对于每一个issue会开启一个名为issue-(issue_number)-(name)的分支,在其上进行开发,开发完成后进行自动化测试和浏览器中的实际操作测试。
测试包括以下部分,逐一进行检查:
测试正常后会合并到dev分支,进行代码复审。
每天将复审后的dev分支合并到master分支。
使用tslint进行前端代码的规范,使用的规则如下:
{
"defaultSeverity": "error",
"extends": [
"tslint:recommended"
],
"jsRules": {},
"rules": {
"object-literal-sort-keys": false,
"no-console": false,
"no-empty-interface": false,
"no-shadowed-variable": false,
"ordered-imports": false,
"no-string-literal": false,
"no-bitwise": false,
"function-constructor": false,
"linebreak-style": [true, "LF"]
},
"rulesDirectory": []
}
每次提交和复审时确保没有tslint的错误和警告。

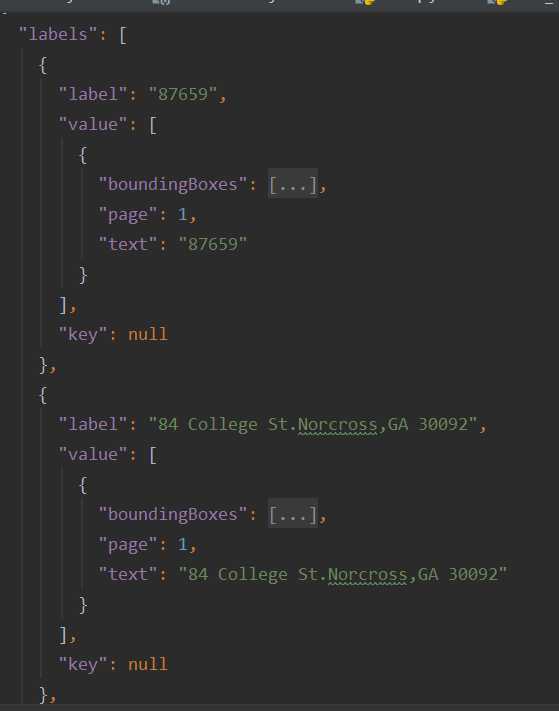
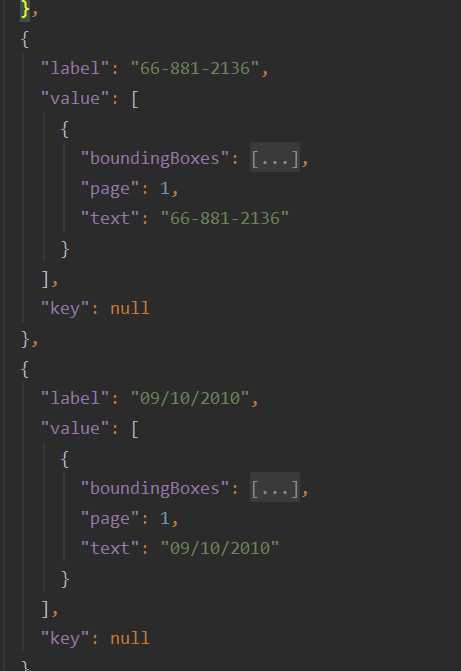
代码经过复审后再合并进master,主要测试的是调用接口对多种实体的识别情况,测试样例中涵盖我们所需要处理的字段以及不匹配实体的字段:
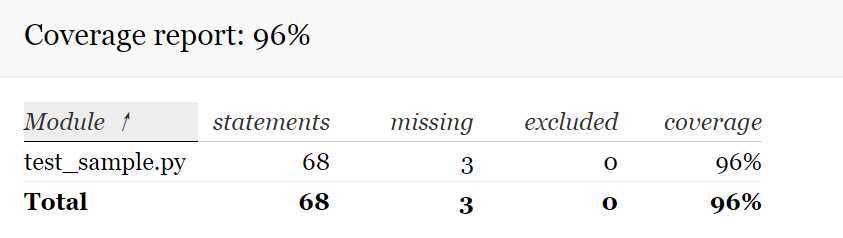
代码覆盖率:
使用pylint做代码格式审查,风格良好:

使用unittest做单元测试,构造多个测试函数:
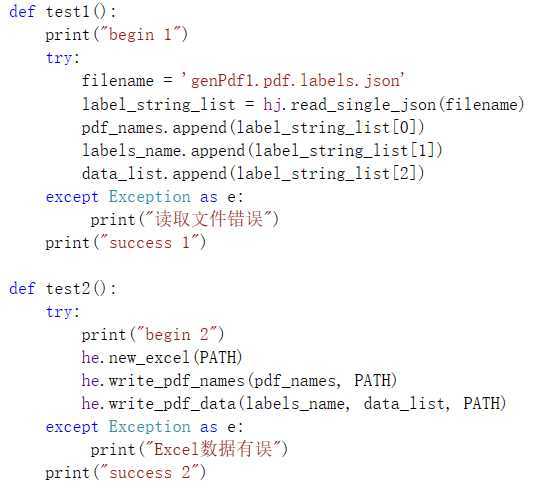
使用coverage做覆盖率测试,结果如下:
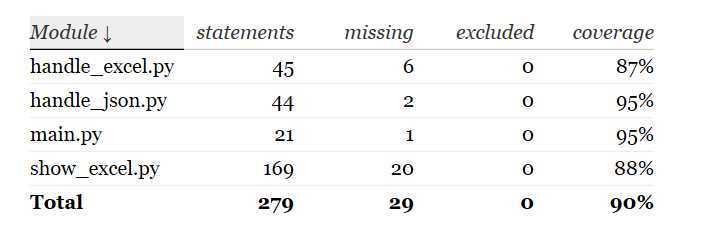
代码规范:

使用pylint进行代码规范的度量,取得满分
测试样例:
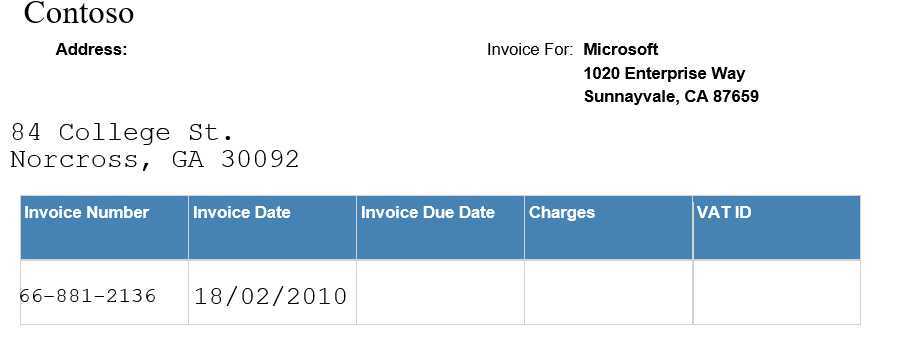
PDF:
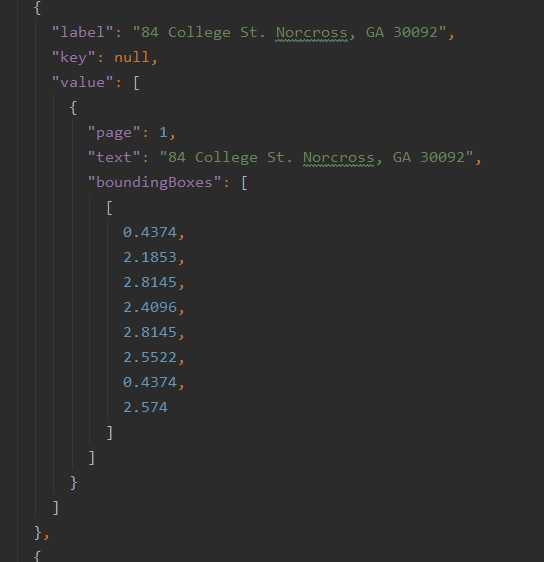
JSON1:

JSON2:

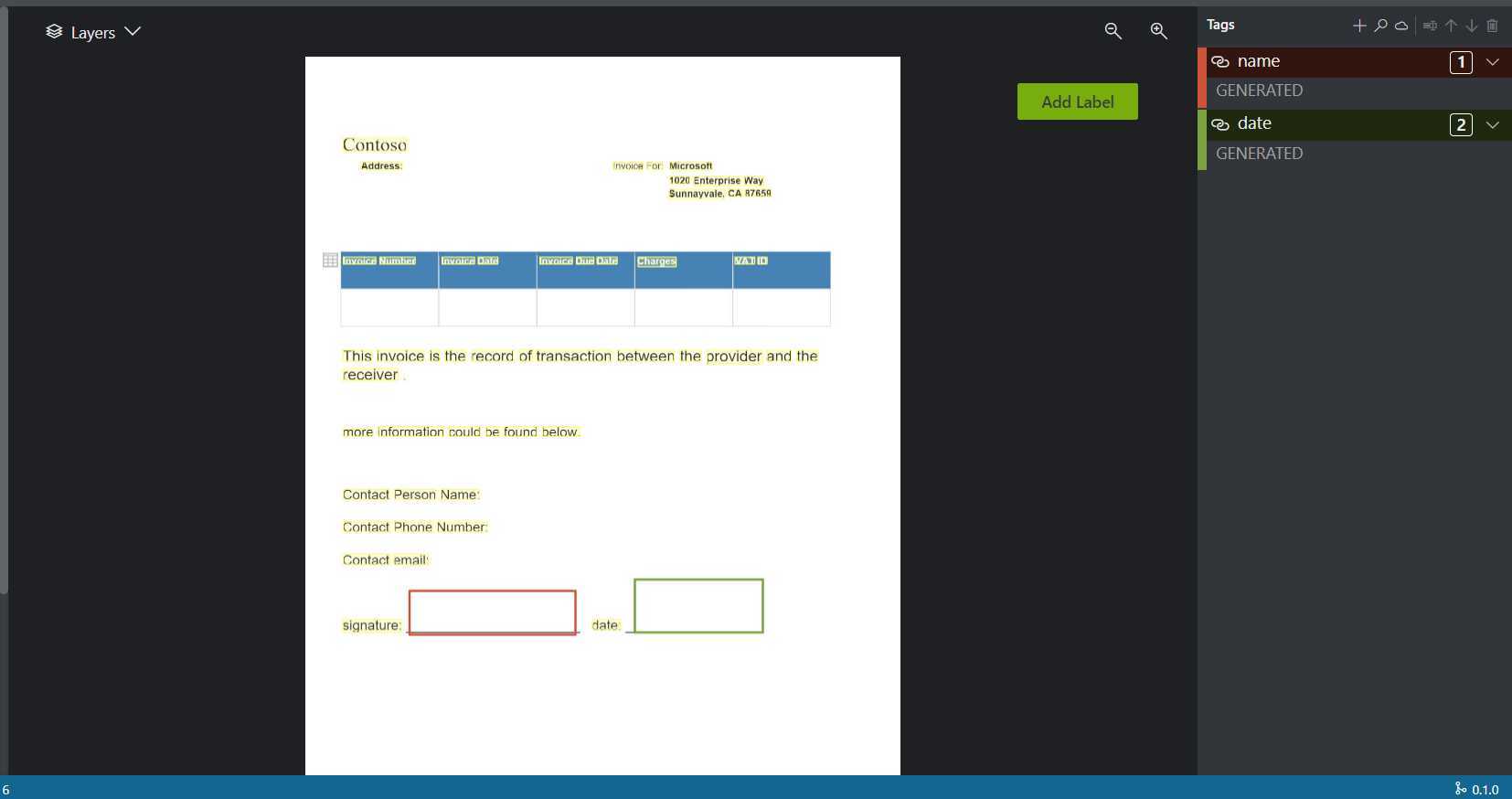
