2、MySQL分表
分表是将一个大表按照一定的规则分解成多张具有独立存储空间的实体表,每个表都对应三个文件,MYD数据文件,.MYI索引文件,.frm表结构文件。这些表可以分布在同一块磁盘上,也可以在不同的机器上。app读写的时候根据事先定义好的规则得到对应的表名,然后去操作它。
将单个数据库表进行拆分,拆分成多个数据表,然后用户访问的时候,根据一定的算法(如用hash的方式,也可以用求余(取模)的方式),让用户访问不同的表,这样数据分散到多个数据表中,减少了单个数据表的访问压力。提升了数据库访问性能。分表的目的就在于此,减小数据库的负担,缩短查询时间。
Mysql分表分为垂直切分和水平切分,具体区别如下:
垂直切分是指数据表列的拆分,把一张列比较多的表拆分为多张表 通常我们按以下原则进行垂直拆分: 把不常用的字段单独放在一张表; 把text,blob(binary large object,二进制大对象)等大字段拆分出来放在附表中;
经常组合查询的列放在一张表中; 垂直拆分更多时候就应该在数据表设计之初就执行的步骤,然后查询的时候用join关键起来即可。
水平拆分是指数据表行的拆分,把一张的表的数据拆成多张表来存放。 水平拆分原则,通常情况下,我们使用hash、取模等方式来进行表的拆分 比如一张有400W的用户表users,为提高其查询效率我们把其分成4张表users1,users2,users3,users4 通过用ID取模的方法把数据分散到四张表内Id%4= [0,1,2,3] 然后查询,更新,删除也是通过取模的方法来查询 部分业务逻辑也可以通过地区,年份等字段来进行归档拆分; 进行拆分后的表,这时我们就要约束用户查询行为。比如我们是按年来进行拆分的,这个时候在页面设计上就约束用户必须要先选择年,然后才能进行查询。
3、利用merge存储引擎实现分表
注:只有myisam引擎的原表才可以利用merge存储引擎实现分表。
merge分表,分为主表和子表,主表类似于一个壳子,逻辑上封装了子表,实际上数据都是存储在子表中的。 我们可以通过主表插入和查询数据,如果清楚分表规律,也可以直接操作子表。
例:
1)创建一个完整表
mysql> create database test1;
mysql> use test1;
mysql> create table member
-> (
-> id bigint auto_increment primary key,
-> name varchar(20),
-> sex tinyint not null default ‘0‘
-> )engine=myisam default charset=utf8 auto_increment=1;
#插入数据
mysql> insert into member(name,sex) values(‘tom1‘,1);
mysql> insert into member(name,sex) select name,sex from member; # 插入语句多执行几次,即可插入大量的数据
mysql> select count(*) from member; # 手贱了,这里我插入了16384条数据
+----------+
| count(*) |
+----------+
