查询优化是查询处理中的重要一环,对关系DB尤其如此。
查询的处理过程
- 解释方式执行:优化占用执行时间
- 编译方式执行:优化不占执行时间
代数优化
对查询进行等效变换,降低中间结果的大小。
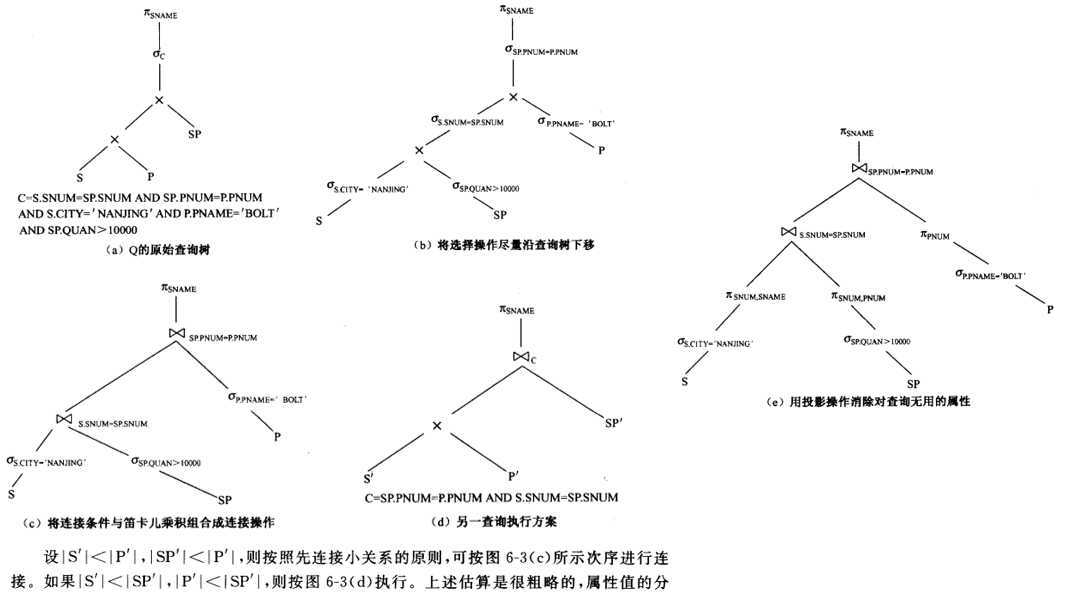
先做选择、投影(消去大量记录和属性);先做小关系间的连接,再做大关系的连接。还可以找出查询中的公共表达式,避免重复运算。
常用变换规则

具体优化过程
-
将SQL语句转化为查询树
-
尽量下压选择操作(向下派发WHERE条件)
-
优先连接小的关系
-
用投影消除无用属性
例子:
SELECT SNAME FROM S,P,SP WHERE S.SNUM=SP.SNUM
AND SP.PNUM=P.PNUM AND S.CITY=‘NANJING‘
AND P.PNAME=‘BOLT‘ AND SP.QUAN>10000 --- 查询在南京的商店螺栓库存大于10000的商店名
有嵌套的复杂情况
对于嵌套查询,优化比较复杂。
- 嵌套与上层无关:从最低层开始,逐层进行等效优化
- 嵌套与上层有关:可以采用代入法
存取路径优化
之前讨论的是对查询语句进行等效变换实现优化,这里讨论与物理存取路径相关的优化。
选择操作
顺序扫描是最基础的,尽量利用索引、散列。
- 对于小关系,顺序扫描
- 如果没有索引(包括簇集索引)、散列可用,或者能选出的元组数占比较大,可以顺序扫描(命中率较高)
- 对于主键的等值选择(WHERE PRI=XXX),优先使用主键的索引或散列
- 对于非主键的等值选择,若能选出的元组数较少,可以用无序索引,否则不如用簇集索引或顺序扫描(查表开销还不如顺序扫描)
- 对于范围条件(非等值选择),先通过索引找到范围边界,然后沿合适方向进行搜索。如果能选出的元组数较多,不如簇集索引或顺序扫描
- 对于AND,优先选用多个属性构成的索引,最坏顺序扫描
- 对于OR,只能按各个条件分别选出元组集,再求并。而且,只要有一个条件没有合适的存取路径,就只能用顺序扫描(因为必然要顺序扫描)
连接操作
连接操作的开销很大,是优化的重点。
-
嵌套循环法:通过双重循环进行连接
假设R和S进行连接,双重循环中,R只要扫描一次,S要扫描多次,称R为外关系(外循环的关系),S为内关系(内循环的关系)。则有如下结论:
- S的扫描次数(扫完全体算一次)是R的物理块数\(b_R=\lceil n/p_R \rceil\),pR称为R的块因子,即每个物理块所含的元组数
- 这意味着,如果pR0足够大,或者每次能取的bR足够多,也就是缓冲区足够大,就可以减少S的扫描次数
