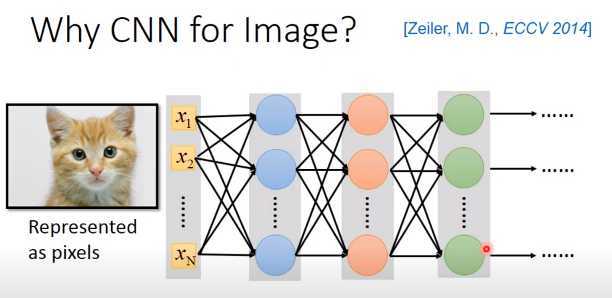
我们知道CNN常常被用在图像处理上,当然也可以用一般的神经网络做图像处理,input一张图像,把图像表示成里面的像素点,也就是一个很长的向量,output就是类别,1000个类别就是1000个维度。

实际上,我们训练神经网络的时候,知道网络结构里的每一个神经元代表了一个最基本的分类器,实际很多文献也得出这样的结论。例如第一个隐藏层的神经元是最简单的分类器,检测绿色、黄色、斜纹等等特征是否出现,第二个隐藏层的神经元做比第一个隐藏层更复杂的东西,根据第一层的output,如果看到直线横线,就判断是窗框的一部分,看到棕色的直线纹就判断是木纹,看到斜条纹加灰色就判断是轮胎的一部分。第三层再根据第二层的output,会做更复杂的事情,比如看到蜂巢就激活,看到车轮被激活,看到人的上半身被激活。
现在问题是使用一般的全连接神经网络做图像处理,往往会需要很多的参数。如果是一张100 * 100 * 3的彩色图像,其实算很小的图像了,把它变成向量会有100 * 100 * 3个数,一个像素点用3个数表示,那这个向量就是3万维。input 是3万维,假设每层隐藏层有1000个神经元,那么第一个隐藏层的参数就有30000 * 1000个了,参数太多了。
CNN其实是简化神经网络的架构,根据人的知识知道有一些参数是用不上的,那么一开始就过滤掉。
CNN比一般的DNN还要简单,把DNN里的一些参数去掉,就是CNN。

为什么可以去掉一些参数?
在图像处理里,我们知道大部分图案是比整张图像小的,如果第一层隐藏层某个神经元是在侦测某一种图案是否出现,那就只需要看图像的一小部分。
比如上图,有些神经元在侦测鸟嘴,有些在侦测爪子,有些在侦测翅膀、尾巴,之后合起来就可以侦测鸟是否出现。假设第一层隐藏层的某个神经元是在侦测鸟嘴是否出现,那就只需要红色框框里的图像就可以了。
所以每个神经元只需要连接到一个小区域,不需要连接整个图像。
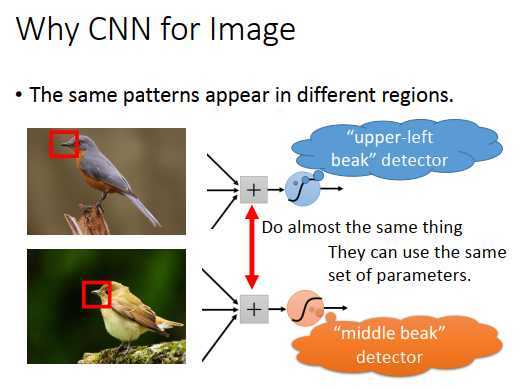
为什么可以去掉一些参数?