| 16384 |
+----------+
1 row in set (0.00 sec)2)对上面完整的表进行分表
分表注意事项:
- 子表和主表的字段定义需要一致,包括数据类型,数据长度等;
- 当分表完成后,所有的操作(增删改查)需要对主表进行,虽然主表并不存放实际的数据。
#创建两个分表,表结构必须和上面完整的表结构一致
mysql> create table tb_member1 like member;
mysql> create table tb_member2 like member;
#创建merge引擎的表作为主表,并关联上面的两个分表
mysql> create table tb_member
-> (
-> id bigint auto_increment primary key,
-> name varchar(20),
-> sex tinyint not null default ‘0‘
-> )engine=merge union=(tb_member1,tb_member2) insert_method=last charset=utf8;注:在上面创建主表时,指定的“insert_method=last”有三个可选参数,分别是:last:表示插入到最后一张表里面;first:表示插入到第一张表里面;NO:表示该表不能做任何写入操作,只作为查询使用。
3)查看刚刚创建的三个表结构如下: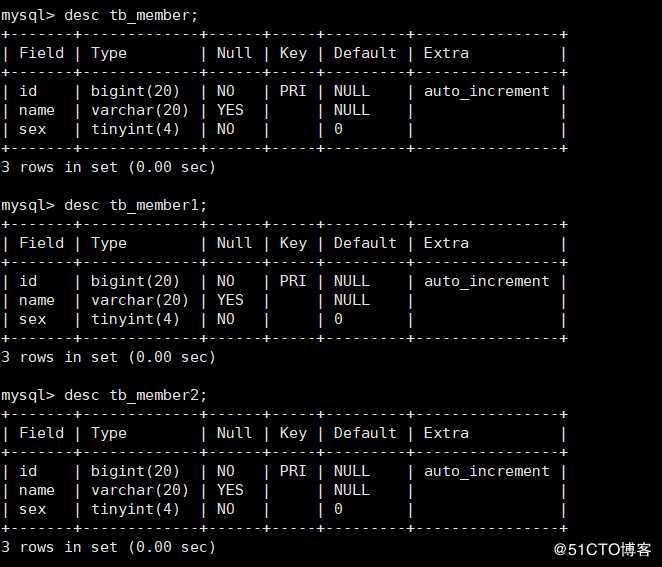
4)将数据分到两个表中:
mysql> insert into tb_member1(id,name,sex) select id,name,sex from member where id%2=0;
Query OK, 8192 rows affected (0.01 sec)
Records: 8192 Duplicates: 0 Warnings: 0
mysql> insert into tb_member2(id,name,sex) select id,name,sex from member where id%2=1;
Query OK, 8192 rows affected (0.02 sec)
Records: 8192 Duplicates: 0 Warnings: 05)查看主表和两个子表中的数据
第一个子表部分数据如下: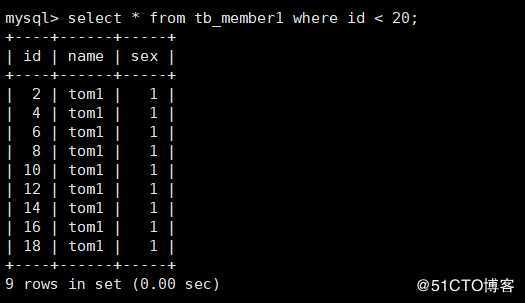
第二个子表部分数据如下: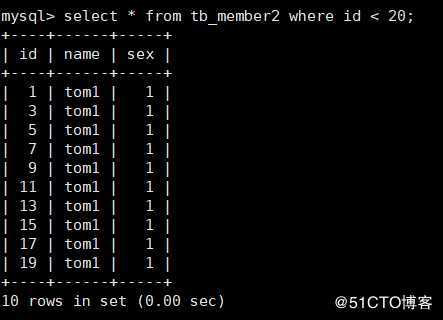
主表部分查询的部分数据如下: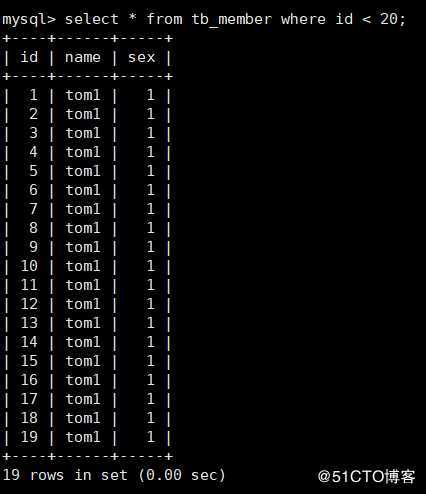
数据总行数如下: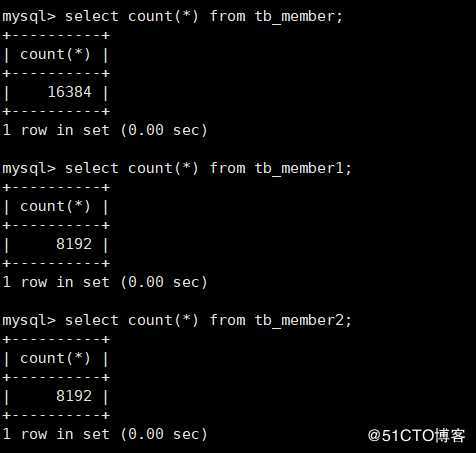
注意:总表只是一个外壳,存取数据发生在一个一个的子表里面。 每个子表都有自已独立的相关表文件,而主表只是一个壳,并没有完整的相关表文件,当确定主表中可以查到的数据和分表之前查到的数据完全一致时,就可以将原来的表删除了,之后对表的读写操作,都可以对分表后的主表进行。
上面三个表对应的本地文件如下: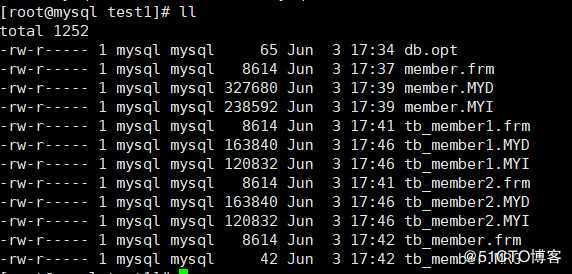
