不需要指定数组的大小,也不需要提前声明,直接赋值即可声明数组:$arr[‘a‘]=1,或$arr[]=1
合并数组且key相同时,array_merge()保留最后一个value,"+"保留第一个value
键为字符串且为标准的integer表示时,会转为整型。例如"8"会转为8,"08"不会转为8
浮点数截取为整型,null为空字符串,true为1,false为0,可为负数
key为字符串时要加引号,为整型、变量和常量时不加引号
$a = [‘a‘, ‘b‘=>‘b‘, ‘c‘, 100=>‘d‘, ‘e‘];
相当于 [0=>‘a‘, ‘b‘=>‘b‘, 1=>‘c‘, 100=>‘d‘, 101=>‘e‘]
可以看成逐个往数组里添加元素,所以key重复时值会被覆盖
$arr = [‘a‘=>1,‘a‘=>2]; 等价于 $arr[‘a‘]=1; $arr[‘a‘]=2;
key可以是中文
foreach($arr as $k => &$v) 改变$v可以作用到$arr上
$a[‘b‘] = null;
isset( $a[‘b‘] ) //false
array_key_exists(‘b‘, $a) //true
操作符
== != 相等,键值对相同
=== !== 全等,键值对相同且顺序相同
each()等指针函数:
while( list($k, $v) = each($arr) ){ } //$k和$v同上,只是不能直接修改$v
//each()最后返回false
$e=each($arr)返回$arr当前元素的键值对,并向后移动数组指针,指针移到最后返回false。
键值对被返回为含有4个元素的数组$e,$e[0]、$e[‘key‘]为数组的key,$e[1]、$e[‘value‘]为数组的value
each()执行完后,数组指针指向最后,如果想再次使用each(),需要reset()重置数组指针。
foreach()每次执行前会自动重置数组指针
list($a,$b)=$arr不是函数,是语言结构,将数组元素赋给变量
只支持索引从0开始的索引数组
list($k, &$v)是非法的,list()=false为false
控制数组内部指针:
key($arr)、current($arr)/pos($arr) //key、value
prev($arr)、next($arr) //前移、后移
reset($arr)、end($arr) //移到最前、最后
//后四个移动指针的函数,返回值为移动后的指针指向的元素的value
//指针越界,key为null,value为false
计算
count — 计算数组中的单元数目,或对象中的属性个数
sizeof — count 的别名
array_count_values — 统计数组中所有的值
array_sum — 对数组中所有值求和
array_product — 计算数组中所有值的乘积
新建、修改 数组
array — 新建一个数组
range — 根据范围创建数组,包含指定的元素
array_fill — 用给定的值填充数组
array_fill_keys — 使用指定的键和值填充数组
compact — 建立一个数组,包括变量名和它们的值
array_pad — 以指定长度将一个值填充进数组
array_values — 返回数组中所有的值
array_column — 返回数组中指定的一列
array_combine — 创建一个数组,用一个数组的值作为键,另一个数组的值作为值
array_flip — 交换数组中的键和值
shuffle — 打乱数组
array_reverse — 返回单元顺序相反的数组
array_unique — 移除数组中重复的值
array_slice — 从数组中取出一段
array_splice — 去掉数组中的某一部分并用其它值取代
array_replace — 使用传递的数组替换第一个数组的元素
array_chunk — 将一个数组分割成多个
回调
array_map — 为数组的每个元素应用回调函数
array_filter — 用回调函数过滤数组中的单元
array_walk_recursive — 对数组中的每个成员递归地应用用户函数
array_walk — 使用用户自定义函数对数组中的每个元素做回调处理
array_reduce — 用回调函数迭代地将数组简化为单一的值
array_replace_recursive — 使用传递的数组递归替换第一个数组的元素
排序
sort — 对数组排序
rsort — 对数组逆向排序
usort — 使用用户自定义的比较函数对数组中的值进行排序
asort — 对数组进行排序并保持索引关系
arsort — 对数组进行逆向排序并保持索引关系
uasort — 使用用户自定义的比较函数对数组中的值进行排序并保持索引关联
ksort — 对数组按照键名排序
krsort — 对数组按照键名逆向排序
uksort — 使用用户自定义的比较函数对数组中的键名进行排序
array_multisort — 对多个数组或多维数组进行排序
natcasesort — 用“自然排序”算法对数组进行不区分大小写字母的排序
natsort — 用“自然排序”算法对数组排序
检测 键、值 是否存在
in_array — 检查数组中是否存在某个值
array_search — 在数组中搜索给定的值,如果成功则返回首个相应的键名
key_exists — 别名 array_key_exists
array_key_exists — 检查数组里是否有指定的键名或索引
返回、修改 键
key — 从关联数组中取得键名
array_key_first — Gets the first key of an array
