2020-06-04 18:57:21
Source:https://medium.com/cracking-the-data-science-interview/meta-learning-is-all-you-need-3bd0bafdf289
Neural networks have been highly influential in the past decades in the machine learning community, thanks to the rise of computing power, the abundance of unstructured data, and the advancement of algorithmic solutions. However, it is still a long way for researchers to completely use neural networks in real-world settings where the data is scarce, and requirements for model accuracy/speed are critical.
Meta-learning, also known as learning how to learn, has recently emerged as a potential learning paradigm that can absorb information from one task and generalize that information to unseen tasks proficiently. During this quarantine time, I started watching lectures on Stanford’s CS 330 class on Deep Multi-Task and Meta-Learning taught by the brilliant Chelsea Finn. As a courtesy of her talks, this blog post attempts to answer these key questions:
Note: The content of this post is primarily based on CS330’s lecture one on problem definitions, lecture two on supervised and black-box meta-learning, lecture three on optimization-based meta-learning, and lecture four on few-shot learning via metric learning. They are all accessible to the public.
Thanks to the advancement in algorithms, data, and compute power in the past decade, deep neural networks have allowed us to handle unstructured data (such as images, text, audio, video, etc.) very well without the need to engineer features by hand. Empirical research has shown that if neural networks can generalize very well if we feed them large and diverse inputs. For example, Transformers and GPT-2 made the wave in the Natural Language Processing research community last year with their broad applicability in various tasks.
However, there is a catch with using neural networks in the real-world setting where:
In this article, I would like to give an introductory overview of meta-learning, which is a learning framework that can help our neural network become more effective in the settings mentioned above. In this setup, we want our system to learn a new task more proficiently — assuming that it is given access to data on previous tasks.
Historically, there have been a few papers thinking in this direction.
Right now is an exciting period to study meta-learning because it is increasingly becoming more fundamental in machine learning research. Many recent works have leveraged meta-learning algorithms (and their variants) to do well for the given tasks. A few examples include:
Forward-looking, the development of meta-learning algorithms will help democratize deep learning and solve problems in domains with limited data.
In this section, I will cover the basics of meta-learning. Let’s start with the mathematical formulation of supervised meta-learning.
In a standard supervised learning, we want to maximize the likelihood of model parameters ? given the training data D:
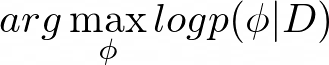
Equation 1 can be redefined as maximizing the probability of the data provided the parameters and maximizing the marginal probability of the parameters, where p(D|?) corresponds to the data likelihood, and p(?) corresponds to a regularizer term:
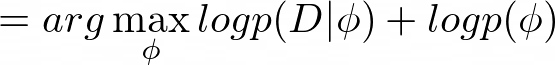
Equation 2 can be further broken down as follows, assuming that the data D consists of (input, label) pairs of (x?, y?):

However, if we deal with massive data D (as in most cases with complicated problems), our model will likely overfit. Even if we have a regularizer term here, it might not be enough to prevent that from happening.
The critical problem that supervised meta-learning solves is: Is it feasible to get more data when dealing with supervised learning problems?

