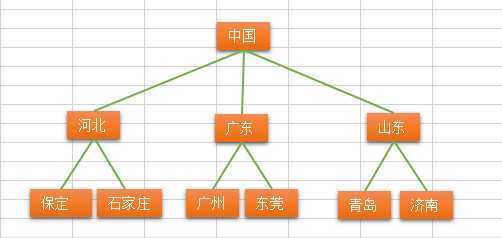
树(英语:tree)是一种抽象数据类型(ADT)或是实作这种抽象数据类型的数据结构,用来模拟具有树状结构性质的数据集合。它是由n(n>=1)个有限节点组成一个具有层次关系的集合。把它叫做“树”是因为它看起来像一棵倒挂的树,也就是说它是根朝上,而叶朝下的。它具有以下的特点:
比如说:
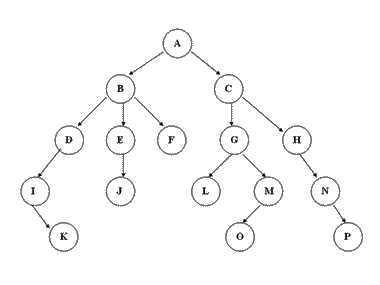
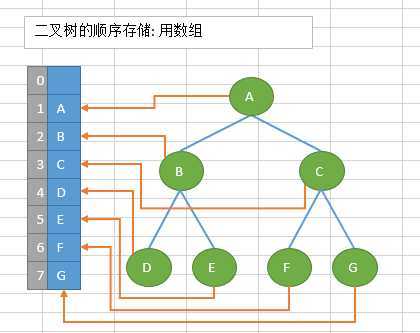
顺序存储:将数据结构存储在固定的数组中,然在遍历速度上有一定的优势,但因所占空间比较大,是非主流二叉树。二叉树通常以链式存储。
链式存储:
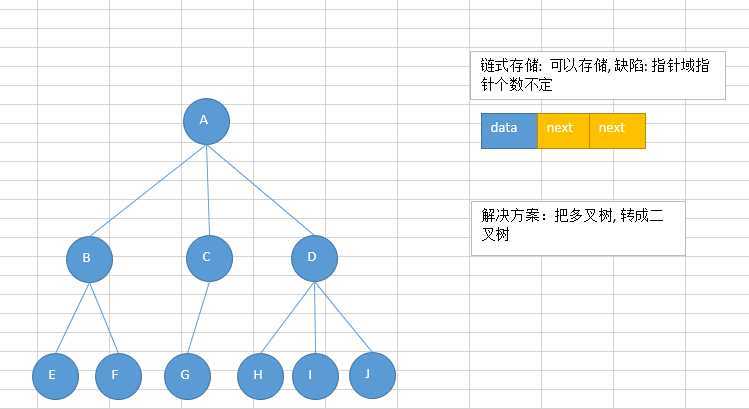
由于对节点的个数无法掌握,常见树的存储表示都转换成二叉树进行处理,子节点个数最多为2
1. xml,html等,那么编写这些东西的解析器的时候,不可避免用到树
2. 路由协议就是使用了树的算法
3. mysql数据库索引
4. 文件系统的目录结构
5. 所以很多经典的AI算法其实都是树搜索,此外机器学习中的decision tree也是树结构
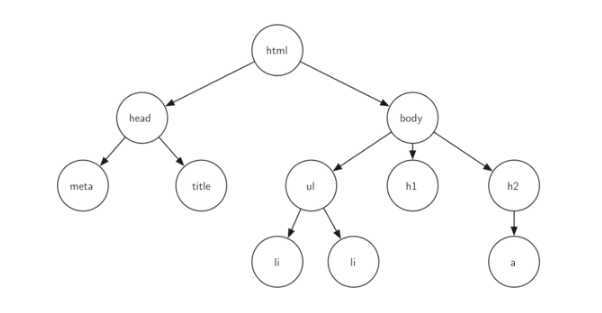
二叉树是每个节点最多有两个子树的树结构。通常子树被称作“左子树”(left subtree)和“右子树”(right subtree)
性质1: 在二叉树的第i层上至多有2^(i-1)个结点(i>0)
性质2: 深度为k的二叉树至多有2^k - 1个结点(k>0)
性质3: 对于任意一棵二叉树,如果其叶结点数为N0 (叶结点即没有子节点的结点),而度数为2的结点(有两个子节点的结点)总数为N2,则N0=N2+1;
性质4:具有n个结点的完全二叉树的深度必为 log2(n+1)
性质5:对完全二叉树,若从上至下、从左至右编号,则编号为i 的结点,其左孩子编号必为2i,其右孩子编号必为2i+1;其双亲的编号必为i/2(i=1 时为根,除外)
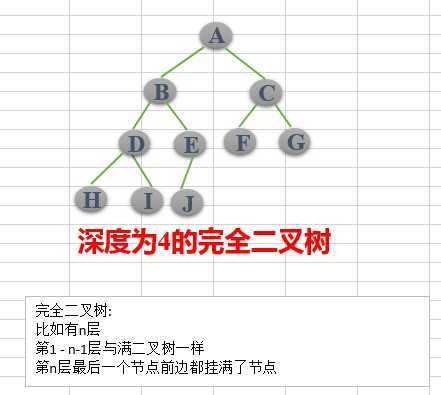
(1)完全二叉树——若设二叉树的高度为h,除第 h 层外,其它各层 (1~h-1) 的结点数都达到最大个数,第h层有叶子结点,并且叶子结点都是从左到右依次排布,这就是完全二叉树。
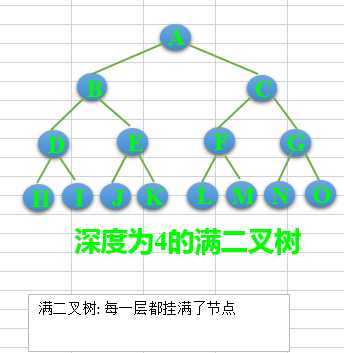
(2)满二叉树——除了叶结点外每一个结点都有左右子叶且叶子结点都处在最底层的二叉树。
通过使用Node类中定义三个属性,分别为elem本身的值,还有lchild左孩子和rchild右孩子
class Note(object): """ 构造节点 """ def __init__(self, item): self.elem = item # 节点 self.lchild = None # 左子节点 self.rchild = None # 右子节点
树的创建,创建一个树的类,并给一个root根节点,一开始为空,随后添加节点
class Tree(object): def __init__(self): """初始化一个空的二叉树""" self.root = None def add(self, item): """添加元素到最后""" node = Note(item) if self.root is None: self.root = node else: queue = [self.root] # 利用列表实现一个队列 while queue: cur_node = queue.pop(0) if cur_node.lchild is None: cur_node.lchild = node return else: queue.append(cur_node.lchild) if cur_node.rchild is None: cur_node.rchild = node return else: queue.append(cur_node.rchild)
树的遍历是树的一种重要的运算。所谓遍历是指对树中所有结点的信息的访问,即依次对树中每个结点访问一次且仅访问一次,我们把这种对所有节点的访问称为遍历(traversal)。那么树的两种重要的遍历模式是深度优先遍历和广度优先遍历,深度优先一般用递归,广度优先一般用队列。一般情况下能用递归实现的算法大部分也能用堆栈来实现。