array_key_last — Gets the last key of an array
array_keys — 返回数组中部分的或所有的键名
array_change_key_case — 将数组中的所有键名修改为全大写或小写
键、值 导出到变量
extract — 从数组中将变量导入到当前的符号表
list — 把数组中的值赋给一组变量
插入、删除、取出
array_rand — 从数组中随机取出一个或多个单元
array_shift — 将数组开头的单元移出数组
array_unshift — 在数组开头插入一个或多个单元
array_pop — 弹出数组最后一个单元(出栈)
array_push — 将一个或多个单元压入数组的末尾(入栈)
合并
array_merge_recursive — 递归地合并一个或多个数组
array_merge — 合并一个或多个数组
差集
array_diff — 计算数组的差集
array_diff_assoc — 带索引检查计算数组的差集
array_diff_key — 使用键名比较计算数组的差集
array_udiff_assoc — 带索引检查计算数组的差集,用回调函数比较数据
array_udiff_uassoc — 带索引检查计算数组的差集,用回调函数比较数据和索引
array_udiff — 用回调函数比较数据来计算数组的差集
array_diff_uassoc — 用用户提供的回调函数做索引检查来计算数组的差集
array_diff_ukey — 用回调函数对键名比较计算数组的差集
交集
array_uintersect_assoc — 带索引检查计算数组的交集,用回调函数比较数据
array_uintersect_uassoc — 带索引检查计算数组的交集,用单独的回调函数比较数据和索引
array_uintersect — 计算数组的交集,用回调函数比较数据
array_intersect_assoc — 带索引检查计算数组的交集
array_intersect_key — 使用键名比较计算数组的交集
array_intersect_uassoc — 带索引检查计算数组的交集,用回调函数比较索引
array_intersect_ukey — 用回调函数比较键名来计算数组的交集
array_intersect — 计算数组的交集
指针
each — 返回数组中当前的键/值对并将数组指针向前移动一步
current — 返回数组中的当前单元
pos — current 的别名
reset — 将数组的内部指针指向第一个单元
end — 将数组的内部指针指向最后一个单元
prev — 将数组的内部指针倒回一位
next — 将数组中的内部指针向前移动一位
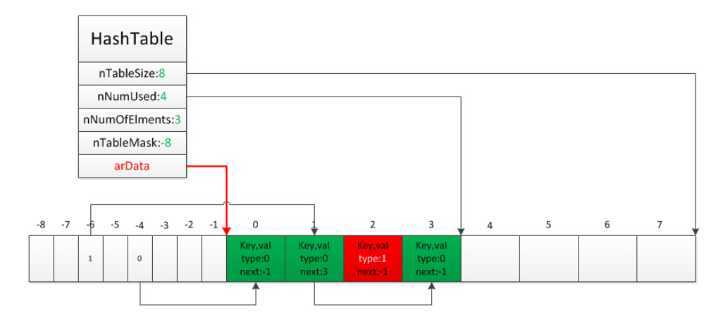
插入:在右侧插入,并计算hash值,将下标存入左侧索引数组中。
数组里全都是key=>value形式,$arr[]=‘abc‘,其实是$arr[nNextFreeElement++]=‘abc‘
$arr[100]=‘abc‘,会插入100=>‘abc‘,并将nNextFreeElement设为101
哈希碰撞:zval里指向下一个节点的下标
扩容:哈希表的大小为2^n,插入时如果容量不够则首先检查已删除元素所占比例,如果达到阈值(nNumUsed - nNumOfElements > nNumOfElements >> 5),则将已删除元素移除,重建索引,如果未到阈值则进行扩容操作,扩大为当前大小的2倍,将当前Bucket数组复制到新的空间,然后重建索引。
删除:修改节点状态,将zval设置为IS_UNDEF。删除之后再插入相同的key,
不会改变已删除节点的状态,而是在右侧新插入一个节点。
遍历:从左往右遍历,即按插入顺序,与数字下标无关。
以下数据结构不是从php源码里摘抄出来的,仅作参考
typedef struct _Bucket {
zval val;
zend_ulong h; /* hash value (or numeric index) */
zend_string *key; /* string key or NULL for numerics */
} Bucket;
typedef struct _zend_array HashTable;
struct _zend_array {
zend_refcounted_h gc;
union {
struct {
ZEND_ENDIAN_LOHI_4(
zend_uchar flags,
zend_uchar nApplyCount,
zend_uchar nIteratorsCount,
zend_uchar reserve)
} v;
uint32_t flags;
} u;
uint32_t nTableMask; //哈希值计算掩码,等于nTableSize的负值(nTableMask = ~nTableSize + 1)
Bucket *arData; //存储元素数组,指向第一个Bucket
uint32_t nNumUsed; //已用Bucket数
uint32_t nNumOfElements; //哈希表已有元素数
uint32_t nTableSize; //哈希表总大小,为2的n次方
uint32_t nInternalPointer;
zend_long nNextFreeElement; //下一个可用的数值索引
dtor_func_t pDestructor;
};
原文:https://www.cnblogs.com/ts65214/p/12967107.html