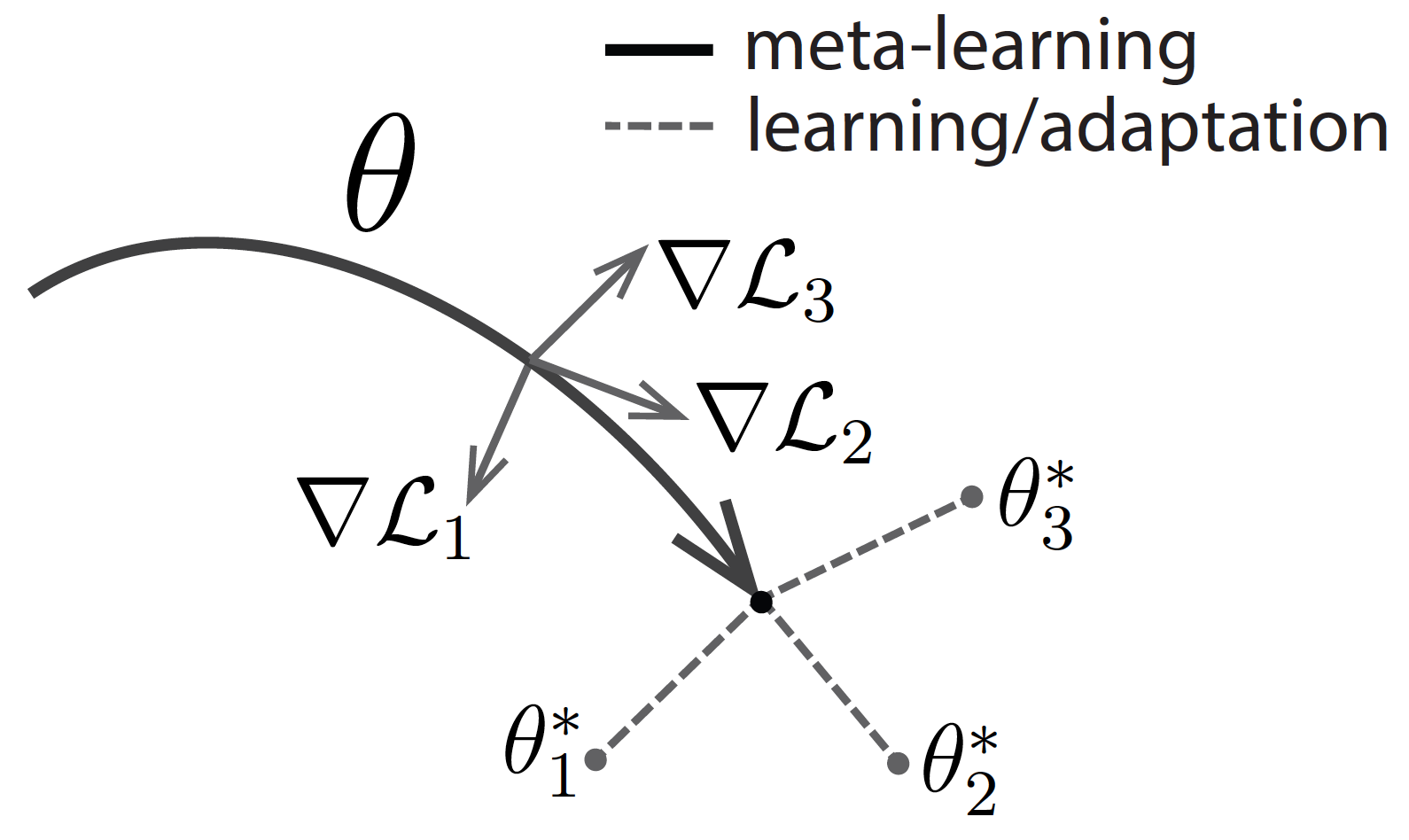
Ravi and Larochelle’s “Optimization as a Model for Few-Shot Learning” is the first paper that provides a standard formulation of the meta-learning setup, as seen in figure 2. They reframe equation 1 to equation 4 below, where D_{meta-train} is the meta-training data that allows our model to learn more efficiently. Here, D_{meta-train} corresponds to a set of datasets for predefined tasks D?, D?, …, Dn:
Next, they design a set of meta-parameters θ = p(θ|D_{meta-train}), which includes the necessary information about D_{meta-train} to solve the new tasks.
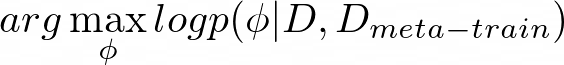
Mathematically speaking, with the introduction of this intermediary variable θ, the full likelihood of parameters for the original data given the meta-training data (in equation 4) can be expressed as an integral over the meta-parameters θ:
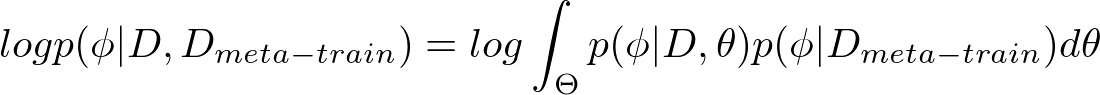
Equation 5 can be approximated further with a point estimate for our parameters:
To sum it up, the meta-learning paradigm can be broken down into two phases:
Let’s look at the optimization of the meta-learning method. Initially, our meta-training data consists of pairs of training-test set for every task:
There are k feature-label pairs (x, y) in the training set D??? and l feature pairs (x, y) in the test set D???:
During the adaptation phase, we infer a set of task-specific parameters ?*, which is a function that takes as input the training set D?? and returns as output the task-specific parameters: ?* = f_{θ*} (D??). Essentially, we want to learn a set of meta-parameters θ such that the function ?? = f_{θ} (D???) is good enough for the test set D???.
