常见性能问题定位
一、 刚开始压测报错,停了之后重新压测不报错
这种情况经常遇到,特别是重启服务之后,因为系统刚重启,需要做一些初始化的动作,如果一下上很多并发用户数难免会报错,只要压测几次之后不再报错,就是正常的,服务器也需要“预热”一段时间。
二、 少用户并发不报错,大用户并发报错
可能有两种情况引起这种问题,一是脚本的问题:参数设置不够或者错误;二是连接池设置的不合理。一定要先排除脚本的问题之后,再去查找其他问题,不要给开发人员带来不必要的麻烦。
三、内存溢出
1、堆内存溢出
现象:
(1)压测执行一段时间后,系统处理能力下降。这时用JConsole、JVisualVM等工具连上服务器查看GC情况,每次GC回收都不彻底并且可用堆内存越来越少。
(2)压测持续下去,最终在日志中有报错信息:java.lang.OutOfMemoryError.Java heap space。
排查手段:
(1)使用jmap -histo pid > test.txt命令将堆内存使用情况保存到test.txt文件中,打开文件查看排在前50的类中有没有熟悉的或者是公司标注的类名,如果有则高度怀疑内存泄漏是这个类导致的。
(2)如果没有,则使用命令:jmap -dump:live,format=b,file=test.dump pid生成test.dump文件,然后使用MAT进行分析。
(3)如果怀疑是内存泄漏,也可以使用JProfiler连上服务器在开始跑压测,运行一段时间后点击“Mark Current Values”,后续的运行就会显示增量,这时执行一下GC,观察哪个类没有彻底回收,基本就可以判断是这个类导致的内存泄漏。
解决方式:优化代码,对象使用完毕,需要置成null。
2、永久代 / 方法区溢出
现象:压测执行一段时间后,日志中有报错信息:java.lang.OutOfMemoryError: PermGen space。
产生原因:由于类、方法描述、字段描述、常量池、访问修饰符等一些静态变量太多,将持久代占满导致持久代溢出。
解决方法:修改JVM参数,将XX:MaxPermSize参数调大。尽量减少静态变量。
3、栈内存溢出
现象:压测执行一段时间后,日志中有报错信息:java.lang.StackOverflowError。
产生原因:线程请求的栈深度大于虚拟机所允许的最大深度,递归没返回,戒者循环调用造成。
解决方法:修改JVM参数,将Xss参数改大,增加栈内存。栈内存溢出一定是做批量操作引起的,减少批处理数据量。
4、系统内存溢出
现象:压测执行一段时间后,日志中有报错信息:java.lang.OutOfMemoryError: unable to create new native thread。
产生原因:操作系统没有足够的资源来产生返个线程造成的。系统创建线程时,除了要在Java堆中分配内存外,操作系统本身也需要分配资源来创建线程。因此,当线程数量大到一定程度以后,堆中或许还有空间,但是操作系统分配不出资源来了,就出现这个异常了。
解决方法:
(1)减少堆内存
(2)减少线程数量
(3)如果线程数量不能减少,则减少每个线程的堆栈大小,通过-Xss减小单个线程大小,以便能生产更多的线程。
5、JAVA直接内存溢出
现象:压测执行一段时间后,日志中有报错信息:OutOfMemoryError
产生原因:
(1)直接内存大多时候也被称为堆外内存,直接内存通过 native 方法可以分配堆外内存,通过 DirectByteBuffer 对象来操作。直接内存不属于 Java 堆,所以它不受堆内存大小限制,但是它受物理内存大小的限制。
(2)可以通过 -XX:MaxDirectMemorySize 参数来设置最大可用直接内存,如果启动时未设置则默认为最大堆内存大小,即与 -Xmx 相同。即假如最大堆内存为1G,则默认直接内存也为1G,那么 JVM 最大需要的内存大小为2G多一些。当直接内存达到最大限制时就会触发GC,如果回收失败则会引起OutOfMemoryError。
(3)直接内存在读和写的性能都优于堆内内存,但是内存申请速度却不如堆内内存。
解决方法:因此直接内存适用于需要大内存空间且频繁访问的场合,不适用于频繁申请释放内存的场合。在需要频繁申请的场景下不应该使用直接内存(DirectMemory),而应该使用堆内内存(HeapMemory)。
四、CPU过高
1、us cpu高
现象:压测过程中,使用top命令查看系统资源占用情况,us cpu过高,超过50%以上。
