$美元符号为前缀。常量的类型有整数常量、浮点数常量、字符常量和字符串常量等几种类型。以下是几种类型常量的例子:$1 // 十进制
$0xf4f8fcff // 十六进制
$1.5 // 浮点数
$‘a‘ // 字符
$"abcd" // 字符串
$2+2 // 常量表达式
$3&1<<2 // == $4
$(3&1)<<2 // == $4
GLOBL ·NameData(SB),$8
DATA ·NameData(SB)/8,$"gopher"
GLOBL ·Name(SB),$16
DATA ·Name+0(SB)/8,$·NameData(SB)
DATA ·Name+8(SB)/8,$6
$·NameData(SB)也是以$美元符号为前缀,因此也可以将它看作是一个常量,它对应的是NameData包变量的地址。在汇编指令中,我们也可以通过LEA指令来获取NameData变量的地址。SP栈空间来隐式定义。SB伪寄存器定位。SB是Static base pointer的缩写,意为静态内存的开始地址。我们可以将SB想象为一个和内容容量有相同大小的字节数组,所有的静态全局符号通常可以通过SB加一个偏移量定位,而我们定义的符号其实就是相对于SB内存开始地址偏移量。对于SB伪寄存器,全局变量和全局函数的符号并没有任何区别。GLOBL symbol(SB), width
symbol的变量,变量对应的内存宽度为width,内存宽度部分必须用常量初始化。下面的代码通过汇编定义一个int32类型的count变量:GLOBL ·count(SB),$4
美元符号开头。内存的宽度必须是2的指数倍```,编译器最终会保证变量的真实地址对齐到机器字倍数。需要注意的是,在Go汇编中我们无法为count变量指定具体的类型。在汇编中定义全局变量时,我们只关心变量的名字和内存大小,变量最终的类型只能在Go语言中声明。DATA symbol+offset(SB)/width, value
symbol+offset偏移量开始,width宽度的内存,用value常量对应的值初始化。DATA初始化内存时,width必须是1、2、4、8几个宽度之一,因为再大的内存无法一次性用一个uint64大小的值表示。DATA ·count+0(SB)/1,$1
DATA ·count+1(SB)/1,$2
DATA ·count+2(SB)/1,$3
DATA ·count+3(SB)/1,$4
// or
DATA ·count+0(SB)/4,$0x04030201
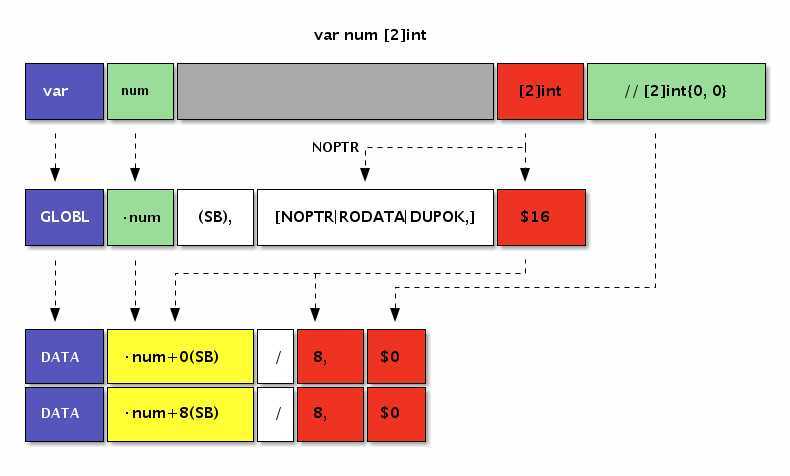
[2]byte类型和[1]uint16类型有着相同的内存结构。只有当数组和结构体结合之后情况才会变的稍微复杂。var num [2]int
GLOBL ·num(SB),$16
DATA ·num+0(SB)/8,$0
DATA ·num+8(SB)/8,$0
var (
boolValue bool
trueValue bool
falseValue bool
)
GLOBL ·boolValue(SB),$1 // 未初始化
GLOBL ·trueValue(SB),$1 // var trueValue = true
DATA ·trueValue(SB)/1,$1 // 非 0 均为 true
GLOBL ·falseValue(SB),$1 // var falseValue = true
DATA ·falseValue(SB)/1,$0
MOVBQZX指令将不足的高位用0填充。var int32Value int32
var uint32Value uint32
GLOBL ·int32Value(SB),$4
DATA ·int32Value+0(SB)/1,$0x01 // 第0字节
DATA ·int32Value+1(SB)/1,$0x02 // 第1字节
DATA ·int32Value+2(SB)/2,$0x03 // 第3-4字节
GLOBL ·uint32Value(SB),$4
DATA ·uint32Value(SB)/4,$0x01020304 // 第1-4字节

var float32Value float32
var float64Value float64
GLOBL ·float32Value(SB),$4
DATA ·float32Value+0(SB)/4,$1.5 // var float32Value = 1.5
GLOBL ·float64Value(SB),$8
DATA ·float64Value(SB)/8,$0x01020304 // bit 方式初始化
type reflect.StringHeader struct {
Data uintptr
Len int
}
var helloworld string
GLOBL ·helloworld(SB),$16
以<>为后缀名为私有变量),内容为“Hello World!”:GLOBL text<>(SB),NOPTR,$16
DATA text<>+0(SB)/8,$"Hello Wo"
DATA text<>+8(SB)/8,$"rld!"
text<>私有变量表示的字符串只有12个字符长度,但是我们依然需要将变量的长度扩展为2的指数倍数,这里也就是16个字节的长度。其中NOPTR表示text<>不包含指针数据。DATA ·helloworld+0(SB)/8,$text<>(SB) // StringHeader.Data
DATA ·helloworld+8(SB)/8,$12 // StringHeader.Len
type reflect.SliceHeader struct {
Data uintptr
Len int
Cap int
}
var helloworld []byte
GLOBL ·helloworld(SB),$24 // var helloworld []byte("Hello World!")
