MongoDB 是目前最流行的 NoSQL 数据库之一,使用的数据类型 BSON(类似 JSON)。
MongoDB 数据库安装与介绍可以查看我们的 MongoDB 教程。
Python 要连接 MongoDB 需要 MongoDB 驱动,这里我们使用 PyMongo 驱动来连接。
pip 是一个通用的 Python 包管理工具,提供了对 Python 包的查找、下载、安装、卸载的功能。
安装 pymongo:
$ python3 -m pip3 install pymongo
更新 pymongo 命令:
$ python3 -m pip3 install --upgrade pymongo
接下来我们可以创建一个测试文件 demo_test_mongodb.py,代码如下:
import pymongo
执行以上代码文件,如果没有出现错误,表示安装成功。
创建数据库需要使用 MongoClient 对象,并且指定连接的 URL 地址和要创建的数据库名。
如下实例中,我们创建的数据库 runoobdb :
import pymongo myclient = pymongo.MongoClient("mongodb://localhost:27017/") mydb = myclient["runoobdb"]
注意: 在 MongoDB 中,数据库只有在内容插入后才会创建! 就是说,数据库创建后要创建集合(数据表)并插入一个文档(记录),数据库才会真正创建。
我们可以读取 MongoDB 中的所有数据库,并判断指定的数据库是否存在:
import pymongo myclient = pymongo.MongoClient(‘mongodb://localhost:27017/‘) dblist = myclient.list_database_names() # dblist = myclient.database_names() if "runoobdb" in dblist: print("数据库已存在!")
注意:database_names 在最新版本的 Python 中已废弃,Python3.7+ 之后的版本改为了 list_database_names()。
MongoDB 中的集合类似 SQL 的表。
MongoDB 使用数据库对象来创建集合,实例如下:
import pymongo myclient = pymongo.MongoClient("mongodb://localhost:27017/") mydb = myclient["runoobdb"] mycol = mydb["sites"]
注意: 在 MongoDB 中,集合只有在内容插入后才会创建! 就是说,创建集合(数据表)后要再插入一个文档(记录),集合才会真正创建。
我们可以读取 MongoDB 数据库中的所有集合,并判断指定的集合是否存在:
import pymongo myclient = pymongo.MongoClient(‘mongodb://localhost:27017/‘) mydb = myclient[‘runoobdb‘] collist = mydb. list_collection_names() # collist = mydb.collection_names() if "sites" in collist: # 判断 sites 集合是否存在 print("集合已存在!")
注意:collection_names 在最新版本的 Python 中已废弃,Python3.7+ 之后的版本改为了 list_collection_names()。
1.添加数据
集合中插入文档使用 insert_one() 方法,该方法的第一参数是字典 name => value 对。
以下实例向 sites 集合中插入文档:
import pymongo myclient = pymongo.MongoClient("mongodb://localhost:27017/") mydb = myclient["runoobdb"] mycol = mydb["sites"] mydict = { "name": "RUNOOB", "alexa": "10000", "url": "https://www.runoob.com" } x = mycol.insert_one(mydict) print(x) print(x)
执行输出结果为:
<pymongo.results.InsertOneResult object at 0x10a34b288>
insert_one() 方法返回 InsertOneResult 对象,该对象包含 inserted_id 属性,它是插入文档的 id 值。
import pymongo myclient = pymongo.MongoClient(‘mongodb://localhost:27017/‘) mydb = myclient[‘runoobdb‘] mycol = mydb["sites"] mydict = { "name": "Google", "alexa": "1", "url": "https://www.google.com" } x = mycol.insert_one(mydict) print(x.inserted_id)
执行输出结果为:
5b2369cac315325f3698a1cf
如果我们在插入文档时没有指定 _id,MongoDB 会为每个文档添加一个唯一的 id。
集合中插入多个文档使用 insert_many() 方法,该方法的第一参数是字典列表。
import pymongo myclient = pymongo.MongoClient("mongodb://localhost:27017/") mydb = myclient["runoobdb"] mycol = mydb["sites"] mylist = [ { "name": "Taobao", "alexa": "100", "url": "https://www.taobao.com" }, { "name": "QQ", "alexa": "101", "url": "https://www.qq.com" }, { "name": "Facebook", "alexa": "10", "url": "https://www.facebook.com" }, { "name": "知乎", "alexa": "103", "url": "https://www.zhihu.com" }, { "name": "Github", "alexa": "109", "url": "https://www.github.com" } ] x = mycol.insert_many(mylist) # 输出插入的所有文档对应的 _id 值 print(x.inserted_ids)
输出结果类似如下:
