对象内存布局(HotSpot)
概述
- 布局划分为三部分:对象头(Header)、实例数据(Instance)、对齐填充(Padding)
- 对象头包含两类信息:用于存储对象自身的运行时数据(Mark Word)和对象指向它的类型元数据的指针(类型指针)
- 实例数据部分时对象真正存储的有效信息,存储顺序受JVM分配策略参数和字段在java源码中定义顺序的影响,
- HotSpot默认存储顺序:long/double,int,short,char,byte/boolean,oop(Ordinary Object Pointer)
对齐填充部分不是必须存在,也没有任何含义,仅仅用于占位符
?
对象头(Header)
- 对象自身的运行时数据(Mark Word)
- 这部分数据的长度在32位和64位的未开启压缩指针的JVM中分别为32bit和64bit。
- Mark Word是一个有着动态定义的数据结构,目的在于在极小的空间存储更多的数据,根据对象的状态复用自己的存储空间
32位HotSpot中,如果对象未被同步锁锁定的状态下,Mark Word的32bit存储空间中,25bit用于存储对象哈希码,4bit存储对象分代年龄,2bit存储锁标志位,1bit固定为0。其他状态存储内容如下表
?
锁状态 | 25bit | 4bit | 1bit | 2bit |
23bit | 2bit | 是否偏向锁 | 锁标志位 |
无锁 | 对象的HashCode | 分代年龄 | 0 | 01 |
偏向锁 | 线程ID | Epoch | 分代年龄 | 1 | 01 |
轻量级锁 | 指向栈中锁记录的指针 | 00 |
重量级锁 | 指向重量级锁的指针 | 10 |
GC标记 | 空 | 11 |
?
- 类型指针
- JVM通过这个指针来确定该对象是哪个类型的实例
- 并不是所有JVM实现都必须在对象数据上保留类型指针。
如果对象是数组,对象头中还必须有一块用于记录数组长度的数据
?
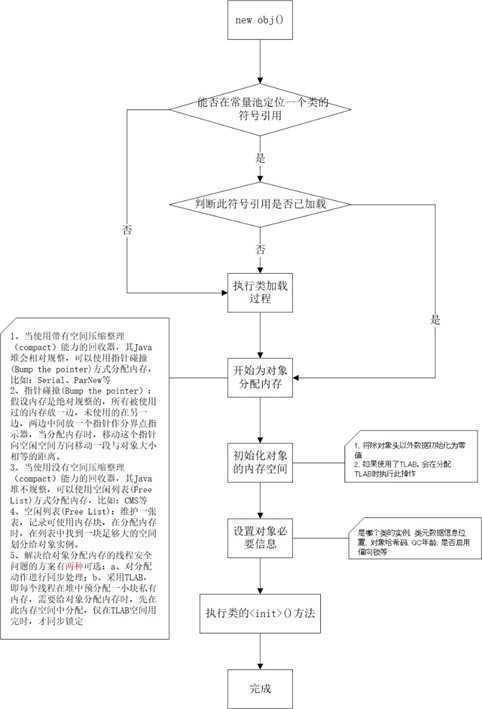
New对象()
JVM创建对象过程
?
对象查找
概述
- reference类型在JVM规范中只规定了它是一个指向对象的引用,并没有定义这个引用应该通过什么方式去定位、访问到堆中对象的具体位置
主流访问方式有:使用句柄和直接指针
?
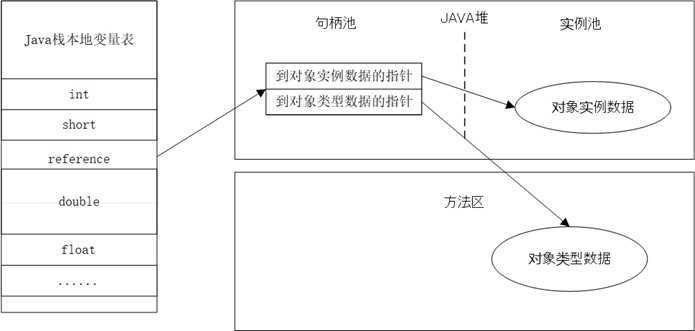
通过句柄访问
- JVM将在队中划分除一块内存作为句柄池,reference中存储对象的句柄地址,而句柄包含了对象实例和类型数据各自的地址信息
优势是:reference存储的是稳定句柄地址,在对象被移动时只会改变句柄中的实例数据指针,而本身不用被修改
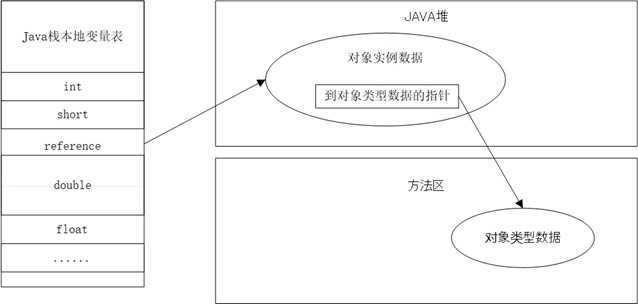
通过直接指针访问
- 堆中的内存布局必须考虑如何放置访问类型数据的相关信息,reference存储的就是对象地址
- 访问对象本身,不需要多一次间接访问开销,相对句柄,速度块,节省了一次指针定位的时间开销
Hotspot主要使用此方法访问
JAVA中对象
原文:https://www.cnblogs.com/adeveloper/p/13022051.html