可以看出,能够查询到所有数据的主表的本地数据文件是非常小的,这也验证了,数据并没有存在这个主表中。
6)对主表进行插入数据的操作,如下:
mysql> insert into tb_member values(16385,‘tom2‘,0),(16386,‘tom3‘,1);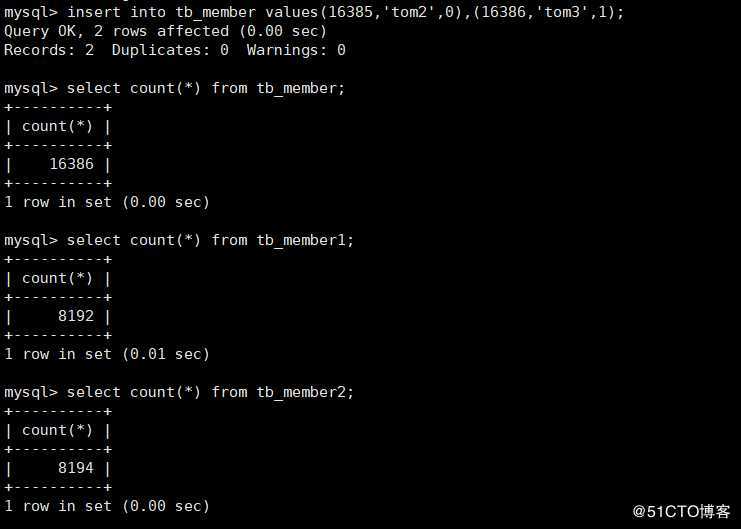
可以看出,新增的两条数据都插入在了第二张表中,因为在创建主表的时候,指定的“insert_method”是last,也就是所有插入数据的操作都是对最后一张表里进行的,可以通过alter指令修改插入方法,如下:
mysql> alter table tb_member INSERT_METHOD=first;修改插入方法后,再自行对表进行插入数据的操作,可以发现所有的数据都写入了第一个表(我这里插入了四条数据),查看如下:
mysql> insert into tb_member values(16387,‘tom4‘,2),(16388,‘tom5‘,3),(16389,‘tom6‘,4),(16390,‘tom7‘,5);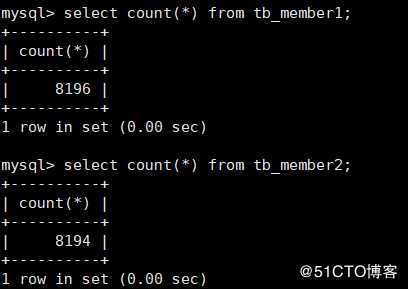
上面是新增了四条数据,可以发现都插入到了第一张表。
若将插入方法修改为no,则表示这个表不能再插入任何数据,如下:
mysql> alter table tb_member insert_method=no;
mysql> insert into tb_member values(16391,‘tom7‘,9);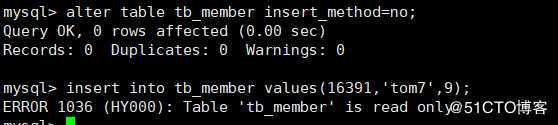
4、MySQL分区
1)什么是分区?
分区和分表相似,都是按照规则分解表。不同在于分表将大表分解为若干个独立的实体表,而分区是将数据分段划分在多个位置存放,分区后,表还是一张表,但数据散列到多个位置了。app读写的时候操作的还是表名字,db自动去组织分区的数据。
分区主要有以下两种形式:
水平分区:这种形式分区是对表的行进行分区,所有在表中定义的列在每个数据集中都能找到,所以表的特性依然得以保持。
举个简单例子:一个包含十年发票记录的表可以被分区为十个不同的分区,每个分区包含的是其中一年的记录。
垂直分区:这种分区方式一般来说是通过对表的垂直划分来减少目标表的宽度,使某些特定的列被划分到特定的分区,每个分区都包含了其中的列所对应的行。
举个简单例子:一个包含了大text和BLOB列的表,这些text和BLOB列又不经常被访问,这时候就要把这些不经常使用的text和BLOB了划分到另一个分区,在保证它们数据相关性的同时还能提高访问速度。
2)查看当前数据库是否支持分区
MySQL 5.6之前,使用下面的参数查看当前配置是否支持分区(如果为yes则表示支持分区):
mysql> SHOW VARIABLES LIKE ‘%partition%‘;
+-----------------------+---------------+
|Variable_name | Value |
+-----------------------+---------------+
