mapreduce的思想主要分为map和reduce
map:拆分阶段,将复杂的任务拆分成并行的多个小任务(每个任务的执行过程一样)
reduce:聚合阶段 map阶段处理好的数据交由reduce阶段组合。
完整的mapreduce包括三个部分
applicationMaster:分配任务,请求资源
mapTask:map阶段数据处理
reduceTask:数据整合
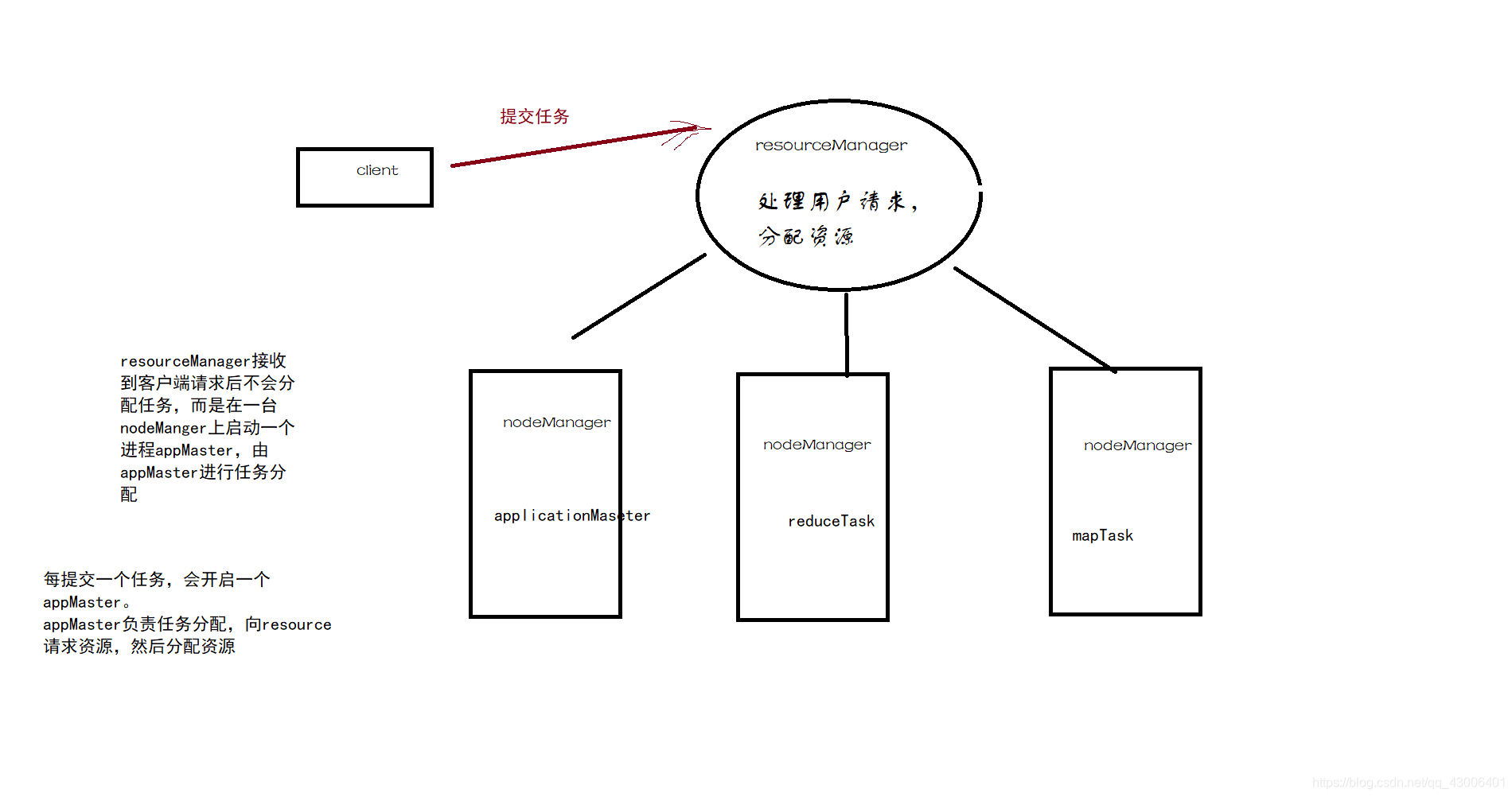
1、客户端提交任务
2、resourceManager在某一台nodeManager上启动一个applicationMaster进程
(applicationMaster负责任务的分配,向recourseManager请求资源以及分配资源)
3、appMaster向多个nodeManager分配任务,每个nodeManager上可能运行mapTask或者reduceTask
(map阶段)
1、读取文件,设置inputFormat ,将数据解析成j键值对k1,v1
2、自定义map逻辑,将第一步的键值对转换成k2,v2
(shuffer阶段)
3、分区 (相同的k交给同一个reduce进行处理,key合并,v组装成集合)
4、排序
5、规约
6、分组
(reduce阶段)
7、自定义reduce逻辑,将k2,v2进行数据合并,形成新的k3,v3
8、输出文件,设置outputformat,存入文件
public class CountMain extends Configured implements Tool {
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
int run = ToolRunner.run(configuration, new CountMain(), args);
}
@Override
public int run(String[] args) throws Exception {
//读取文件
Job job = Job.getInstance(super.getConf(), "world");
TextInputFormat.addInputPath(job, new Path("hdfs://node01:8020/worldCount"));
job.setInputFormatClass(TextInputFormat.class);
//自定义map逻辑
job.setMapperClass(CountMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//3-6
//自定义reduce逻辑
job.setReducerClass(CountReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//输出
TextOutputFormat.setOutputPath(job, new Path("hdfs://node01:8020/world1"));
job.setOutputFormatClass(TextOutputFormat.class);
boolean b = job.waitForCompletion(true);
return b ? 0 : 1;
}
}
package TestworldCount;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class CountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String string = value.toString();
String[] split = string.split(",");
for (String s : split) {
context.write(new Text(s), new IntWritable(1));
}
}
}
package TestworldCount;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class CountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int j = 0;
for (IntWritable value : values) {
j += value.get();
}
context.write(key, new IntWritable(j));
}
}
原文:https://www.cnblogs.com/hatcher-h/p/12968715.html