第二个观察可以看到,同样的图案(代表同样的含义或形状)会出现在图像的不同部分,但是使用同样的神经元和参数可以侦测出来。
比如上图里两个鸟嘴,不需要训练两个不同的检测器去分别检测左上角鸟嘴和中间鸟嘴,这样过于冗余。可以让这两个神经元用同一组参数,做的事情是一样的。
这样就可以减少需要的参数量。

我们可以对一张图像做子采样,把奇数行偶数列的像素点拿掉,变成原来的1/10的大小,这样做不会影响人对这张图像的理解,如上面两张图像,看起来可能没有区别。
所以做子采样这件事情,对图像识别来说,可能没有太多影响,用这个思想把图像缩小,就可以减少需要的参数量
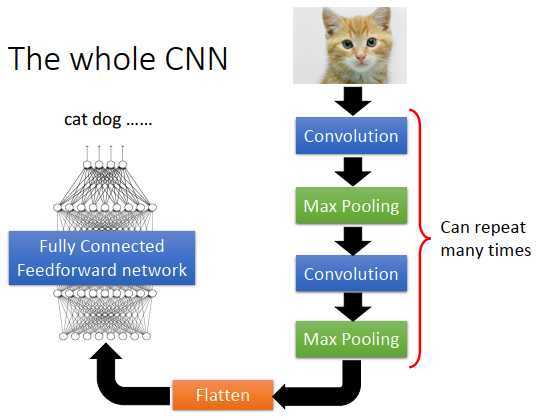
首先,input一张图像,然后通过卷积层,接下来通过池化层,再通过卷积层,再通过池化层。卷积层+池化层这个流程可以反复数次(具体几次要事先决定)。做完卷积和池化后,要做flatten(压平),把flatten的输出丢到全连接神经网络里,最后得到图像识别的结果。
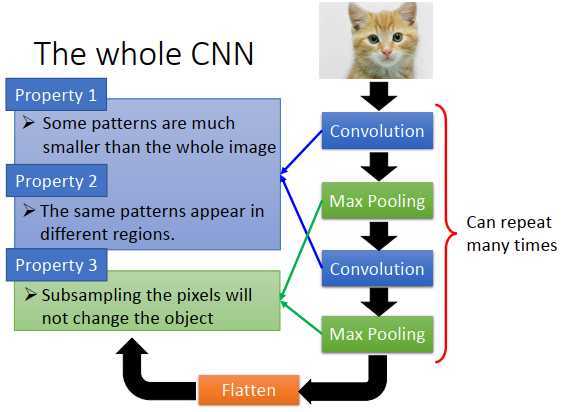
我们基于对3个图像处理的特性得出了CNN架构
第一个特性是:要侦测一个图案,不需要看整张图,只需要图像的一小部分
第二个特性是:同一个图案,会出现在一张图像的不同区域
第三个特性是:我们可以做子采样
第一个、第三个特性对应卷积层的处理,第三个特性对应池化层的处理

类比第一个特性:图案比整张图像小
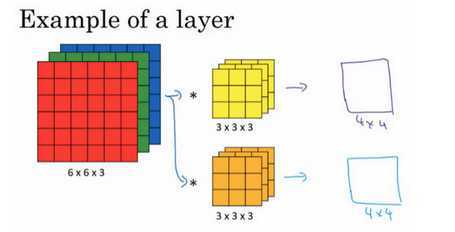