排查手段:
(1)使用top命令是哪个进程消耗CPU高
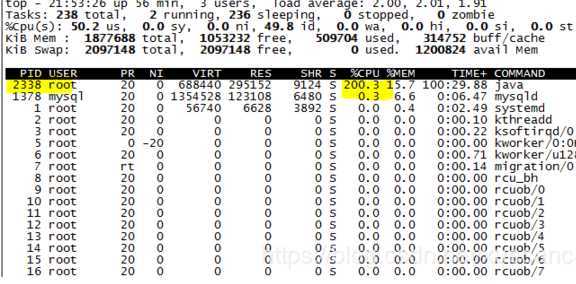
(2)再找到CPU消耗高的线程:top -H -p 进程号
p 表示进程PID
-c 显示进程的绝对路径
-H 显示进程的所有线程
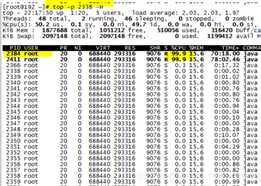
也可以用下面的命令将 cpu 占用率高的线程找出来:
ps H -eo user,pid,ppid,tid,time,%cpu,cmd --sort=%cpu

找到了占用cpu最高的两个线程,要查看线程的信息, 把上面的进程信息dump下来,然后在文件查找线程信息,不是直接dump线程信息。线程对应的是栈,在栈中可以看到线程操作了哪些数据。
(3)把线程号转换成16进制:printf "%x\n" 线程号
有时候需要把线程号转成16进制,因为dunmp的线程号可能是以16进程显示的,比如:nid=0xc46e,0x表示是16进制的数据,c46e是线程号,转成十进制是142156,则对应的线程号是142156。

(4)再用jstack命令分析这个线程是在干什么:jstack 进程号 | grep 16进制的线程号
(5)通过JProfiler的CPU Views视图的层层分析,可以清楚的找到造成CPU高的原因
2、sy cpu高
现象:压测过程中,使用top命令查看系统资源占用情况,sy cpu过高,超过50%以上。
排查手段:
(1)首先查看磁盘繁忙程度、磁盘的队列(iostat、nmon)
(2)如果磁盘没有问题,则使用strace查看系统内核调用情况
3、数据库CPU利用率过高
数据库CPU利用率高一般是大量的逻辑读或者物理读引起的,也有可能是解析比较复杂的SQL,如果是Oracle 数据库,可以通过抓取AWR报告进行,重点看下面两项:
SQL ordered by Gets
SQL ordered by Physical Reads (UnOptimized)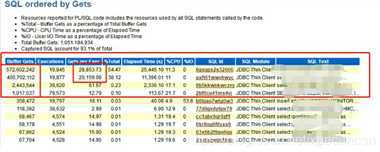
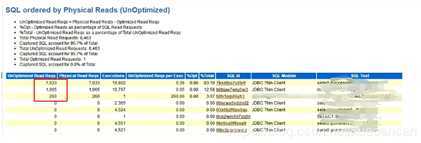
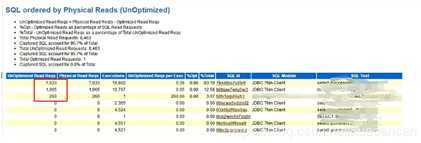
这一部分,通过Buffer Gets对SQL语句进行排序,即通过它执行了多少个逻辑I/O来排序。顶端的注释表明一个PL/SQL单元的缓存获得(Buffer Gets)包括被这个代码块执行的所有SQL语句的Buffer Gets。大量的逻辑读往往伴随着较高的CPU消耗,在这里的Buffer Gets是一个累积值,所以这个值大并不一定意味着这条语句的性能存在问题。通常我们可以通过对比该条语句的Buffer Gets和physical reads值,如果这两个比较接近,肯定这条语句是存在问题的 ,如果对比差别不大,可以关注 **gets per exec的值,这个值如果太大,表明这条语句可能使用了一个比较差的索引或者使用了不当的表连接。
另外还可以通过查看使用CPU高的进程ID,根据进程ID查找对应的SQL ID,从而找出相应的sql语句。
五、线程死锁
现象:
(1)压测进行一段时间后,程序停顿,报超时错误。但这种现象并不一定就是线程死锁造成的,也可能是数据库/中间件连接池被占满、数据库死锁造成的。
(2)能够打开页面,但获取不到数据
排查手段:
(1)使用jstack命令查看Java进程下所有线程的情况:jstack -l 进程号
(2)如果有Blocked状态的线程,说明有线程死锁的状况。如果大量线程都是Waiting状态,则需要去关注数据库和中间件,可能会有排队情况。
(3)也可以使用JConsole、JVisualVM及JProfiler等工具直接查看所有线程的情况
六、数据库连接池不释放
现象:压测进行一段时间后,报连接超时的错误。
排查手段:
(1)去数据库查看应用程序到数据库的连接有多少个:show full processlist。加入应用程序中配置的最大连接数为30,而通过命令show full processlist查看到的从应用服务器连接过来的连接数也为30,证明数据库连接池占满了。
(2)将应用程序中的最大连接数改大一点(比如100),再重新进行压测,如果还是出现连接池被占满的情况,则证明是数据库连接池不释放造成的.
