实验八 文件
掌握读写文本文件或 CSV 文件,进而对数据进行处理的方法。
【实验条件】
PC机或者远程编程环境
完成二个编程题。
1)水浒传-词频统计
描述
使用词频统计的方法,生成《水浒传》出场次数最多的10个人物的姓名。????????????????????????????????????????????????????????????????????????????????
水浒传文本下载:
读取《水浒传》文本文件的代码如下:????????????????????????????????????????????????????????????????????????????????

txt = open("AllManAreBrothers.txt", "r", encoding="utf-8").read()
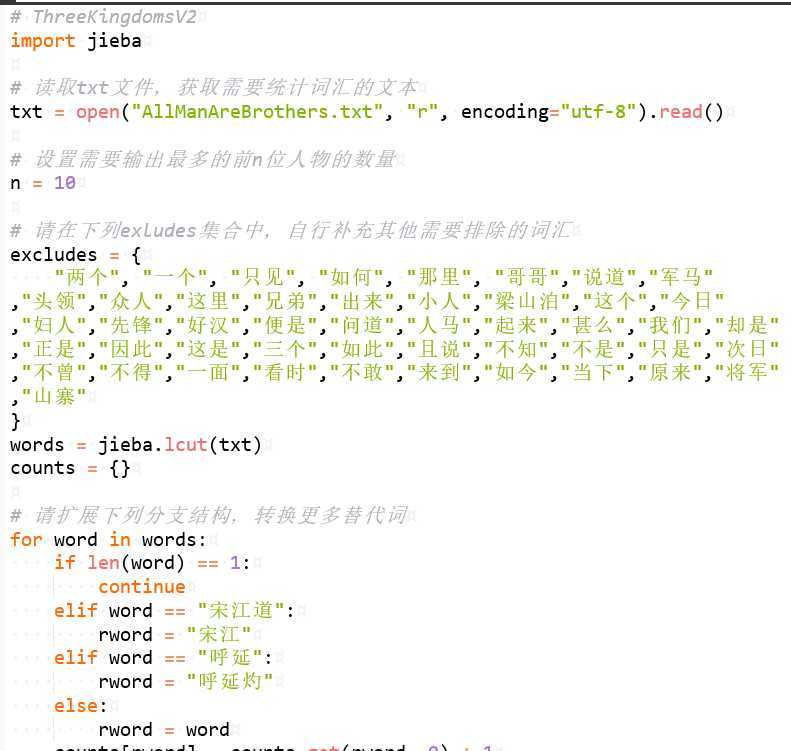
代码模板:
# ThreeKingdomsV2
import jieba
# 读取txt文件,获取需要统计词汇的文本
txt = open("AllManAreBrothers.txt", "r", encoding="utf-8").read()
# 设置需要输出最多的前n位人物的数量
n = 10
# 请在下列exludes集合中,自行补充其他需要排除的词汇
excludes = {
"两个", "一个", "只见", "如何", "那里", "哥哥",
}
words = jieba.lcut(txt)
counts = {}
# 请扩展下列分支结构,转换更多替代词
for word in words:
if len(word) == 1:
continue
elif word == "宋江道":
rword = "宋江"
else:
rword = word
counts[rword] = counts.get(rword, 0) + 1
# 实现删除干扰词汇功能(此处约2行代码)
# 使用列表和lambda功能实现 词汇的排序 (此处约2行代码)
# 依次输出统计次数最多的前n位(此处约3行代码)
2)血压心率分析
描述
BP.txt”是以逗号分隔的日期、血压、心率记录数据文本文件( open(‘BP.txt‘,encoding="gbk"))
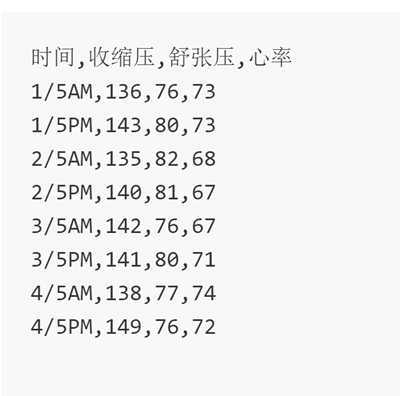
统计收缩压、舒张压、心率的总平均值(保留3位小数)。

【实验过程】
1.水浒传-词频统计
代码输入
注意点:要排除非人名的词语
2.血压心率分析


原文:https://www.cnblogs.com/maxanywany/p/13045018.html