假设input是一张6 * 6 的图像(黑白的,每个像素点只需要一个值来表示),例如上图1代表有墨水,0代表没有墨水。在卷积层里,有一堆过滤器,每个过滤器作用等同于全连接神经网络里的每个神经元。每个过滤器是一个矩阵,例如上图的过滤器是3 x 3的矩阵,而矩阵里的每个值就是网络的参数,跟神经元的权重和偏差一样,要通过训练数据学习出来。3 * 3 的过滤器意味着在一个3 * 3范围内侦测图案,不看整个图像,只在3 * 3范围内决定一个图案是否出现。
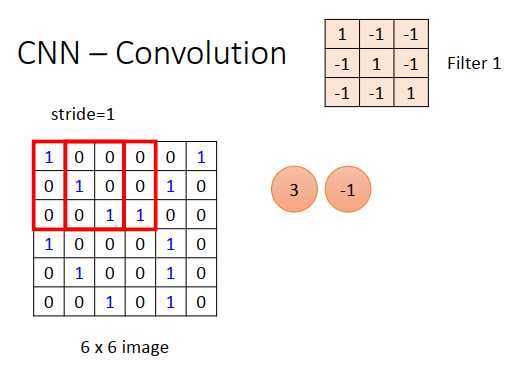
有第一个3 * 3 矩阵,放在图像左上角(卷积的方式),图像里的3 * 3 矩阵\(\begin{bmatrix} 1 & 0&0 \\ 0 & 1&0 \\0&0&1 \\ \end{bmatrix}\)和过滤器做内积,结果为3。然后过滤器移动一个步长=1到\(\begin{bmatrix} 0 & 0&0 \\ 1 & 0&0 \\0&1&1 \\ \end{bmatrix}\)和过滤器做内积为-1
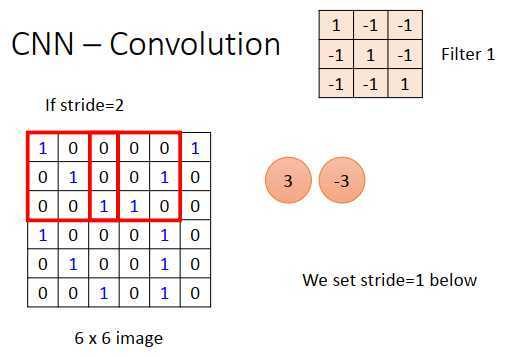
如果步长=2,那么就是移动到\(\begin{bmatrix} 0 & 0&0 \\ 0 & 0&1 \\1&1&0 \\ \end{bmatrix}\),内积是-3。
类比第二个特性:同一个图案,会出现在一张图像的不同区域
我们这里设置步长=1
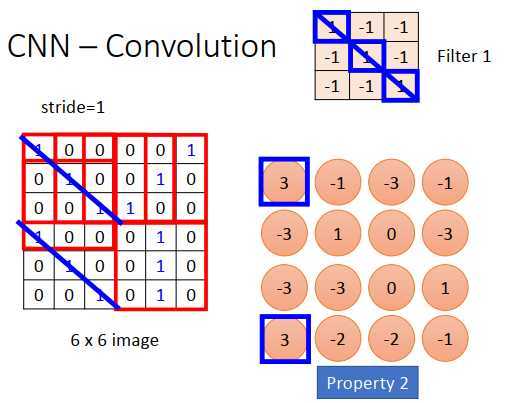
内积的结果如上图右下所示,一个6 * 6矩阵,经过卷积后得到一个4 * 4矩阵。
观察过滤器矩阵的值,斜对角全为1,所以作用就是检测斜对角有没有出现(1,1,1),在整个图像里就是检测有没有斜对角为(1,1,1)的图案,如上图蓝色斜线。
4 * 4矩阵中,左上和左下出现了最大的值,说明过滤器要侦测的图案出现在了原图像的左上角和左下角。