- 用嵌套循环法进行连接时访问的最小物理块数为\(C=b_R+\lceil b_R/(n_B-1) \rceil b_S\),nB为可用的缓冲区块数。即给外关系分配nB-1块缓冲是最佳策略。该式可以这样理解:外关系的每一块给bR贡献1,每一块都需要bS全体调入一次,共调入\(\lceil b_R/(n_B-1) \rceil\)次
- 从上式可以看出,应将物理块少的关系作为外关系
-
利用索引或散列寻找匹配元组
嵌套循环法内关系上要做多次顺序扫描,若内关系上有合适的存取路径,可以避免顺序扫描。
但注意:
- 当每次循环所选的匹配元组数在内关系中占有较大比例时,用无序索引甚至还不如用顺序扫描的方法
- 内关系的连接属性上有簇集索引时,索引对减少连接所需I/O次数的作用最明显
-
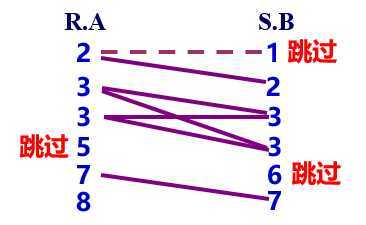
排序归并
如果R和S已经按连接属性排序,可以按序比较R.A和S.B来找出匹配元组(类似于归并排序的归并过程)
-
散列连接
连接属性有相同的值域,选择一个相同的散列函数,把R和S按R.A和S.B散列到同一散列文件中,则可能符合连接条件的元组必然落到同一桶中,对桶中的元素进行判定(因为散列可能冲突)并连接即可。
为了减少IO次数,可以使用元组的tid代替元组本身,以缩小散列大小,争取一次扫描完成。
上述几种方法各有优缺点,选用时可参考如下的启发式规则:
- R、S按连接属性排序的,优先用排序归并;有一个排序的,可考虑排序另一个
- 一个关系有索引(特别是簇集索引)或散列的,可以把另一个关系做外关系,则内关系可避免多次扫描
- 关系较小又不具备上述条件的,可以嵌套循环
- 都不具备的,可用散列连接
投影操作
一般与选择、连接同时进行,无需附加的I/O开销。
如果需要消除重复元组,可以用排序或散列等方法。
集合操作
- 笛卡尔积要尽量少用
- 交并差操作可以先将R、S排序后进行扫描
- 交并差操作也可以用散列。每个桶中,对于并,不再插入重复元组;对于交,选取重复元组;对于差,从桶中取消与S重复的元组。
组合操作
有时,多个操作组合起来同时进行,如投影和选择操作组合起来执行,可提高效益。
结束语
执行前进行优化称为静态优化,只能利用统计数据,不一定准。
执行时进行优化称为动态优化,用实际执行结果估算代价,比较符合实际;但每次执行都要优化,不适于编译实现,也增加了执行时间;只能利用统计数据,有时不一定准;要等待中间结果,增加了等待时间和数据的相关性,不利于并行性。
《数据库原理》课程笔记 (Ch06-查询处理和优化)
原文:https://www.cnblogs.com/zxuuu/p/12981185.html