假设现在有几条数据,是以记事本文档的形式交到我们的手中
姓名:涂白竹 性别:女 年龄:15 班级:1班
姓名:江夜梅 性别:女 年龄:16 班级:1班
姓名:奉轩 性别:男 年龄:15 班级:1班
我们的任务是将他们录入到数据库中,并且这几个学生都要转到2班。怎么做?假设数据表已经建立好了。
第一思路:读取文档,通过换行符分割这几行数据,再将每条子串的倒数第二个字符替换为2.
代码如下:
StreamReader sr = new StreamReader("DOM演示\\学生数据.txt",Encoding.Default); string s = sr.ReadToEnd(); sr.Close(); string[] students = s.Split(new String[]{"\n"},StringSplitOptions.None); foreach (string item in students) { string temp = item.Replace(item.Substring(item.IndexOf("班级:") + 3, item.Length - item.IndexOf("班级:") - 3), "2班"); Console.WriteLine(temp); }
运行结果:
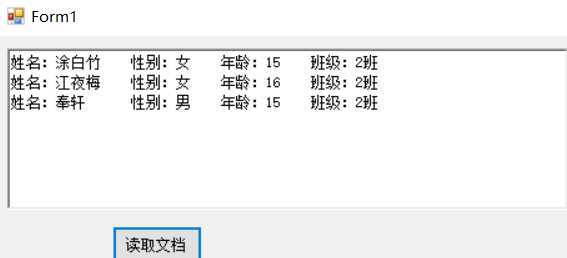
可以说非常麻烦。而且如果要改的是年龄呢?如果只是改(江夜梅)的年龄呢?那又要改代码了。每次调整需求就要改代码。
为了提高代码复用率,不如写成函数。
按照要求,是改任意一个人的任意属性。问题在于任何属性值的长度是不固定的。没办法像前面一样截取后2位更改。
思考一下XML或HTML是怎么做的。在值的前后加标记。
于是我们也仿照HTML制定一个规范:
姓名,必须在<name></name>中间
性别,必须在<sex></sex>中间
年龄,必须在<sex></sex>中间
班级,必须在<sex></sex>中间
现在来改造文档,用这种格式写
<name>涂白竹</name><sex>女</sex><age>15</age><class>1班</class> <name>江夜梅</name><sex>女</sex><age>16</age><class>1班</class> <name>奉轩</name><sex>男</sex><age>15</age><class>1班</class>
现在再来改造代码:
public void update(string propertyName,string propertyValue) { StreamReader sr = new StreamReader("DOM演示\\规范化学生数据.txt", Encoding.Default); string s = sr.ReadToEnd(); sr.Close(); string[] students = s.Split(new String[] { "\n" }, StringSplitOptions.None); foreach (string item in students) { int startIndex = item.IndexOf("<" + propertyName + ">") + propertyName.Length + 2; int endIndex = item.IndexOf("</" + propertyName + ">"); int valueLength = endIndex - startIndex; string temp = item.Replace(item.Substring(item.IndexOf("<" + propertyName + ">") + propertyName.Length + 2, valueLength), propertyValue); Console.WriteLine(temp); } }
调用:update("age", "20");
//update("class", "2班");
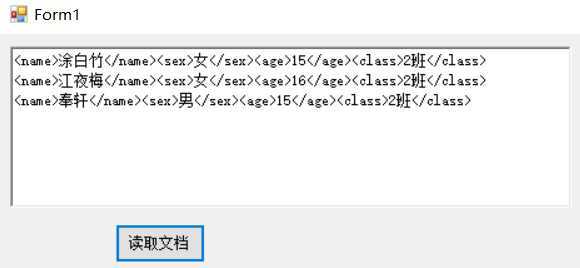
不如专门写一个函数,去掉字符串”<“和">"之间的字符。然后在update()中每次输出时调用。
函数:获得指定串的所有位置
引用自:https://blog.csdn.net/iteye_19871/article/details/81495660