如图所示,PDF部分是随机生成的一个表单,其中的地址数据被生成为了两行,同时还包括了表格中自带的数据。beta部分的数据生成工作需要自动识别文字的位置,从而将其实体识别为各种类别,进而进行数据的训练工作。
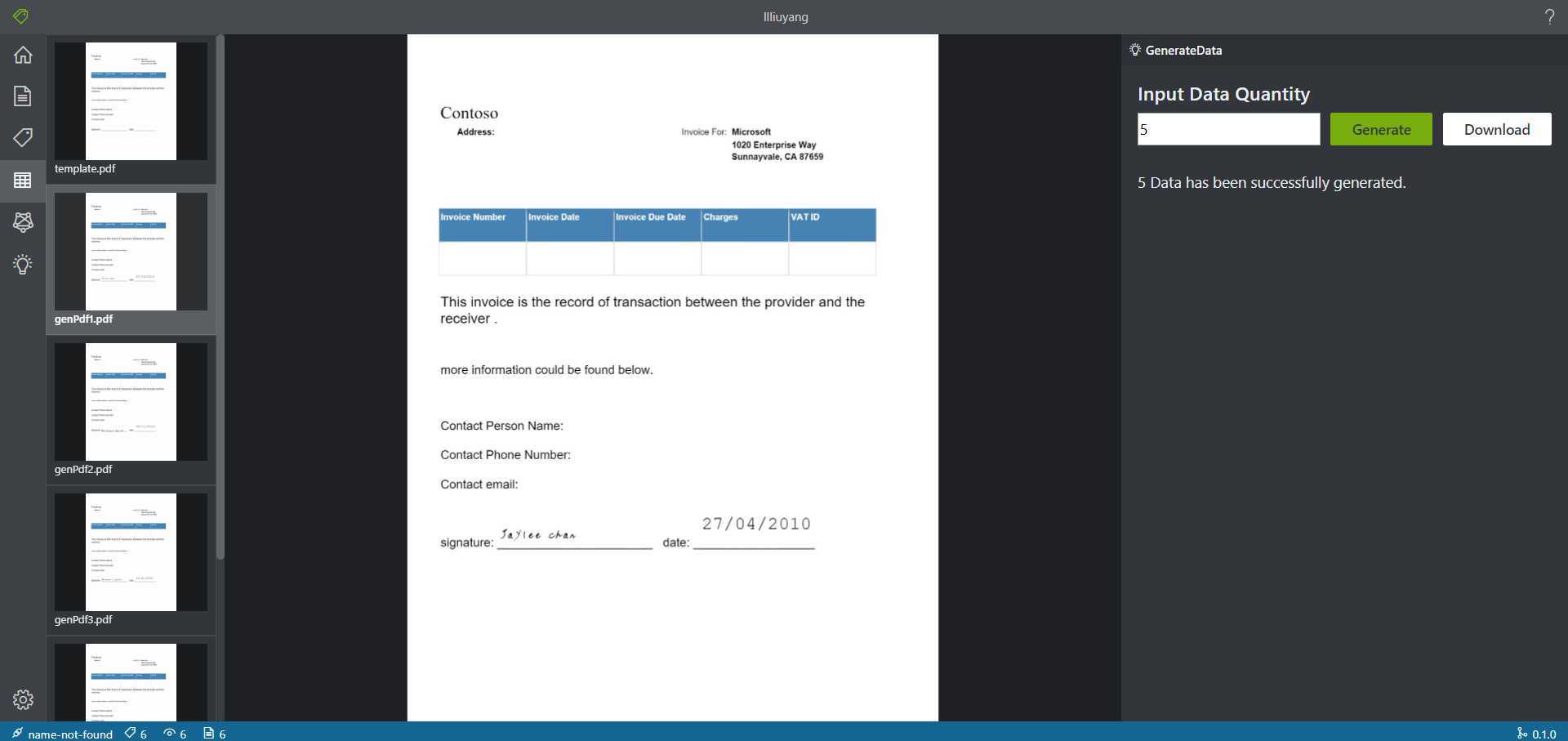
利用微软OCR项目,可以直接得到PDF对应的json,但是经过观察json发现,OCR工具会将中间有过大空格的文字或两行文字,识别成多个词条。这样导致的结果就是,像地址等信息就会被自动拆开,如JSON2所示,而无法正常训练。并且OCR工具还会把原本存在于表格上的文字也识别进去,如JSON1所示,所以数据生成部分做的处理是,首先将原本存在的文字数据进行多文本比对,进行去除;之后按照相对位置、文字大小等属性,将原本属于同一词条但被分成了多条的数据进行自动拼接。
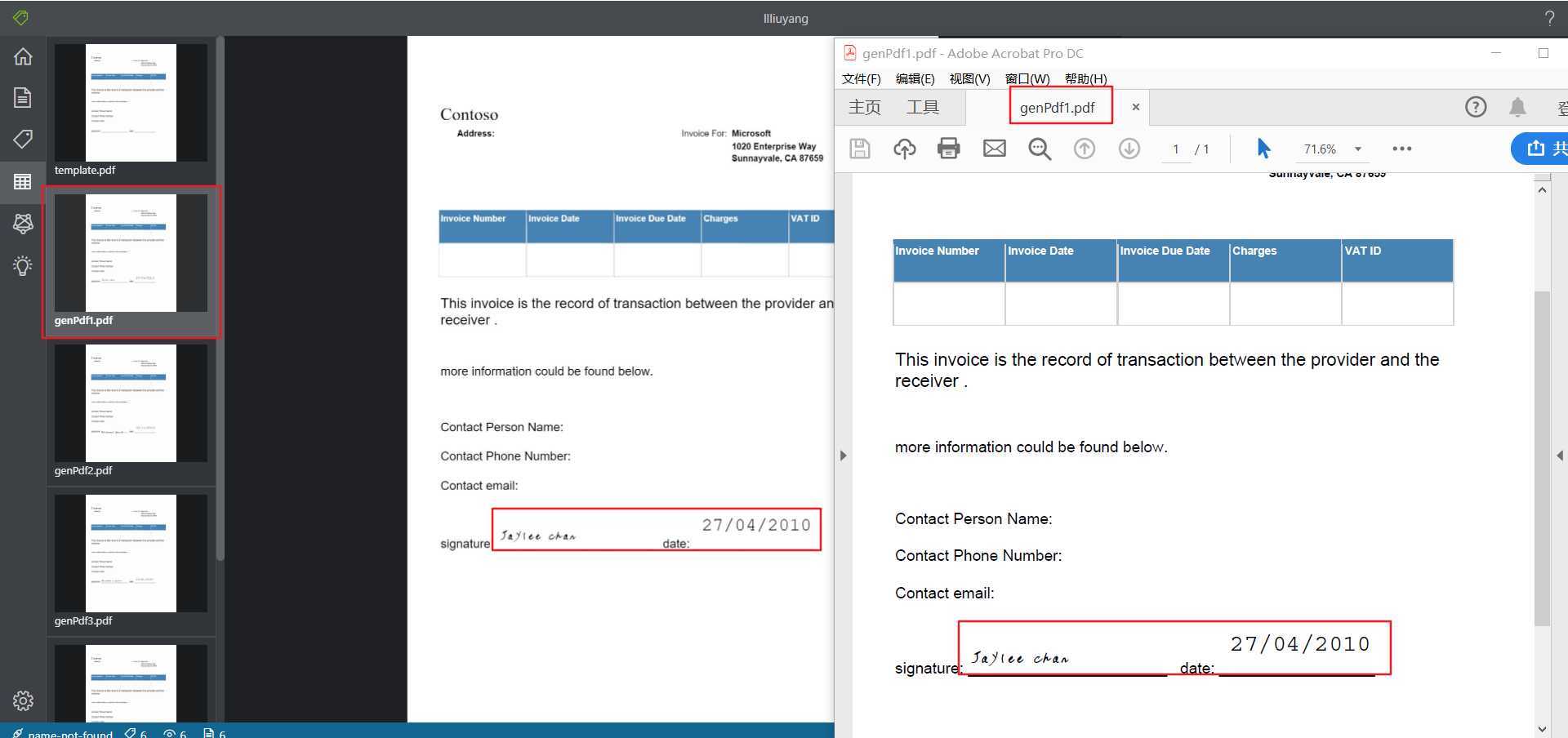
测试结果:
可以看出,本来被分开的数据现在被拼接到了一起,同时,在json文件中,也删除掉了表格中本来存在的字段,后者因为不便展示,仅说实现思路。思路为:传入多个PDF,检测识别出的完全相同的多个部分,则一定是表格中原本存在的文字,可以直接删除。
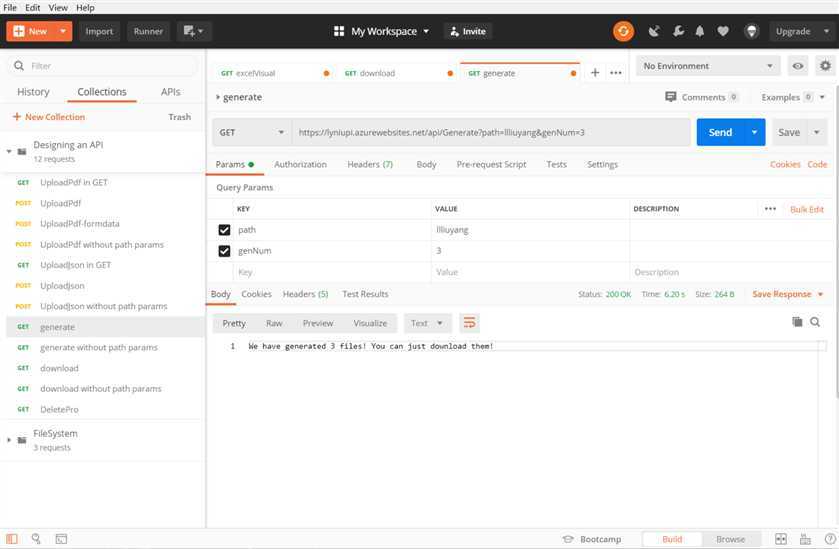