[ObjectId(‘5b236aa9c315325f5236bbb6‘), ObjectId(‘5b236aa9c315325f5236bbb7‘), ObjectId(‘5b236aa9c315325f5236bbb8‘), ObjectId(‘5b236aa9c315325f5236bbb9‘), ObjectId(‘5b236aa9c315325f5236bbba‘)]
insert_many() 方法返回 InsertManyResult 对象,该对象包含 inserted_ids 属性,该属性保存着所有插入文档的 id 值。
执行完以上查找,我们可以在命令终端,查看数据是否已插入:

我们也可以自己指定 id,插入,以下实例我们在 site2 集合中插入数据,_id 为我们指定的:
import pymongo myclient = pymongo.MongoClient("mongodb://localhost:27017/") mydb = myclient["runoobdb"] mycol = mydb["site2"] mylist = [ { "_id": 1, "name": "RUNOOB", "cn_name": "菜鸟教程"}, { "_id": 2, "name": "Google", "address": "Google 搜索"}, { "_id": 3, "name": "Facebook", "address": "脸书"}, { "_id": 4, "name": "Taobao", "address": "淘宝"}, { "_id": 5, "name": "Zhihu", "address": "知乎"} ] x = mycol.insert_many(mylist) # 输出插入的所有文档对应的 _id 值 print(x.inserted_ids)
输出结果为:
[1, 2, 3, 4, 5]
执行完以上查找,我们可以在命令终端,查看数据是否已插入:

SQLite3 可使用 sqlite3 模块与 Python 进行集成。sqlite3 模块是由 Gerhard Haring 编写的。它提供了一个与 PEP 249 描述的 DB-API 2.0 规范兼容的 SQL 接口。您不需要单独安装该模块,因为 Python 2.5.x 以上版本默认自带了该模块。
为了使用 sqlite3 模块,您首先必须创建一个表示数据库的连接对象,然后您可以有选择地创建光标对象,这将帮助您执行所有的 SQL 语句。
以下是重要的 sqlite3 模块程序,可以满足您在 Python 程序中使用 SQLite 数据库的需求。如果您需要了解更多细节,请查看 Python sqlite3 模块的官方文档。
| 序号 | API & 描述 |
|---|---|
| 1 | sqlite3.connect(database [,timeout ,other optional arguments]) 该 API 打开一个到 SQLite 数据库文件 database 的链接。您可以使用 ":memory:" 来在 RAM 中打开一个到 database 的数据库连接,而不是在磁盘上打开。如果数据库成功打开,则返回一个连接对象。 当一个数据库被多个连接访问,且其中一个修改了数据库,此时 SQLite 数据库被锁定,直到事务提交。timeout 参数表示连接等待锁定的持续时间,直到发生异常断开连接。timeout 参数默认是 5.0(5 秒)。 如果给定的数据库名称 filename 不存在,则该调用将创建一个数据库。如果您不想在当前目录中创建数据库,那么您可以指定带有路径的文件名,这样您就能在任意地方创建数据库。 |
| 2 | connection.cursor([cursorClass]) 该例程创建一个 cursor,将在 Python 数据库编程中用到。该方法接受一个单一的可选的参数 cursorClass。如果提供了该参数,则它必须是一个扩展自 sqlite3.Cursor 的自定义的 cursor 类。 |
| 3 | cursor.execute(sql [, optional parameters]) 该例程执行一个 SQL 语句。该 SQL 语句可以被参数化(即使用占位符代替 SQL 文本)。sqlite3 模块支持两种类型的占位符:问号和命名占位符(命名样式)。 例如:cursor.execute("insert into people values (?, ?)", (who, age)) |
| 4 | connection.execute(sql [, optional parameters]) 该例程是上面执行的由光标(cursor)对象提供的方法的快捷方式,它通过调用光标(cursor)方法创建了一个中间的光标对象,然后通过给定的参数调用光标的 execute 方法。 |
| 5 | cursor.executemany(sql, seq_of_parameters) 该例程对 seq_of_parameters 中的所有参数或映射执行一个 SQL 命令。 |
| 6 | connection.executemany(sql[, parameters]) 该例程是一个由调用光标(cursor)方法创建的中间的光标对象的快捷方式,然后通过给定的参数调用光标的 executemany 方法。 |
| 7 | cursor.executescript(sql_script) 该例程一旦接收到脚本,会执行多个 SQL 语句。它首先执行 COMMIT 语句,然后执行作为参数传入的 SQL 脚本。所有的 SQL 语句应该用分号 ; 分隔。 |
| 8 | connection.executescript(sql_script) 该例程是一个由调用光标(cursor)方法创建的中间的光标对象的快捷方式,然后通过给定的参数调用光标的 executescript 方法。 |
| 9 | connection.total_changes() 该例程返回自数据库连接打开以来被修改、插入或删除的数据库总行数。 |
| 10 | connection.commit() 该方法提交当前的事务。如果您未调用该方法,那么自您上一次调用 commit() 以来所做的任何动作对其他数据库连接来说是不可见的。 |
| 11 | connection.rollback() 该方法回滚自上一次调用 commit() 以来对数据库所做的更改。 |
| 12 | connection.close() 该方法关闭数据库连接。请注意,这不会自动调用 commit()。如果您之前未调用 commit() 方法,就直接关闭数据库连接,您所做的所有更改将全部丢失! |
| 13 | cursor.fetchone() 该方法获取查询结果集中的下一行,返回一个单一的序列,当没有更多可用的数据时,则返回 None。 |
| 14 | cursor.fetchmany([size=cursor.arraysize]) 该方法获取查询结果集中的下一行组,返回一个列表。当没有更多的可用的行时,则返回一个空的列表。该方法尝试获取由 size 参数指定的尽可能多的行。 |
| 15 | cursor.fetchall() 该例程获取查询结果集中所有(剩余)的行,返回一个列表。当没有可用的行时,则返回一个空的列表。 |