public int[]GetSubStrCountInStr(String str,String substr,int StartPos) { int foundPos=-1; int count=0; List<int> foundItems=new List<int>(); do { foundPos=str.IndexOf(substr,StartPos); if(foundPos>-1) { StartPos=foundPos+1; count++; foundItems.Add(foundPos); } }while(foundPos>-1&&StartPos<str.Length); return((int[])foundItems.ToArray()); }
调用这个函数完成对标记的去除,其实是反过来,只取值
public string remove(string student) { int[] left = GetSubStrCountInStr(student, "<", 0); int[] right = GetSubStrCountInStr(student, ">", 0); string newString = ""; for (int i=0,j=1;i<left.Length-1;i++,j++) { newString += student.Substring(right[i]+1, left[j] - right[i]-1)+"\t"; } return newString; }
然后在update()中调用
public void update(string propertyName,string propertyValue) { StreamReader sr = new StreamReader("DOM演示\\规范化学生数据.txt", Encoding.Default); string s = sr.ReadToEnd(); sr.Close(); string[] students = s.Split(new String[] { "\n" }, StringSplitOptions.None); foreach (string item in students) { int startIndex = item.IndexOf("<" + propertyName + ">") + propertyName.Length + 2; int endIndex = item.IndexOf("</" + propertyName + ">"); int valueLength = endIndex - startIndex; string temp = item.Replace(item.Substring(item.IndexOf("<" + propertyName + ">") + propertyName.Length + 2, valueLength), propertyValue); //string newString = remove(temp);<---这里调用 Console.WriteLine(newString); } }
现在就能实现对任意属性的修改了。
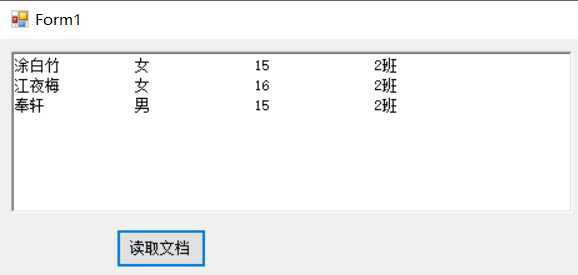
虽然修改成功了,但并没有指定特定的个人。当然,可以继续修改这个remove()函数。
我们的操作一共有查看(select),新增(insert),删除(delete),修改(update)。也就是说,每个操作都要写一个函数。
现在要考虑的是学生的属性个数并不确定,可能会改变。
不如就像XML做的那样,把这些属性都看作节点,学生就是这些属性节点的父节点。这样就可以随意增添子节点(属性)。
那采用递归的方式比较好,采用设计模式里面的组合模式。假设类名叫Node,里面包含两个字段nodeName,txtValue外加一个集合child
原来的的格式不足之处在于是通过换行符“\n”来区分不同记录的,当两条记录处于同一行就会出问题。而且这样不利于体现结构。
现在改成就像XML一样
<students> <student> <name>涂白竹</name> <sex>女</sex> <age>15</age> <class>1班</class> </student> <student> <name>江夜梅</name> <sex>女</sex> <age>16</age> <class>1班</class> </student> <student> <name>奉轩</name> <sex>男</sex> <age>15</age> <class>1班</class> </student> </students>
这样,从根节点开始,每个子节点<student>就是一条记录。
现在就可以利用Node来在内存中加载数据了。
利用有限状态自动机来读取文档,并在这个过程中保存数据,用于在正确结束后生成文档对象。
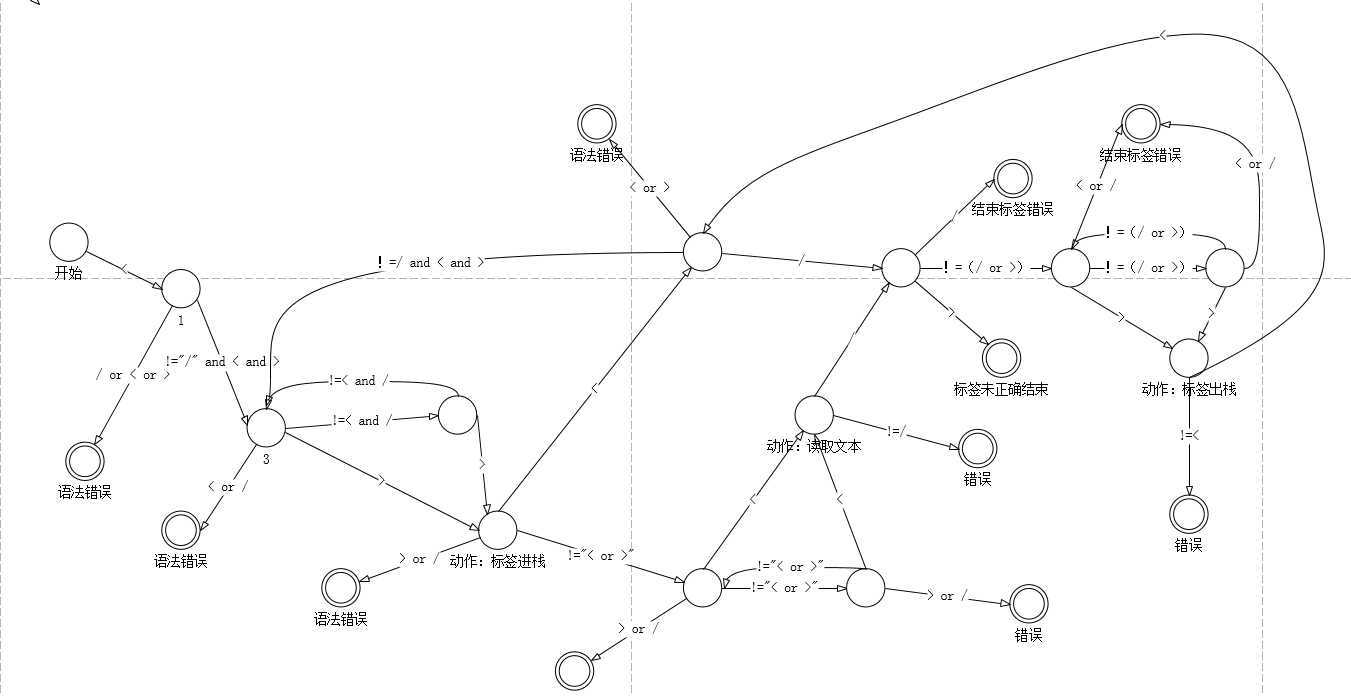
接下来就是实现了。待更新。。。
者
原文:https://www.cnblogs.com/ggtc/p/12982302.html