对后端http服务器进行测试,主要测试API的正确性,采用Postman来进行测试。
上传JSON文件
| 请求类别 | 参数或者数据 | 是否成功 | 反馈信息 |
|---|---|---|---|
| GET | type=1 | 否 | Well, please use POST to upload the json file! |
| POST | 没有path参数 | 否 | Wrong in path parameter! You should give the path! |
| POST | type=1 | 出现异常 | Upload failed, please try again! |
| POST | type=1 | 是 | We have get the data: [上传的JSON数据] |
上传PDF模板
| 请求类别 | 参数或者数据 | 是否成功 | 反馈信息 |
|---|---|---|---|
| GET | type=1 | 否 | Well, you should use POST to upload pdf template! |
| POST | 没有path参数 | 否 | Wrong in path parameter! You should give the path! |
| POST | type=1 | 出现异常 | Upload failed, please try again! |
| POST | type=1 | 是 | We have get the data! |
请求生成
| 请求类别 | 参数或者数据 | 是否成功 | 反馈信息 |
|---|---|---|---|
| GET|POST | 没有path参数 | 否 | Wrong in path parameter! You should give the path! |
| GET|POST | —— | 异常 | readjson and getlabel wrong! |
| GET|POST | —— | 异常 | genData wrong! |
| GET|POST | —— | 异常 | open mark fail! |
| GET|POST | —— | 成功 | We have generated * files! You can just download them! |
请求下载
| 请求类别 | 参数或者数据 | 是否成功 | 反馈信息 |
|---|---|---|---|
| GET|POST | 没有path参数 | 否 | Well, you should give the ‘path‘ parameter! |
| GET|POST | —— | 出现异常 | DownLoad wrong, please try again! |
| GET|POST | —— | 是 | pdf和对应的JSON文件zip包 |
自动处理
| 请求类别 | 参数或者数据 | 是否成功 | 反馈信息 |
|---|---|---|---|
| GET|POST | 没有path参数 | 否 | ‘path‘ parameter is needed! |
| GET|POST | —— | 出现异常 | Azure自带的异常信息 |
| GET|POST | —— | 是 | Get it |
上传PDF2
| 请求类别 | 参数或者数据 | 是否成功 | 反馈信息 |
|---|---|---|---|
| POST | 没有path参数 | ||
| POST | |||
| POST | |||
| GET | —— | 否 | You should use POST to upload PDF |
北航附中的学生开学了,今天高一3班的同学们填写了一份关于疫情期间线上英语学习的调查问卷,李华作为英语课代表,老师让他处理这些表单,但是他还没有写完英语作文,你可以帮帮他吗???????
