效果不太好
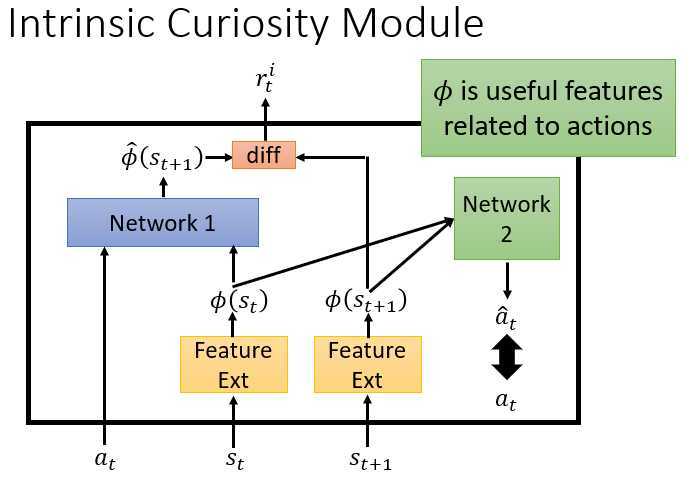
curiosity模型中,在原来DQN的基础上,建立了Network1,用于在??_??和??_??的条件下预测输出的下一个状态,与实际在MDP的一个片段上输出的,下一个状态之间求差,将差作为奖励r的一部分,以鼓励探索不同的状态。
引入了Network2,将输入的两个状态进行特征提取,通过Network2得到的?? ?_??,以?? _??作为实际目标进行训练。从而能够避免虚假的状态变化了?另外,Feature Ext和Network2是同一个网络的不同结构部分么,为什么说训练Feature Ext,又说Network2?
上层单位提供愿景,下层单位执行愿景,下层无法执行,则交给下下层。最终执行的内容返回给上层。上层修改愿景?
https://arxiv.org/abs/1805.08180
行为克隆的一个问题是,不是所有的行为都是有用并应该进行学习的。
另外的状态不匹配性?
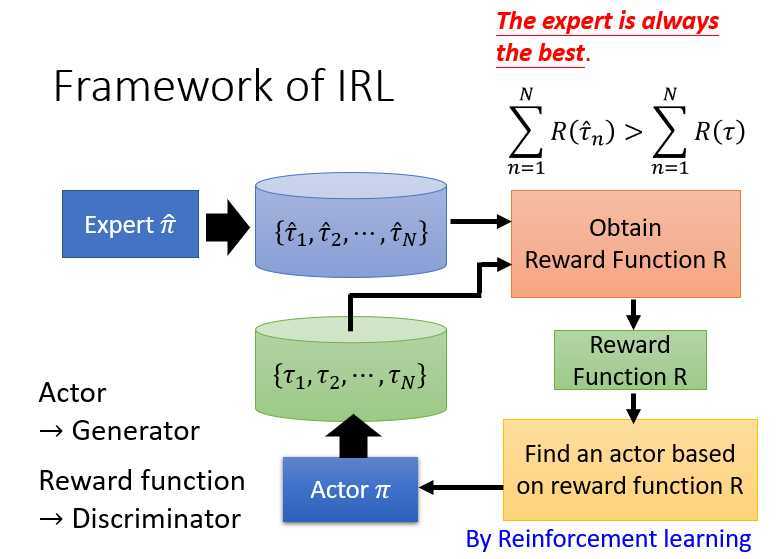
逆向强化学习中,首先是专家在环境中进行交互生成了数据1,与Actor在环境中交互生成了数据2。
将数据1和数据2进行处理,处理过程中使得数据1的奖励大于数据2,得到奖励函数R。使用该奖励函数R,训练Actor。最终得到一个比较好的Actor。
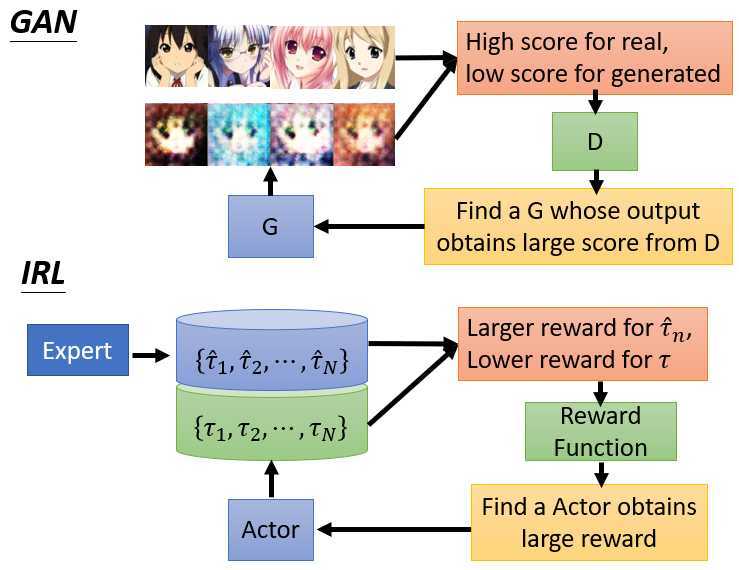
逆向强化学习与GAN网络很相似。GAN通过鉴别器判断输出的好坏,通过G获得一个新的图像输出?
原文:https://www.cnblogs.com/bai2018/p/13019815.html