这里考虑到了特性二,两个不同位置的相同图案都用过滤器1就可以侦测出来。
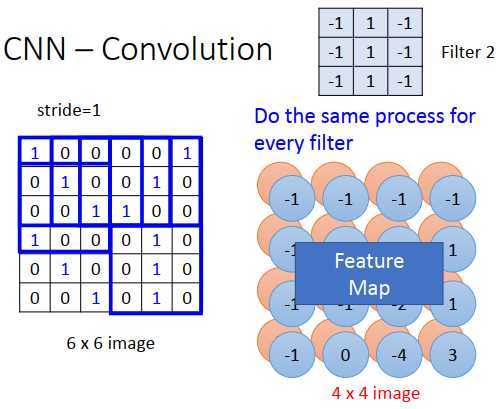
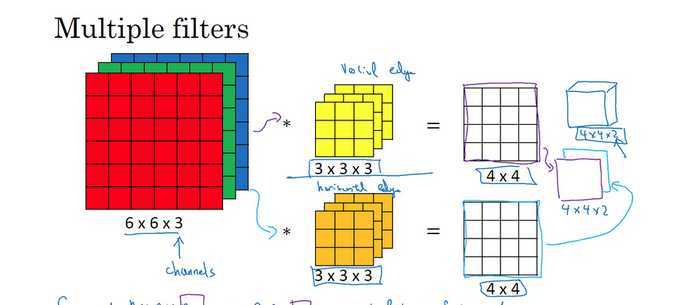
在一个卷积层里,会有一大堆的过滤器,之前只是一个过滤器的结果。会有另一个过滤器,有不同的参数,例如上图的过滤器2,起作用的形式和过滤器1一样,和图像矩阵做内积,得到另一个4 * 4的矩阵。
两个4 * 4矩阵(上图红色矩阵和蓝色矩阵)合起来叫做feature map(特征图),有100个过滤器,就有100个 image。
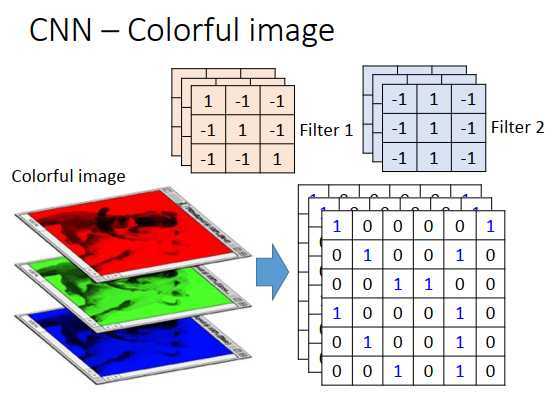
之前是黑白的图像,如果使用彩色图像呢?
彩色图像由RGB组成,一张彩色图像就是3个矩阵(立方体)叠在一起。这时候过滤器就不是一个矩阵,过滤器也是一个立方体。彩色图像由RGB表示一个像素点,input就是3 * 6 * 6,过滤器就是3 * 3 * 3。
三个颜色代表三个channel(通道),过滤器有3个矩阵,每个矩阵和对应的channel(通道)做内积。
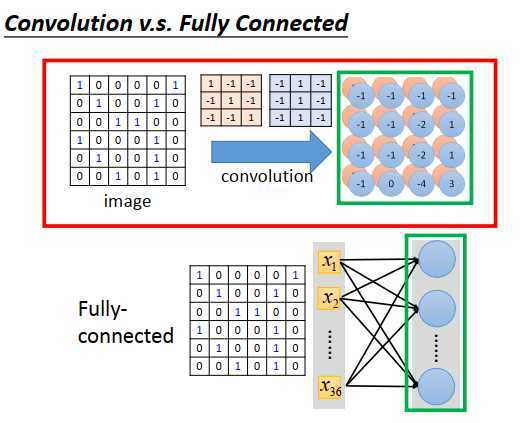
卷积这件事情,就是一个全连接层去掉一个权重,特征图的output就是一个隐藏层神经元的output。

给像素点编号,从左到右,从上到下编号为1,2,3...,34,35,36
把过滤器1放在左上角做内积得到一个值3,考虑的像素点编号是1,2,3,7,8,9,13,14,15
拉直6 * 6 图像变成一个长度为36的向量,过滤器1考虑的像素点如上图右边所示,相当于一个output 为3的神经元连接到1,2,3,7,8,9,13,14,15像素点,神经元的连接权重就是过滤器里的值。如上图所示颜色相同的线和圈。