下面的 Python 代码显示了如何连接到一个现有的数据库。如果数据库不存在,那么它就会被创建,最后将返回一个数据库对象。
import sqlite3 conn = sqlite3.connect(‘test.db‘) print "Opened database successfully"
在这里,您也可以把数据库名称复制为特定的名称 :memory:,这样就会在 RAM 中创建一个数据库。现在,让我们来运行上面的程序,在当前目录中创建我们的数据库 test.db。您可以根据需要改变路径。保存上面代码到 sqlite.py 文件中,并按如下所示执行。如果数据库成功创建,那么会显示下面所示的消息:
$chmod +x sqlite.py $./sqlite.py Open database successfully
下面的 Python 代码段将用于在先前创建的数据库中创建一个表:
import sqlite3 conn = sqlite3.connect(‘test.db‘) print "Opened database successfully" c = conn.cursor() c.execute(‘‘‘CREATE TABLE COMPANY (ID INT PRIMARY KEY NOT NULL, NAME TEXT NOT NULL, AGE INT NOT NULL, ADDRESS CHAR(50), SALARY REAL);‘‘‘) print "Table created successfully" conn.commit() conn.close()
上述程序执行时,它会在 test.db 中创建 COMPANY 表,并显示下面所示的消息:
Opened database successfully
Table created successfully
下面的 Python 程序显示了如何在上面创建的 COMPANY 表中创建记录:
import sqlite3 conn = sqlite3.connect(‘test.db‘) c = conn.cursor() print "Opened database successfully" c.execute("INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) \ VALUES (1, ‘Paul‘, 32, ‘California‘, 20000.00 )") c.execute("INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) \ VALUES (2, ‘Allen‘, 25, ‘Texas‘, 15000.00 )") c.execute("INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) \ VALUES (3, ‘Teddy‘, 23, ‘Norway‘, 20000.00 )") c.execute("INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) \ VALUES (4, ‘Mark‘, 25, ‘Rich-Mond ‘, 65000.00 )") conn.commit() print "Records created successfully" conn.close()
上述程序执行时,它会在 COMPANY 表中创建给定记录,并会显示以下两行:
Opened database successfully
Records created successfully
下面的 Python 程序显示了如何从前面创建的 COMPANY 表中获取并显示记录:
import sqlite3 conn = sqlite3.connect(‘test.db‘) c = conn.cursor() print "Opened database successfully" cursor = c.execute("SELECT id, name, address, salary from COMPANY") for row in cursor: print "ID = ", row[0] print "NAME = ", row[1] print "ADDRESS = ", row[2] print "SALARY = ", row[3], "\n" print "Operation done successfully" conn.close()
上述程序执行时,它会产生以下结果:
Opened database successfully ID = 1 NAME = Paul ADDRESS = California SALARY = 20000.0 ID = 2 NAME = Allen ADDRESS = Texas SALARY = 15000.0 ID = 3 NAME = Teddy ADDRESS = Norway SALARY = 20000.0 ID = 4 NAME = Mark ADDRESS = Rich-Mond SALARY = 65000.0 Operation done successfully
下面的 Python 代码显示了如何使用 UPDATE 语句来更新任何记录,然后从 COMPANY 表中获取并显示更新的记录:
import sqlite3 conn = sqlite3.connect(‘test.db‘) c = conn.cursor() print "Opened database successfully" c.execute("UPDATE COMPANY set SALARY = 25000.00 where ID=1") conn.commit() print "Total number of rows updated :", conn.total_changes cursor = conn.execute("SELECT id, name, address, salary from COMPANY") for row in cursor: print "ID = ", row[0] print "NAME = ", row[1] print "ADDRESS = ", row[2] print "SALARY = ", row[3], "\n" print "Operation done successfully" conn.close()
上述程序执行时,它会产生以下结果:
Opened database successfully Total number of rows updated : 1 ID = 1 NAME = Paul ADDRESS = California SALARY = 25000.0 ID = 2 NAME = Allen ADDRESS = Texas SALARY = 15000.0 ID = 3 NAME = Teddy ADDRESS = Norway SALARY = 20000.0 ID = 4 NAME = Mark ADDRESS = Rich-Mond SALARY = 65000.0 Operation done successfully
