentIndex = 0;
public void first() {
currentIndex = 0;
}
public void next() {
if(currentIndex < obj.length) {
currentIndex++;
}
}
public boolean isLast() {
return currentIndex == obj.length;
}
public void currentItem() {
return obj[currentIndex];
}
}
}
NewCollection 类实现了 MyCollection 接口,实现了 createIterator() 方法,同时定义了一个数组用于存储数据元素,还定义了一个实现了 MyIterator 接口的内部类,索引变量 currentIndex 用于保存所操作的数组元素的下标值。客户端代码如下:
public class Client {
public static void process(MyCollection collection) {
MyIterator i = collection.createIterator();
while(!i.isLast()) {
System.out.println(i.currentItem().toString());
i.next();
}
}
public static void main(String args[]) {
MyCollection collection = new NewCollection();
process(collection);
}
}
除了使用内部类实现之外,也可以使用常规的方式来实现迭代器
public class ConcreteIterator implements Iterator {
private ConcreteAggregate objects;
public ConcreteIterator(ConcreteAggregate objects) {
this.objects = objects;
}
public void first() {
...
}
public void next() {
...
}
public boolean isLast() {
...
}
public void currentItem() {
...
}
}
public class ConcreteAggregate implements Aggregate {
...
public Iterator createIterator() {
return new ConcreteIterator(this);
}
}
迭代器模式中应用了工厂方法模式,聚合类充当工厂类,而迭代器充当产品类
迭代器模式优点:
迭代器模式缺点:
在以下情况可以使用迭代器模式:
Java 中的集合框架 Collections,其基本接口层次结构如图
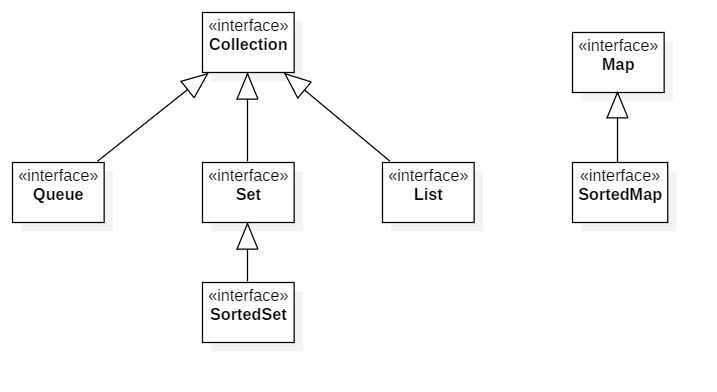
Collection 是所有集合类的根接口,它的主要方法如下:
boolean add(Object c);
boolean addAll(Collection c);
boolean remove(Object o);
boolean removeAll(Collection c);
boolean remainAll(Collection c);
Iterator iterator();
Collection 的 iterator() 方法返回一个 java.util.Iterator 类型的对象,而其子接口 java.util.List 的 listIterator() 方法返回一个 java.util.ListIterator 类型的对象,ListIterator 是 Iterator 的子类,它们构成了 Java 语言对迭代器模式的支持。
在 JDK 中,Iterator 接口具有如下三个基本方法:
Java 迭代器可以理解为它工作时在聚合对象的各个元素之间,每调用一次 next() 方法,迭代器便越过下个元素,并且返回它刚越过的那个元素的地址引用。

在第一个 next() 方法被调用时,迭代器由“元素1”与“元素2”之间移动至“元素2”与“元素3”之间,跨越了“元素2”,因此 next() 方法将返回对“元素2”的引用;在第二个 next() 方法被调用时,迭代器由“元素2”与“元素3”之间移至“元素3”与“元素4”之间,next() 方法将返回对“元素3”的引用,此时调用 remove() 方法,则可将”元素3“删除。
需要注意的是,next() 方法与 remove() 方法的调用是相互关联的。如果调用 remove() 之前没有先对 next() 进行调用,那么将抛出异常,因为没有任何可供删除的元素
原文:https://www.cnblogs.com/Yee-Q/p/12957360.html