During the meta-learning phase, to get the meta-parameters θ*, we want to maximize the probability of the task-specific parameters ? being effective at new data points in the test set D???.
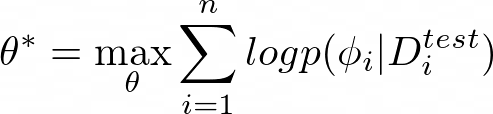
According to Chelsea Finn, there are two views of the meta-learning problem: a deterministic view and a probabilistic view.
The deterministic view is straightforward: we take as input a training data set D??, a test data point x_test, and the meta-parameters θ to produce the label corresponding to that test input y_test. The way we learn this function is via the D_{meta-train}, as discussed earlier.
The probabilistic view incorporates Bayesian inference: we perform a maximum likelihood inference over the task-specific parameters ?? — assuming that we have the training dataset D??? and a set of meta-parameters θ:
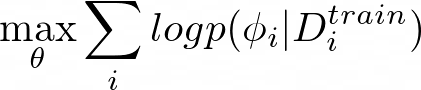
Regardless of the view, there two steps to design a meta-learning algorithm:
In this post, I will only pay attention to the deterministic view of meta-learning. In the remaining sections, I focus on the three different approaches to build up the meta-learning algorithm: (1) The black-box approach, (2) The optimization-based approach, and (3) The non-parametric approach. More specifically, I will go over their formulation, architectures used, and challenges associated with each method.
The black-box meta-learning approach uses neural network architecture to generate the distribution p(??|D???, θ).
During optimization, we maximize the log-likelihood of the outputs from g(??) for all the test data points. This is applied across all the tasks in the meta-training set:
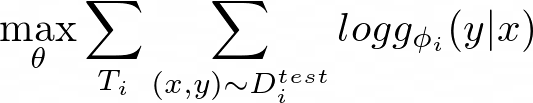
The log-likelihood of g(??) in equation 12 is essentially the loss between a set of task-specific parameters ?? and a test data point D???:
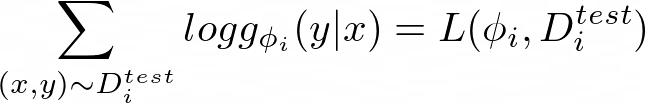
Then in equation 12, we optimize the loss between the function f_θ(D???) and the evaluation on the test set D???:
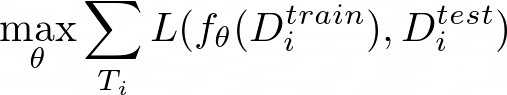
This is the black-box meta-learning algorithm in a nutshell:
The main challenge with this black-box approach occurs when ?? happens to be massive. If ?? is a set of all the parameters in a very deep neural network, then it is not scalable to output ??.
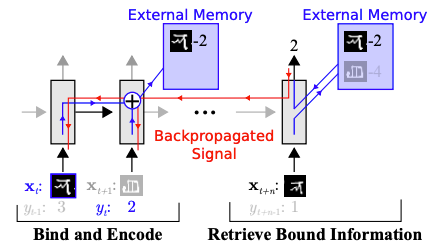
“One-Shot Learning with Memory Augmented Neural Networks” and “A Simple Neural Attentive Meta-Learner” are two research papers that tackle this. Instead of having a neural network that outputs all of the parameters ??, they output a low-dimensional vector h?, which is then used alongside meta-parameters θ to make predictions. The new task-specific parameters ?? has the form: ?? = {h?, θ}, where θ represents all of the parameters other than h.
Overall, the general form of this black-box approach is as follows:
Here, y?? corresponds to the labels of test data, x?? corresponds to the features of test data, and D??? corresponds to pairs of training data.
So what are the different model architectures to represent this function f?
