1. 进入DB
比如我的是 use hadoop;
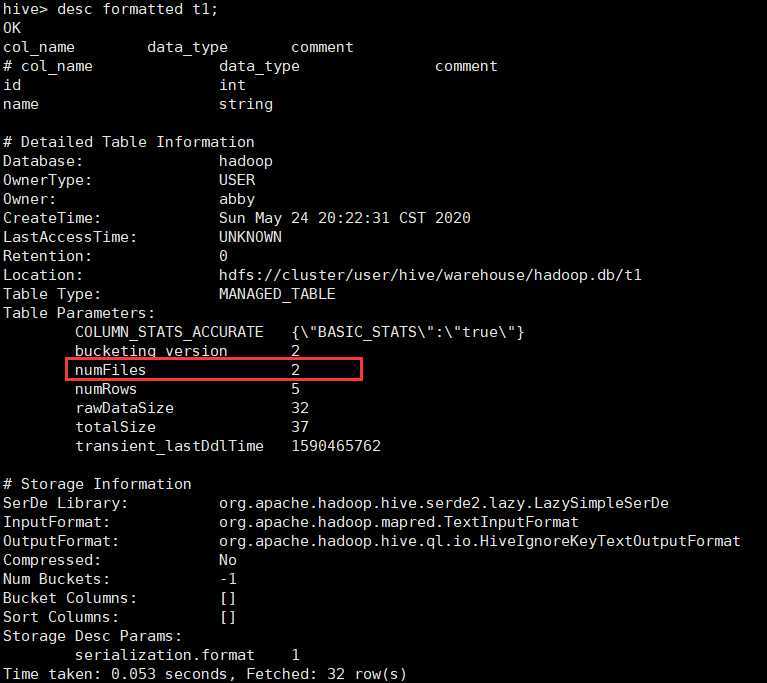
2.找到需要查看的表 ,
执行 desc formatted t1;
碎片文件太多 , 会让map 过多 ,然而启动map
极其耗费资源 , 甚至比计算都要费时间 .
Hive 查看表的文件个数(用于分析小文件)
原文:https://www.cnblogs.com/alpha-cat/p/12964702.html