本来一个全连接的神经元要连接36个像素点,现在只连接9个像素点,因为我们知道侦测一个图案不需要看整张图像,就看9个像素点表示的区域就行了。这么做,就用了比较少的参数。
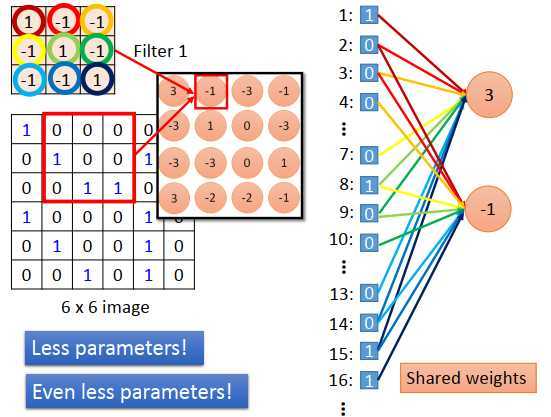
过滤器在图像上移动一个步长=1,output=-1。这个-1是另外一个神经元的output,这个神经元连接到编号为2,3,4,8,9,10,14,15,16的像素点,连接权重还是过滤器的值。这意味着,原本在全连接结构中有各自独立参数的两个神经元,在做卷积的时候,不仅连接的权重数量减少了,而且共用了权重值。例如output=3的神经元连接到像素点1的权重等于output=-1的神经元连接到像素点2的权重。那么共用权重值,意味着使用的参数数量更少了。
跟原来的反向传播一样,只是有些权重永远等于0,不去训练。用一般的反向传播方法,算出一个权重的梯度,然后把被共享的权重的梯度平均,再用平均后的梯度去update参数。
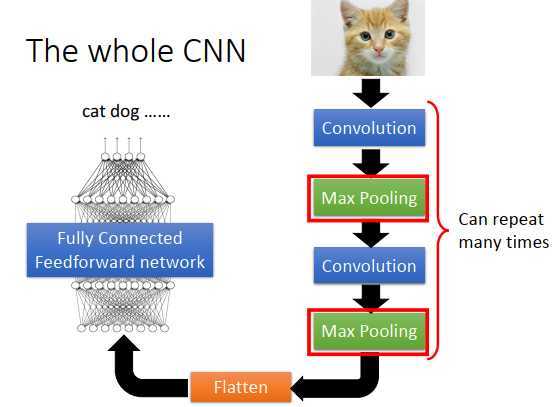
池化,就是做子采样。
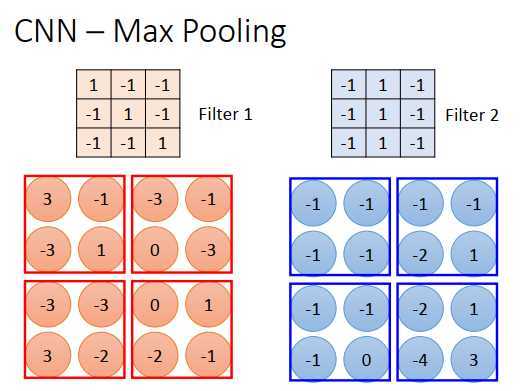
根据过滤器1,得到一个4 * 4的矩阵,根据过滤器2,得到另一个4 * 4的矩阵。把output 4个一组,每组里可以取平均、取最大,把原来的4个值合成一个值,这样就可以把图像缩小。
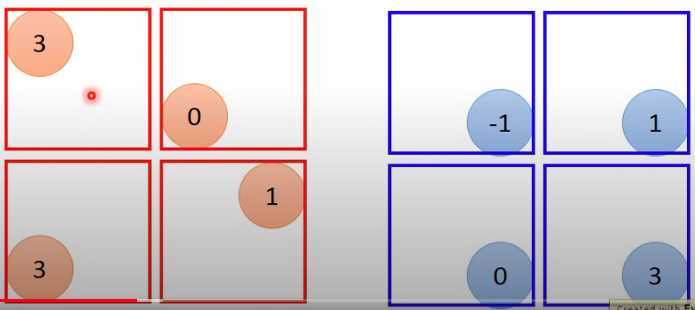
现在取最大max
可能会有问题说把这种max操作放到网络里不就没法微分了吗?