DATA ·helloworld+0(SB)/8,$text<>(SB) // StringHeader.Data
DATA ·helloworld+8(SB)/8,$12 // StringHeader.Len
DATA ·helloworld+16(SB)/8,$16 // StringHeader.Cap
GLOBL text<>(SB),$16
DATA text<>+0(SB)/8,$"Hello Wo" // ...string data...
DATA text<>+8(SB)/8,$"rld!" // ...string data...
var m map[string]int
var ch chan int
GLOBL ·m(SB),$8 // var m map[string]int
DATA ·m+0(SB)/8,$0
GLOBL ·ch(SB),$8 // var ch chan int
DATA ·ch+0(SB)/8,$0
func makemap(mapType *byte, hint int, mapbuf *any) (hmap map[any]any)
func makechan(chanType *byte, size int) (hchan chan any)
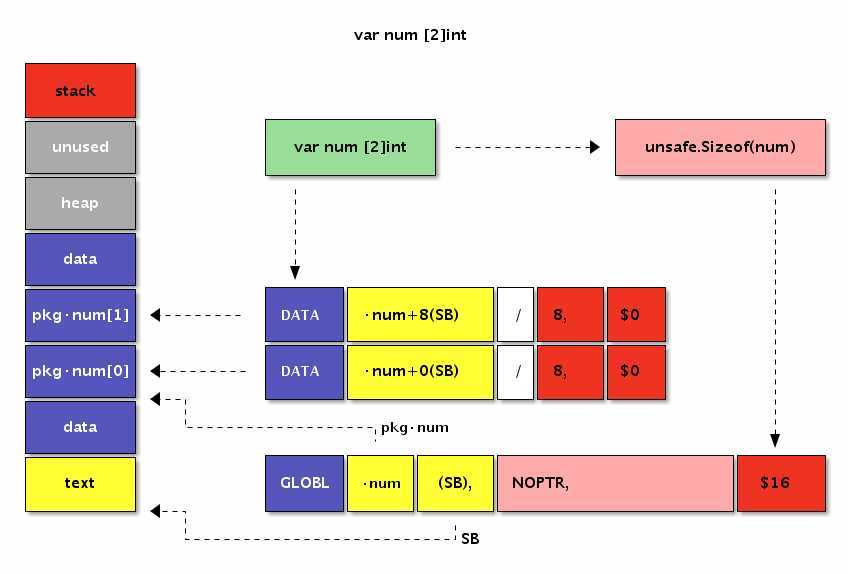
image.Point结构体类型变量的内存布局: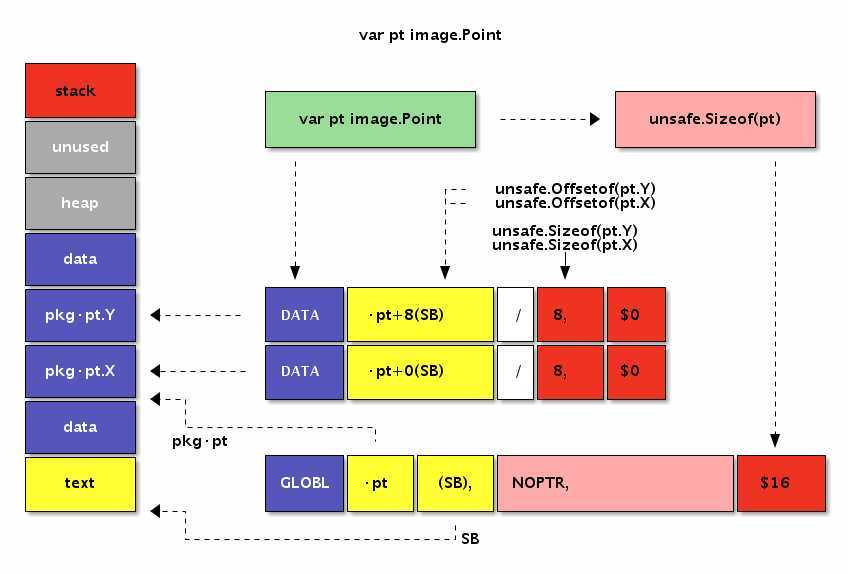
[2]int和image.Point类型底层有着近似相同的内存布局。GLOBL ·pkg_name1(SB),$1
GLOBL main·pkg_name2(SB),$1
GLOBL my/pkg·pkg_name(SB),$1
<>为后缀名:GLOBL file_private<>(SB),$1
"textflag.h"文件定义了一些标志。其中用于变量的标志有DUPOK、RODATA和NOPTR几个。DUPOK表示该变量对应的标识符可能有多个,在链接时只选择其中一个即可(一般用于合并相同的常量字符串,减少重复数据占用的空间)。RODATA标志表示将变量定义在只读内存段,因此后续任何对此变量的修改操作将导致异常(recover也无法捕获)。NOPTR则表示此变量的内部不含指针数据,让垃圾回收器忽略对该变量的扫描。如果变量已经在Go代码中声明过的话,Go编译器会自动分析出该变量是否包含指针,这种时候可以不用手写NOPTR标志。var const_id int // readonly
#include "textflag.h"
GLOBL ·const_id(SB),NOPTR|RODATA,$8
DATA ·const_id+0(SB)/8,$9527
"textflag.h"头文件(和C语言中预处理相同)。然后GLOBL汇编命令在定义变量时,给变量增加了NOPTR和RODATA两个标志(多个标志之间采用竖杠分割),表示变量中没有指针数据同时定义在只读数据段。原文:https://www.cnblogs.com/binHome/p/13027712.html