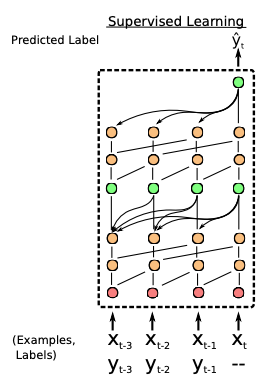
In conclusion, black-box meta-learning approach has high learning capacity. Given that neural networks are universal function approximators, the black-box meta-learning algorithm can represent any function of our training data. However, as neural networks are fairly complex and the learning process usually happens from scratch, the black-box approach usually requires a large amount of training data and a large number of tasks in order to perform well.
Okay, so how else can we represent the distribution p(??|D???, θ) in the adaptation phase of meta-learning? If we want to infer all the parameters of our network, we can treat this as an optimization procedure. The key idea behind optimization-based meta-learning is that we can optimize the process of getting the task-specific parameters ?? so that we will get a good performance on the test set.
Recall that the meta-learning problem can be broken down into two terms below, one that maximizes the likelihood of training data given the task-specific parameters and one that maximizes the likelihood of task-specific parameters given meta-parameters:
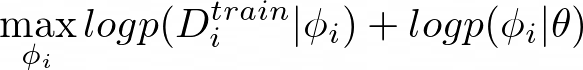
Here the meta-parameters θ are pre-trained during training time and fine-tuned during test time. The equation below is a typical optimization procedure via gradient descent, where α is the learning rate.
To get the pre-trained parameters, we can use standard benchmark datasets such as ImageNet for computer vision, Wikipedia Text Corpus for language processing, or any other large and diverse datasets that we have access to. As expected, this approach becomes less effective with a small amount of training data.
Model-Agnostic Meta-Learning (MAML) from Finn et al. is an algorithm that addresses this exact problem. Taking the optimization procedure in equation 17, it adjusts the loss so that only the best-performing task-specific parameters ? on test data points are considered. This happens for all the tasks:
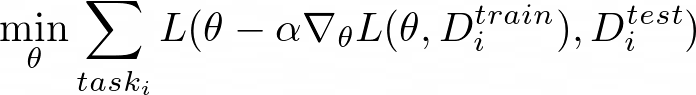
The key idea is to learn θ for all the assigned tasks in order for θ to transfer effectively via the optimization procedure.
This is the optimization-based meta-learning algorithm in a nutshell:
As provided in the previous section, the black-box meta-learning approach has the general form: y?? = f_{θ} (D???, x??). The optimization-based MAML method described above has a similar form below, where ?? = θ — α ∇_{θ} L(?, D???):
To prove the effectiveness of the MAML algorithm, in Meta-Learning and Universality, Finn and Levine show that the MAML algorithm can approximate any function of D???, x?? for a very deep function f. This finding demonstrates that the optimization-based MAML algorithm is as expressive as any other black-box algorithms mentioned previously.
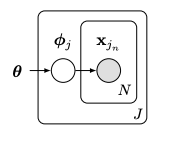
In “Recasting Gradient-Based Meta-Learning as Hierarchical Bayes”, Grant et al. provide another MAML formulation as a method for probabilistic inference via hierarchical Bayes. Let’s say we have a graphical model as illustrated in figure 5, where J is the task, x_{j_n} is a data point in that task, ?? are the task-specific parameters, and θ is the meta-parameters.
To do inference with respect to this graphical model, we want to maximize the likelihood of the data given the meta-parameters:

The probability of the data given the meta-parameters can be expanded into the probability of the data given the task-specific parameters and the probability of the task-specific parameters given the meta-parameters. Thus, equation 20 can be rewritten as:
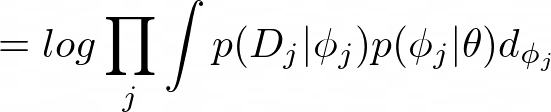
This integral in equation 21 can be approximated with a Maximum a Posteriori estimate for ??:
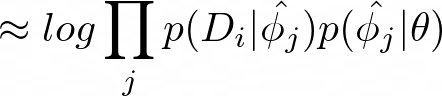
In order to compute this Maximum a Posteriori estimate, the paper performs inference on Maximum a Posteriori under an implicit Gaussian prior — with mean that is determined by the initial parameters and variance that is determined by the number of gradient steps and the step size.