| have_partition_engine | YES |
+-----------------------+------------------+在5.6及以后采用以下方式查看:
mysql> show plugins;返回的结果中,有以下字段(如果status列为“ACTIVE”,则表示支持分区):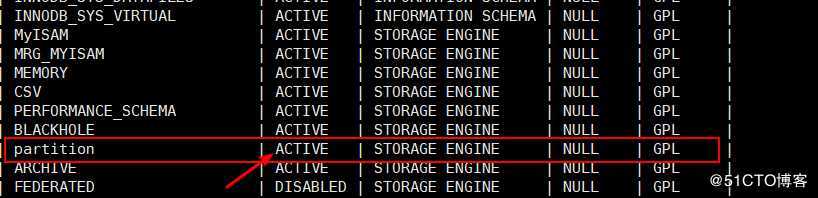
3)按照范围(range)方式的表分区
mysql> create table user
-> (
-> id int not null auto_increment,
-> name varchar(30) not null default ‘‘,
-> sex int(1) not null default ‘0‘,
-> primary key(id)
-> )default charset=utf8 auto_increment=1
-> partition by range(id)
-> (
-> partition p0 values less than (3),
-> partition p1 values less than (6),
-> partition p2 values less than (9),
-> partition p3 values less than (12),
-> partition p4 values less than maxvalue
-> );注:在上面创建的表中,当id列的值小于3将会插入到p0分区,大于3小于6的记录将会插入到p1分区,以此类推,所有id值大于12的记录都会插入到p4分区。
4)利用存储过程插入一些数据
mysql> delimiter //
mysql> create procedure adduser()
-> begin
-> declare n int;
-> declare summary int;
-> set n = 0;
-> while n <= 20
-> do
-> insert into test1.user(name,sex) values("tom",0);
-> set n=n+1;
-> end while;
-> end //
Query OK, 0 rows affected (0.01 sec)
mysql> delimiter ;
mysql> delimiter ;
mysql> call adduser();
Query OK, 1 row affected (0.01 sec)
mysql> select * from user;
+----+------+-----+
| id | name | sex |
+----+------+-----+
| 1 | tom | 0 |
| 2 | tom | 0 |
| 3 | tom | 0 |
| 4 | tom | 0 |
| 5 | tom | 0 |
| 6 | tom | 0 |
| 7 | tom | 0 |5)到存放数据表文件的目录下看一下: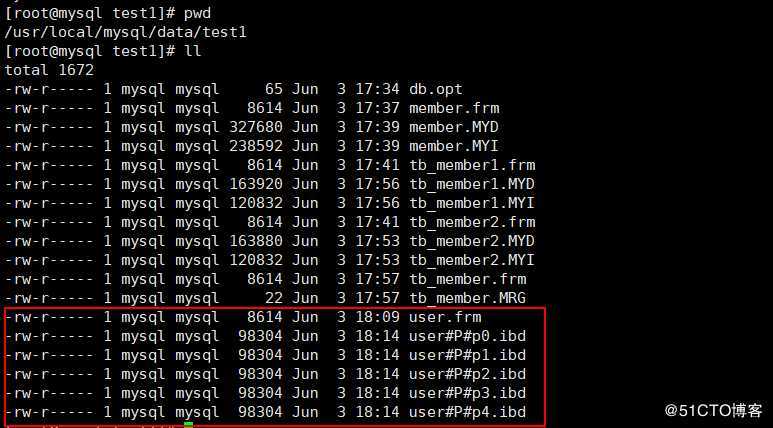
可以看到数据是被分散存到不同的文件中的,本地的文件名都是“user#P#p0...”命名的,其中p0是自定义的分区名。