其实是可以的,类似Maxout做微分。
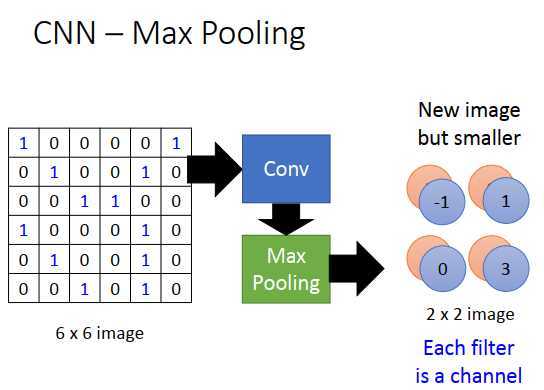
做一次卷积+池化后,把原来的6 * 6图像变成了2 * 2图像,2 * 2图像的深度(每个像素点用多少个值表示)取决于有多少个过滤器,如果有50个过滤器,2*2 图像就有50维,上图是只用两个过滤器,那就是2维。
所以上图右边,就是一个新的比较小的图像,每个过滤器代表了一个channel(通道)。
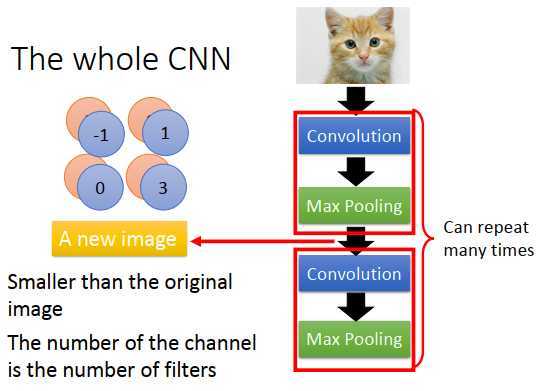
卷积+池化,可以重复叠加很多次,通过一个卷积+池化,就得到一个新的比较小的图像,再做一次又是一个更小的图像。
这里有个问题,就是第一个卷积后得到25个矩阵,第二卷积有25个过滤器,那是不是之后会有25*25个矩阵?
不会这样,做完第一次卷积得到25个矩阵,做完第二次后还是25个矩阵。例如输入是三个通道的6*6矩阵数据(一个立方体,6 * 6 * 3),有两个过滤器(也是立方体,三个通道,3 * 3 * 3),则输出为4 * 4 * 2。
那第二层的过滤器其实是3 *3 *2 的,变成两个通道的了,输出后还是2个通道的。
看吴恩达老师的深度学习可能清楚一点。
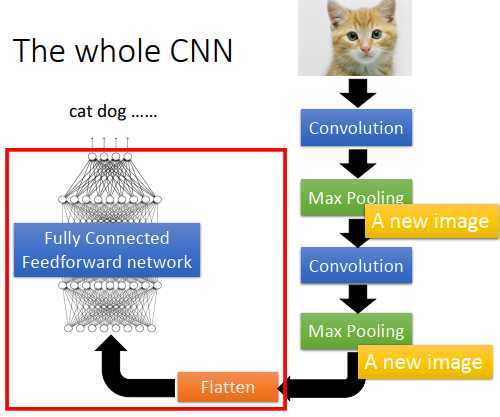
最后是flatten(压平)和全连接神经网络部分。
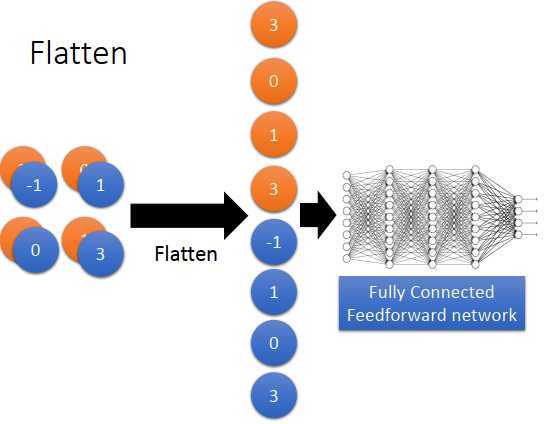
flatten(压平)的意思是,把特征图拉直,然后丢到一个全连接神经网络里。
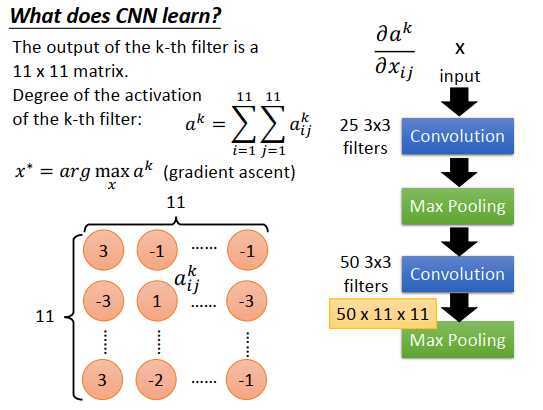
分析第一个层的过滤器是比较容易的,里面每个过滤器就是一个3 * 3 的矩阵,对应3 * 3 范围内的9个像素点,只要看到矩阵的值,就知道在检测什么。
第二层的过滤器没法知道在做什么,虽然也是3 *3的矩阵,总共50个。但是这些过滤器的输入不是像素点,而是在上一层做完卷积和池化后的输出。就算知道第二层过滤器的矩阵值,也不知道在检测什么。另外第二层过滤器考虑的不是原图3 *3的像素点,而是比原图3 *3 像素点更大的范围,因为在第一层的池化后,压缩了原图3 *3的区域,第二层过滤器是在压缩后的图像里再选取3 * 3 像素点,相当于扩大了原图检测的范围。
那怎么分析第二层过滤器在做什么?