解决方法:排查代码,数据库连接部分应该是有创建连接但是没有关闭连接的情况。让开发修改代码即可。
七、数据库死锁
现象:
(1)压测进行一段时间后,报连接超时的错误。
(2)程序在执行的过程中,点击确定或保存按钮,程序没有响应,也没有出现报错。
排查手段:查看数据库日志,看有没有死锁的情况:show engine innodb status\G。
八、响应时间慢
现象:事物响应时间慢
排查手段:
(1)打开数据库的慢查询
(2)通过命令找到执行比较久的SQL语句:mysqldumpslow
(3)利用explain来优化这条SQL语句
响应时间慢可以从两个方面来分析,一是查看AWR报告,或者在数据库中搜索慢的sql,在AWR报告中需要关注下面两项:
SQL ordered by Elapsed Time
SQL ordered by CPU Time
一般sql的慢是没加索引或者索引失效引起的,也有可能是查询方式过于复杂,表的关联关系不对,小表驱动大表,或者在sql语句中进行了大量的计算,具体的问题需要DBA或者开发人员进行分析。
如果不是慢sql引起的,则需要查找程序的问题,可以通过压测工具定位到具体方法,也可以dump进程,查看是否有锁争用、死锁或者资源等待的情况。在本次压测中出现了大量dubbo服务等待数据库响应的线程,数据库的CPU利用率达到90%,导致应用的大部分进程是sleeping状态,通过查看dump下来的线程发现大部分处于Runable状态,而他们都在等待锁住同一资源(数据库)。增加数据库CPU之后,响应时间慢的问题得到解决。
九、TPS上不去
1、网络带宽
在压力测试中,有时候要模拟大量的用户请求,如果单位时间内传递的数据包过大,超过了带宽的传输能力,那么就会造成网络资源竞争,间接导致服务端接收到的请求数达不到服务端的处理能力上限。
2、连接池
最大连接数太少,造成请求等待。连接池一般分为服务器中间件连接池(比如Tomcat)和数据库连接池(或者理解为最大允许连接数也行)。
3、垃圾回收机制
从常见的应用服务器来说,比如Tomcat,如果堆内存设置比较小,就会造成新生代的Eden区频繁的进行Young GC,老年代的Full GC也回收较频繁,那么对TPS也是有一定影响的,因为垃圾回收时通常会暂停所有线程的工作。
4、数据库
高并发情况下,如果请求数据需要写入数据库,且需要写入多个表的时候,如果数据库的最大连接数不够,或者写入数据的SQL没有索引没有绑定变量,抑或没有主从分离、读写分离等,就会导致数据库事务处理过慢,影响到TPS。
5、硬件资源
包括CPU(配置、使用率等)、内存(占用率等)、磁盘(I/O、页交换等)。
6、压力机
比如Jmeter和Loadrunner,单机负载能力有限,如果需要模拟的用户请求数超过其负载极限,也会间接影响TPS(这个时候就需要进行分布式压测来解决其单机负载的问题)。
7、业务逻辑
业务解耦度较低,较为复杂,整个事务处理线被拉长也会导致TPS上不去。
8、系统架构
比如是否有缓存服务,缓存服务器配置,缓存命中率、缓存穿透以及缓存过期等,都会影响到测试结果。
十、500或503错误
现象:压测过程中,服务器返回500或503错误
排查手段
(1)通过浏览器访问网站,如果浏览器打不开,服务器可能挂了。可能的原因是:内存溢出、数据库连接池满了、线程死锁。
(2)先看JVM内存是否满了:jstat -gcutil 2384 1000 5
(3)看数据库连接池大小是否占满,把最大连接数改大,如果还是出现这种现象,证明是数据库连接池不释放。
(4)最后看是否有线程死锁:jstack -l 进程号
十一、性能问题分析流程
1、查看服务器的CPU、内存 、负载等情况,包括应用服务器和数据库服务器
2、查看数据库健康状态,数据库死锁、连接池不释放
3、查看项目日志(查看无报错现象)
4、查看jvm的gc等情况
原文:https://www.cnblogs.com/feiyu8888/p/13039213.html