There have been other attempts to compute the Maximum a Posteriori estimate in equation 22:
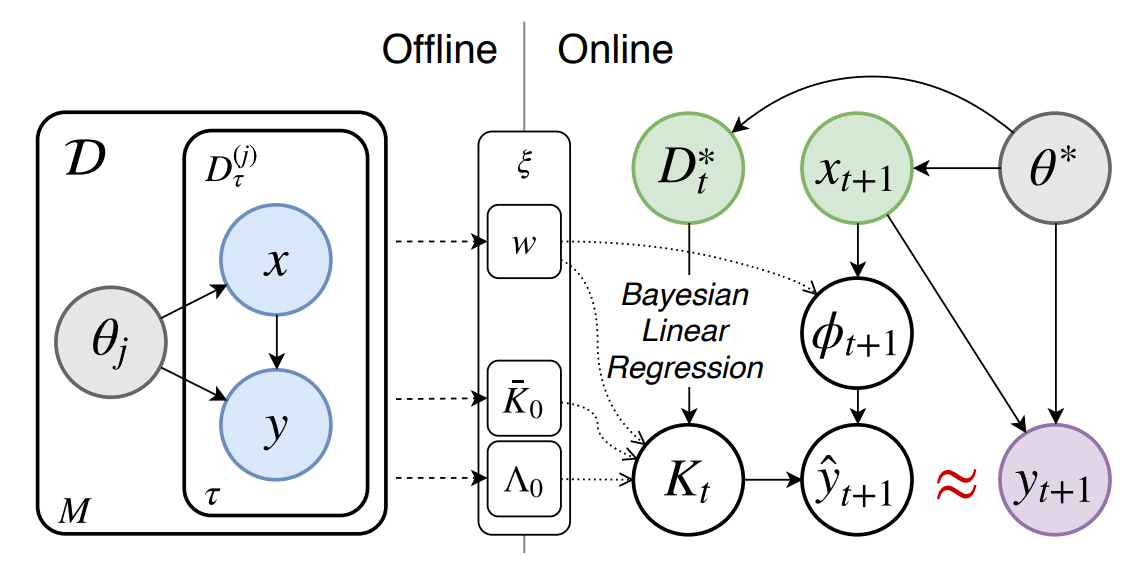
The MAML method requires very deep neural architecture in order to effectively get a good inner gradient update. Therefore, the first challenge lies in choosing that architecture. Kim et al. propose Auto-Meta, which searches for the MAML architecture. They found that the highly non-standard architectures with deep and narrow layers tend to perform very well.
The second challenge that comes up lies in the unreliability of the two-degree optimization paradigm. There are many different optimization tricks that can be useful in this scenario:
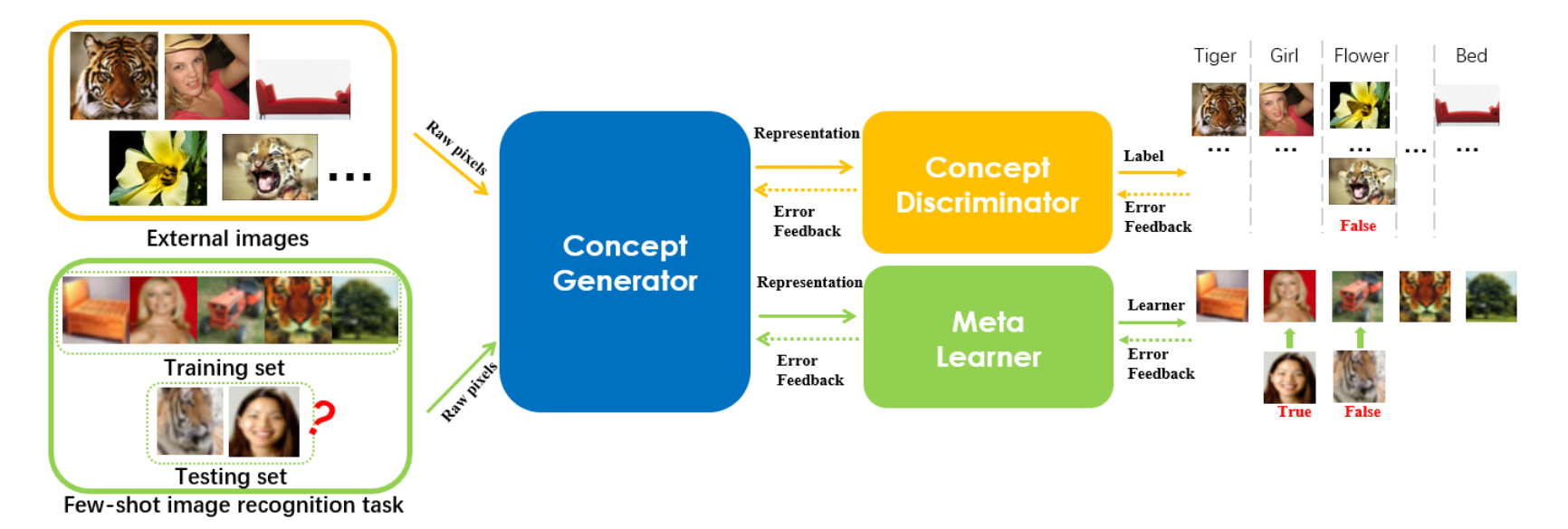
In conclusion, optimization-based meta-learning works by constructing a two-degree optimization procedure, where the inner optimization computes the task-specific parameters ? and the outer optimization computes the meta-parameters θ. The most representative method is the Model-Agnostic Meta-Learning algorithm, which has been studied and improved upon extensively since its conception.