6)统计数据行数
mysql> select count(*) from user;
+----------+
| count(*) |
+----------+
| 21 |
+----------+
1 row in set (0.00 sec)7)从information_schema系统库中的partition表中查看分区信息
mysql> select * from information_schema.partitions where table_schema=‘test1‘ and table_name=‘user‘\G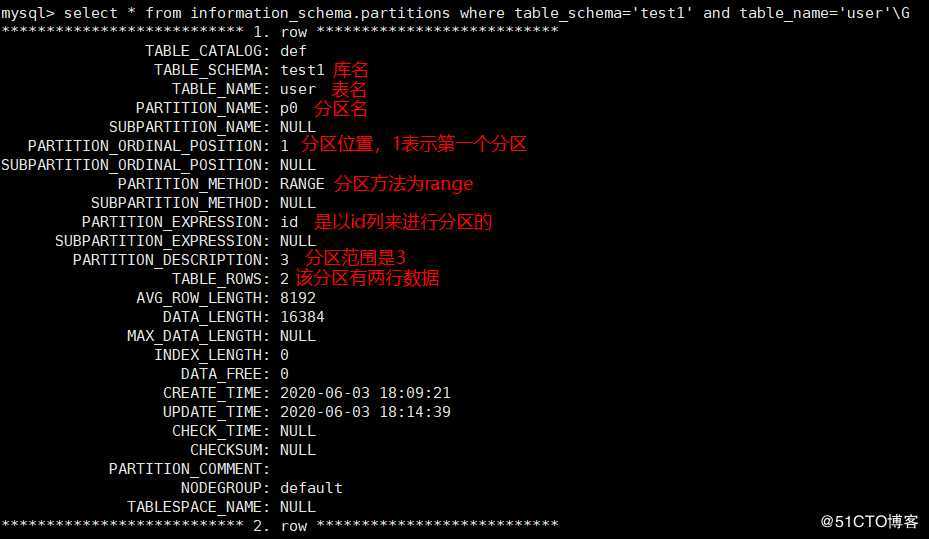
8)从分区中查询数据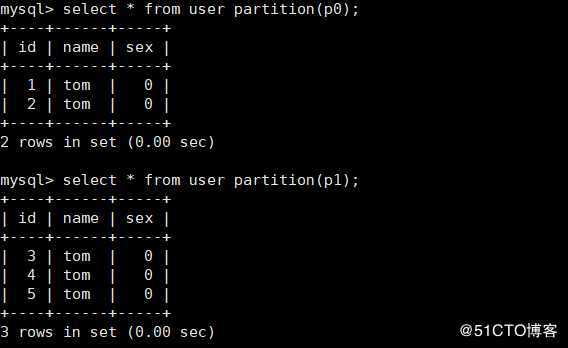
9)添加及合并分区(需要先合并分区再新增分区)
1.添加分区:
注意:由于在创建表的时候,指定的最后一个分区range是maxvalue,所以是无法直接增加分区的,如下:
mysql> alter table user add partition (partition p5 values less than (20));
ERROR 1481 (HY000): MAXVALUE can only be used in last partition definition大意是:MAXVALUE只能在最后一个分区定义中使用
但也不可以将最后定义了maxvalue的分区直接删除,因为删除分区的话,分区中的数据也会丢失,所以,如果需要新增分区的正确做法,应该是先合并分区,再新增分区,这样才可以保证数据的完整性,如下:
mysql> alter table user reorganize partition p4 into (partition p03 values less than (15),partition p04 values less than maxvalue );上述命令的作用就是将最后一个分区分为两个分区,一个是自己所需要的分区,最后一个分区还是maxvalue(也必须是maxvalue),这样就完成了添加分区。
本地表文件如下: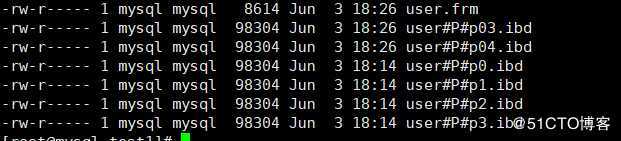
查询新增分区中的数据如下: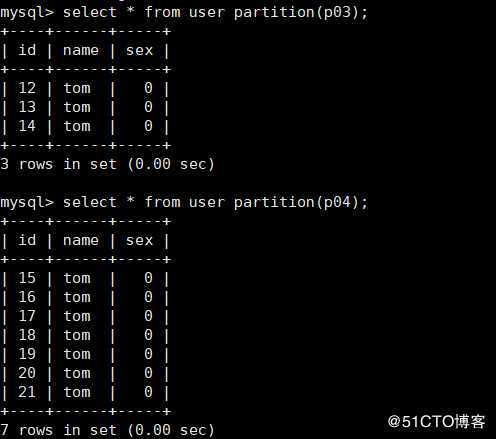
2.合并分区
将p0、p1、p2、p3四个分区合并为p02:
mysql> alter table user reorganize partition p0,p1,p2,p3 into
-> (partition p02 values less than (12));可以看到p02将整合了p0,p1,p2,p3三个分区的数据,如下: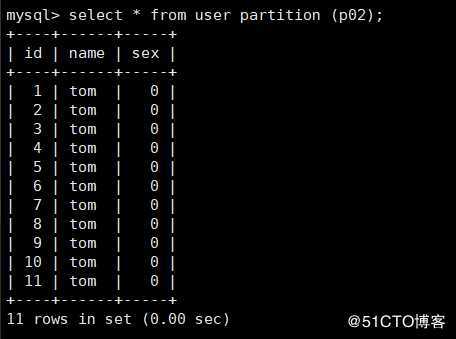
本地文件如下:
10) 删除分区
mysql> alter table user drop partition p02;注意:分区被删除后,分区中的数据也将被删除,删除分区p02的表中所有数据如下:
原文:https://blog.51cto.com/14227204/2501071