| 用户信息 | 用户情况 |
|---|---|
| 姓名 | 李华 |
| 用户身份 | 高一3班英语课代表 |
| 用户情况 | 处理同学们的调查问卷,由于无法直接导入到Excel,需要手动处理 |
| 用户痛点 | 有急事,需要快速处理这些表单 |
| 典型场景 | 北航附中的学生开学了,今天高一3班的同学们填写了一份关于疫情期间线上英语学习的调查问卷,李华作为英语课代表,老师让他处理这些表单,但是他还没有写完英语作文,你可以帮帮他吗??????? |
| 预期场景 | 李华发现了我们的软件 李华使用软件,上传了5份用来训练 训练结束后李华批量处理了所有的表单并且得到了处理后的Excel文件 李华完成了工作 |
我们的软件提供自动训练模型的功能,只需要用户上传5份填好数据的同类型表单,即可进行训练,之后就可以用来批量处理表单,并支持下载处理结果的Excel!
君哥是一个公司
| 用户信息 | 用户情况 |
|---|---|
| 姓名 | 李华 |
| 用户身份 | 高一3班英语课代表 |
| 用户情况 | 处理同学们的调查问卷,由于无法直接导入到Excel,需要手动处理 |
| 用户痛点 | 有急事,需要快速处理这些表单 |
| 典型场景 | 北航附中的学生开学了,今天高一3班的同学们填写了一份关于疫情期间线上英语学习的调查问卷,李华作为英语课代表,老师让他处理这些表单,但是他还没有写完英语作文,你可以帮帮他吗??????? |
| 预期场景 | 李华发现了我们的软件 李华使用软件,上传了5份用来训练 训练结束后李华批量处理了所有的表单并且得到了处理后的Excel文件 李华完成了工作 |
Alpha阶段的主要功能是上传一个PDF模板,进行标注,根据标注的信息来自动生成若干个填好数据的表单。
Beta阶段基于这一功能,实现了训练表单识别模型的功能。在生成数据的基础上,直接用生成的数据来训练模型,并且拿训练好的模型预测处理“新表单”
这里的回归测试是基于当前Beta阶段稳定版本,测试之前表单数据生成的功能的完整性和正确性,从两个方面进行
基于chromium的浏览器均可以正常使用。
主流浏览器基本都可以正常使用我们的软件。
| 操作系统 | 浏览器类型 | 是否正常 |
|---|---|---|
| win10 | Microsoft Edge(版本号81.0.416.68 ) | 可以正常显示和使用 |
| win10 | Internet Explorer(版本号11.778.18362.0) | 不正常。该版本最后发布日期应该是2015年,比较老旧,无法正常显示,升级到chrome内核后可以正常使用 |
| win10 | Google Chrome(版本号81.0.4044.129) | 可以正常显示和使用 |
| win10 | FireFox(72.0.2 (64 位)) | 可以正常显示与使用 |
| win10 | 360浏览器 | 无法正常使用,频繁报错,暂时没有找到解决方案 |
| Ubuntu16.04 | Google chrome | 可以正常显示和使用 |
| Android9 | 华为手机自带浏览器(版本号5.0.420) | 可以正常显示,并且界面大小比较合适。但由于部分操作涉及键盘,在使用时存在困难。 |
| IOS13 | Safari | 可以正常显示,但是手机端使用不便 |
以上的部分目前都已经实现,所以认为项目当前可以发布!??
原文:https://www.cnblogs.com/Name-NotFound/p/12952695.html