下面的 Python 代码显示了如何使用 DELETE 语句删除任何记录,然后从 COMPANY 表中获取并显示剩余的记录:
import sqlite3 conn = sqlite3.connect(‘test.db‘) c = conn.cursor() print "Opened database successfully" c.execute("DELETE from COMPANY where ID=2;") conn.commit() print "Total number of rows deleted :", conn.total_changes cursor = conn.execute("SELECT id, name, address, salary from COMPANY") for row in cursor: print "ID = ", row[0] print "NAME = ", row[1] print "ADDRESS = ", row[2] print "SALARY = ", row[3], "\n" print "Operation done successfully" conn.close()
上述程序执行时,它会产生以下结果:
Opened database successfully Total number of rows deleted : 1 ID = 1 NAME = Paul ADDRESS = California SALARY = 20000.0 ID = 3 NAME = Teddy ADDRESS = Norway SALARY = 20000.0 ID = 4 NAME = Mark ADDRESS = Rich-Mond SALARY = 65000.0 Operation done successfully
1、把大学csv文件写入到以db+学号命名的数据库中:
import pandas import csv import sqlite3 conn = sqlite3.connect("db+2019310143133.db") df = pandas.read_csv(‘C:/Users/透心凉i/Desktop/HTML.csv‘) df.to_sql(‘db2019310143133‘, conn, if_exists=‘append‘, index=False) cursor = conn.cursor() for row in cursor.execute(‘select * from db2019310143133 ORDER BY "序号"‘): print(row) cursor.close() conn.commit() cursor.close()

经过查询 http://www.zuihaodaxue.com/zuihaodaxuepaiming2016.html 发现,2016年并没有关于广东技术师范大学的数据,所以我们将时间改为2018年,链接为
http://www.zuihaodaxue.com/zuihaodaxuepaiming2018.html
我们获得一个新的csv 文件,命名为 NEW ONE.csv , 并新建一个数据表命名为 deng2019310143133
import pandas import csv import sqlite3 conn = sqlite3.connect("db+2019310143133.db") df = pandas.read_csv(‘C:/Users/透心凉i/Desktop/NEW ONE.csv‘) df.to_sql(‘deng2019310143133‘, conn, if_exists=‘append‘, index=False) cursor = conn.cursor() cursor.execute(‘select * from deng2019310143133‘) all = cursor.fetchall() for line in all: if "广东技术师范学院" in line: print(line) break else: print("False") cursor.close() conn.commit() cursor.close()
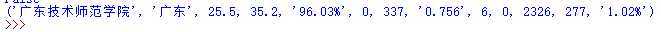
查询并显示广东省的学校的排名和得分,以2018年社会声誉(社会捐赠收入,千元)为例<学号尾数3>:
相关代码如下:
import pandas import sqlite3 import pandas conn= sqlite3.connect("db+2019310143133.db") df = pandas.read_csv(‘C:/Users/透心凉i/Desktop/NEW ONE.csv‘) df.to_sql(‘YUE‘, conn, if_exists=‘append‘, index=False) cur = conn.cursor() cur.execute(‘SELECT * FROM YUE‘) yue = cur.fetchall() for line in yue: if "广东" in line: print("{} {} {} {}".format(line[0],line[1],line[2],line[5])) conn.close()
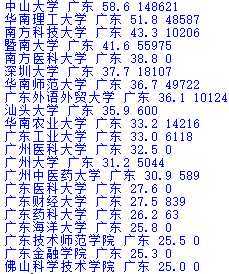
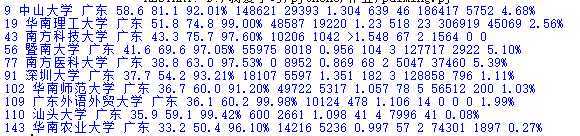
将广东省的学校的排名和得分存为一个新表,并给出一个综合算法,综合考虑给出一个总排名,并显示。
代码如下:
import pandas import sqlite3 conn= sqlite3.connect("db+2019310143133.db") k = pandas.read_csv(‘C:/Users/透心凉i/Desktop/guangdong.csv‘,encoding=‘utf-8‘) k.to_sql(‘Guang‘, conn, if_exists=‘append‘, index=False) conn = sqlite3.connect(‘db+2019310143133.db‘) cur = conn.cursor() cur.execute(‘SELECT * FROM Guang‘) li = cur.fetchall() i=0 for line in li: i+=1 for item in line: print(item, end=‘ ‘) print() if i==10: break conn.close()
原文:https://www.cnblogs.com/wangyingjie123/p/12970094.html