The big benefit of MAML is that we can optimize the model’s initialization scheme, in contrast to the black box approach where the initial optimization procedure is not optimized. Furthermore, MAML is highly consistent, which extrapolates well to learning problems where the data is out-of-distribution (compared to what the model has seen during meta-training). Unfortunately, because optimization-based meta-learning requires second-order optimization, it is very computationally expensive.
So can we perform the learning procedure described above without a second-order optimization? This is where non-parametric methods fit in.
Non-parametric methods are very effective at learning with a small amount of data (k-Nearest Neighbor, decision trees, support vector machines). In non-parametric meta-learning, we compare the test data with the training data using some sort of similarity metric. If we find the training data that are most similar to the test data, we assign the labels of those training data as the label of the test data.
This is the non-parametric meta-learning algorithm in a nutshell:
Unlike the black-box and optimization-based approaches, we no longer have the task-specific parameters ?, which is not required for the comparison between training and test data.
Now let’s go over the different architectures used in non-parametric meta-learning methods.
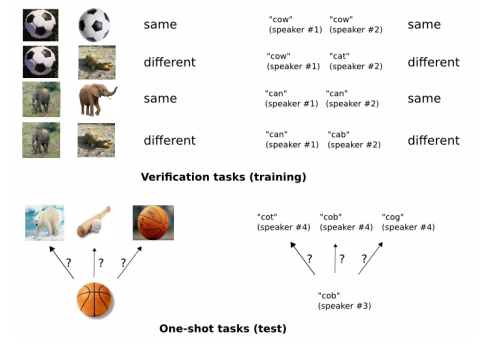
Koch et al. propose a Siamese network that consists of two tasks: the verification task and the one-shot task. Taking in pairs of images during training time, the network verifies whether they are of the same class or different classes. At test time, the network performs one-shot learning: comparing each image x?? to the images in the training set D??? for a respective task and predicting the label of x?? that corresponds to the label of the closest image. Figure 9 illustrates this strategy.