对于一颗二叉树,深度优先搜索(Depth First Search)是沿着树的深度遍历树的节点,尽可能深的搜索树的分支。
那么深度遍历有重要的三种方法。这三种方式常被用于访问树的节点,它们之间的不同在于访问每个节点的次序不同。这三种遍历分别叫做先序遍历(preorder),中序遍历(inorder)和后序遍历(postorder)。我们来给出它们的详细定义,然后举例看看它们的应用。
(1) 先序遍历 在先序遍历中,我们先访问根节点,然后递归使用先序遍历访问左子树,再递归使用先序遍历访问右子树
根节点->左子树->右子树
def preorder(self, root): """递归实现先序遍历""" if root == None: return print root.elem self.preorder(root.lchild) self.preorder(root.rchild)
(2) 中序遍历 在中序遍历中,我们递归使用中序遍历访问左子树,然后访问根节点,最后再递归使用中序遍历访问右子树
左子树->根节点->右子树
def inorder(self, root): """递归实现中序遍历""" if root == None: return self.inorder(root.lchild) print root.elem self.inorder(root.rchild)
(3) 后序遍历 在后序遍历中,我们先递归使用后序遍历访问左子树和右子树,最后访问根节点
左子树->右子树->根节点
def postorder(self, root): """递归实现后续遍历""" if root == None: return self.postorder(root.lchild) self.postorder(root.rchild) print root.elem
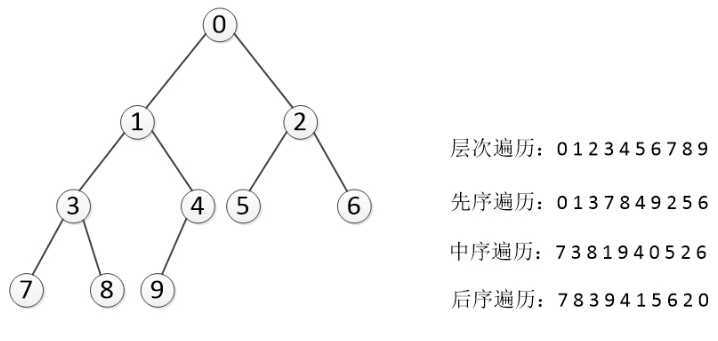
从树的root开始,从上到下从从左到右遍历整个树的节点
class Note(object): """ 构造节点 """ def __init__(self, item): self.elem = item # 节点 self.lchild = None # 左子节点 self.rchild = None # 右子节点 class Tree(object): def __init__(self): """初始化一个空的二叉树""" self.root = None def add(self, item): """添加元素到最后""" node = Note(item) if self.root is None: self.root = node else: queue = [self.root] # 利用列表实现一个队列 while queue: cur_node = queue.pop(0) if cur_node.lchild is None: cur_node.lchild = node return else: queue.append(cur_node.lchild) if cur_node.rchild is None: cur_node.rchild = node return else: queue.append(cur_node.rchild) def breadth_travel(self): """利用队列实现树的层次遍历""" if self.root == None: return queue = [] queue.append(self.root) while queue: node = queue.pop(0) print(node.elem) if node.lchild != None: queue.append(node.lchild) if node.rchild != None: queue.append(node.rchild) if __name__ == ‘__main__‘: tree = Tree() tree.add(1) tree.add(2) tree.add(3) tree.add(4) tree.breadth_travel()
原文:https://www.cnblogs.com/caijunchao/p/13022194.html