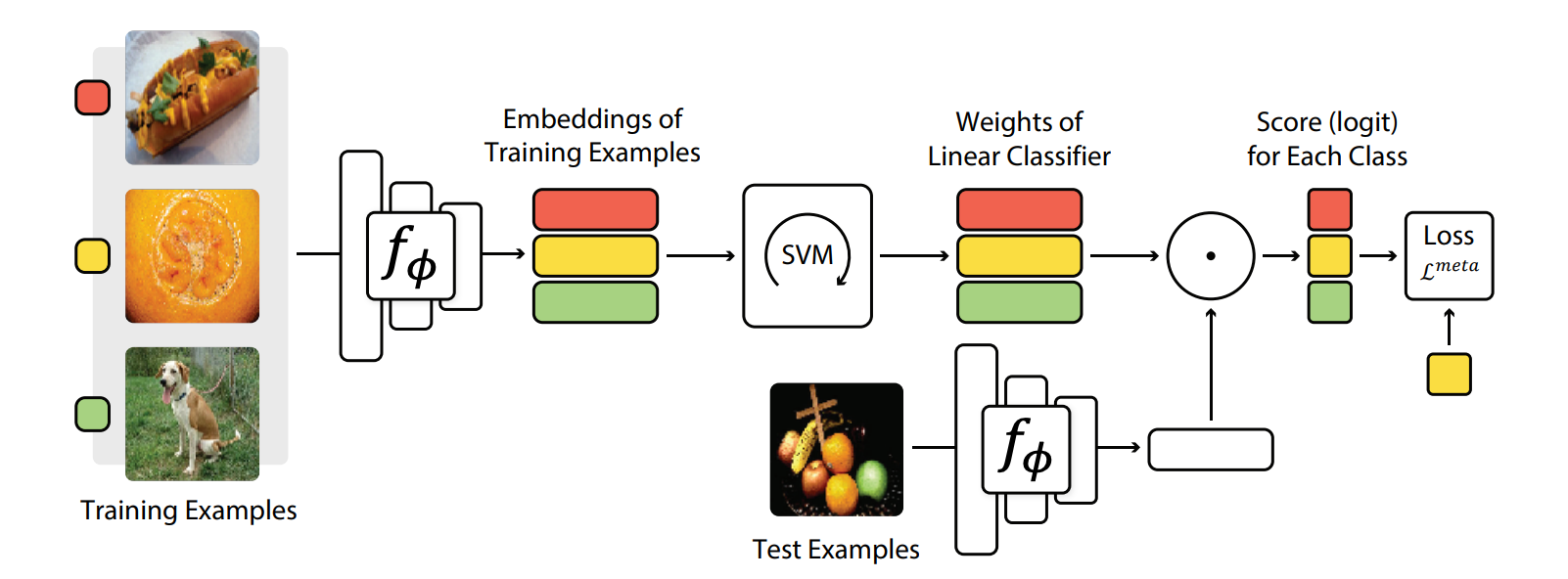
Vinyals et al. propose Matching Networks, which matches the actions happening during training time at test time. The network takes the training data and the test data and embeds them into their respective embedding spaces. Then, the network compares each pair of train-test embeddings to make the final label predictions:
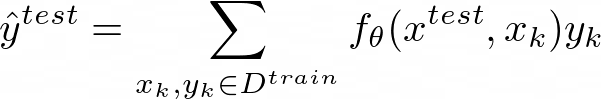
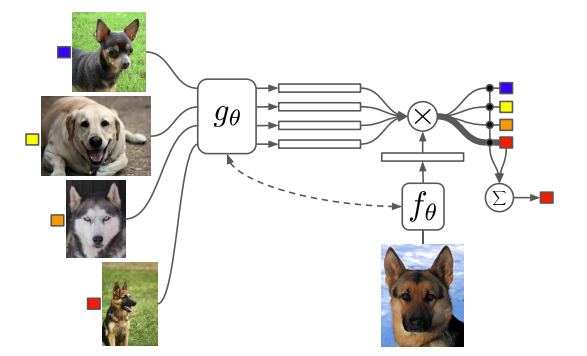
The Matching Network architecture used in Matching Networks includes a convolutional encoder network to embed the images and a bi-directional Long-Short Term Memory network to produce the embeddings of such images. As seen in figure 10, the examples in the training set match the examples in the test set.
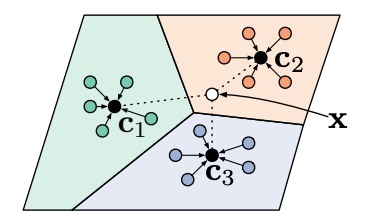
Snell et al. propose Prototypical Networks, which create prototypical embeddings for all the classes in the given data. Then, the network compares those embeddings to make the final label predictions for the corresponding class.
Figure 11 provides a concrete illustration of how Prototypical Networks look like in the few-shot scenario. c?, c?, and c? are the class prototypical embeddings, which are computed as:
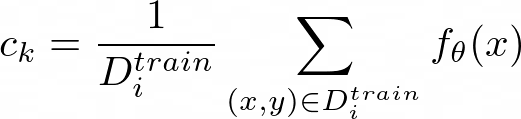
Then, we compute the distances from x to each of the prototypical class embeddings: D(fθ(x), c_k).
To get the final class prediction p_θ(y=k|x), we look at the probability of the negative distances after a softmax activation function, as seen below:
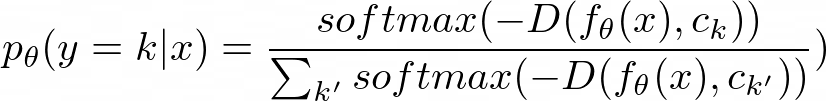
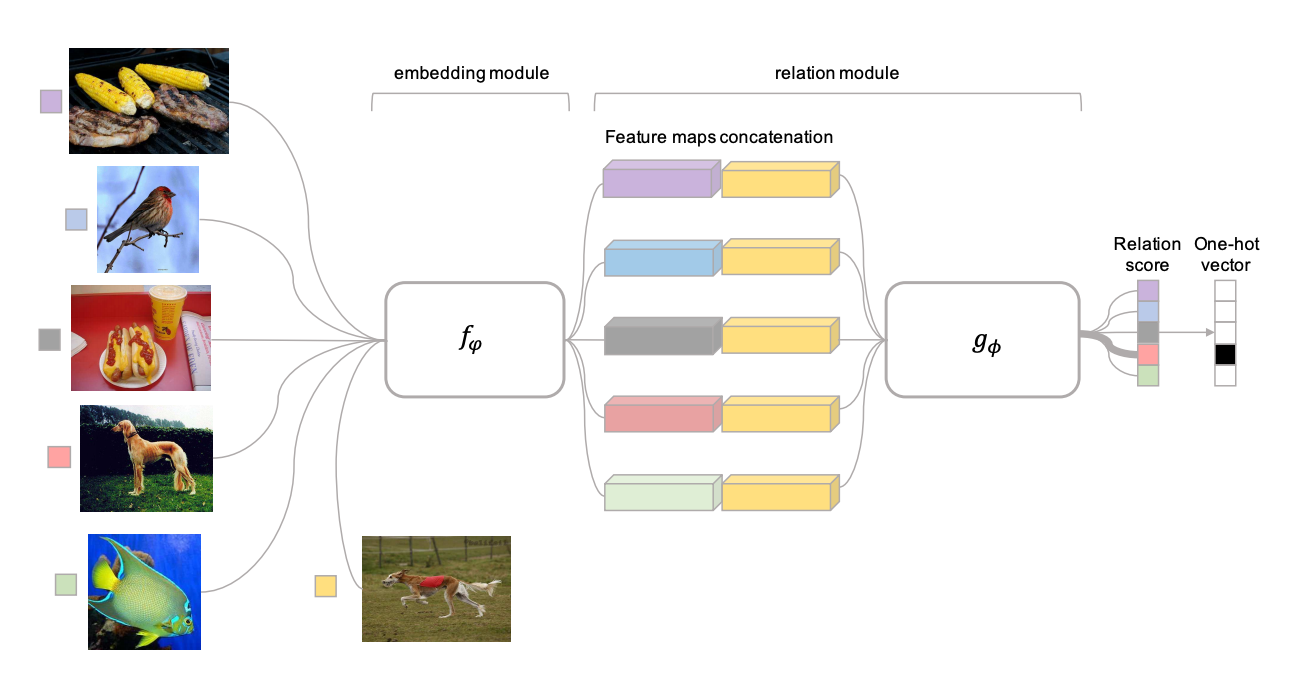
For non-parametric meta-learning, how can we learn deeper interactions between our inputs? The nearest neighbor probably will not work well when our data is high-dimensional. Here are three papers that attempt to accomplish this:
In this post, I have discussed the motivation for meta-learning, the basic formulation and optimization objective for meta-learning, as well as the three approaches regarding the design of the meta-learning algorithm. In particular:
There are a lot of exciting directions for the field of meta-learning, such as Bayesian Meta-Learning (the probabilistic view of meta-learning) and Meta Reinforcement Learning (the use of meta-learning in the reinforcement learning setting). I’d certainly expect to see more real-world applications in wide-ranging domains such as healthcare and manufacturing using meta-learning under the hood. I’d highly recommend going through the course lectures and take detailed notes on the research on these topics!
If you would like to follow my work on Recommendation Systems, Deep Learning, MLOps, and Data Journalism, you can follow my Medium and GitHub, as well as other projects at https://jameskle.com/. You can also tweet at me on Twitter, email me directly, or find me on LinkedIn. Or join my mailing list to receive my latest thoughts right at your inbox!
原文:https://www.cnblogs.com/wangxiaocvpr/p/13045472.html