第二层的50个过滤器,每个过滤器的输出是一个11 * 11的矩阵。把第k个过滤器输出拿出来如上图左下,矩阵元素表示为\(\large a_{ij}^k\) (第k个过滤器,第i个行,第j个列)。接来下定义一个“Degree of the activation of the k-th filter”(第k个滤波器的激活程度),值代表第k个过滤器的被激活程度(input和第k个过滤器侦测的东西有多匹配)。
第k个过滤器被激活程度表示为:\(\large \alpha^k=\sum\limits_{i=1}^{11}\sum\limits_{j=1}^{11}a_{ij}^k\),11 * 11 矩阵所有元素值之和。
找一张图像,可以让第k个过滤器被激活程度最大,如果做到这件事情?
称input的图像为x,目标是找一个让\(\alpha^k\)最大的x,如何找到这个x?
使用梯度上升,因为我们的目标是最大化\(\large \alpha^k\) 。现在是把x当做我们要找的参数,对x用梯度上升。原来CNN的input是固定的,model的参数使用梯度下降求解。现在反过来,model的参数是固定的,使用个梯度上升更新x,让被激活程度最大。
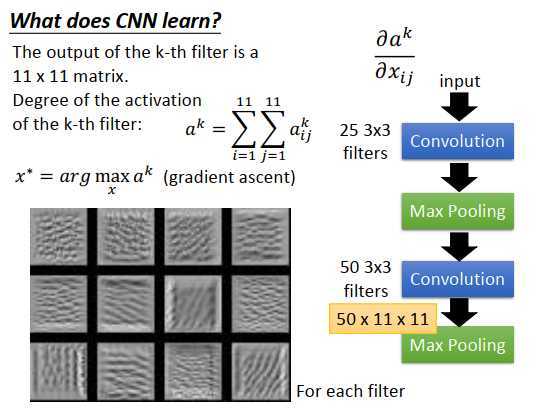
上图左下,是随便取12个过滤器后对x做梯度上升后的结果,每个过滤器都找到一张图像,这张图像让这个过滤器的被激活程度最高。如果有50个过滤器,理论上可以找50张图像。
这12张图像有一个共同的特征:是某种纹路在图上不断反复。为什么会这样?
看第三张图像,都是小小的斜条纹,这意味着第三个过滤器是在检测是否有斜的条纹。因为过滤器考虑的范围是很小的,所以原图像上任何地方出现一个小小的斜纹的话,这个过滤器就会被激活,输出值就会很大。如果原图像所有范围都是这种小小的条纹,那这个过滤器的被激活程度就最大。
你会发现每个过滤器都是在检测某一种图案(某一种线条),例如上图左下第3个过滤器是检测斜条纹,第4个是检测短、直的线条,第6个是检测斜成一定程度的线条等等。
每个过滤器都在检测不同角度的线条。
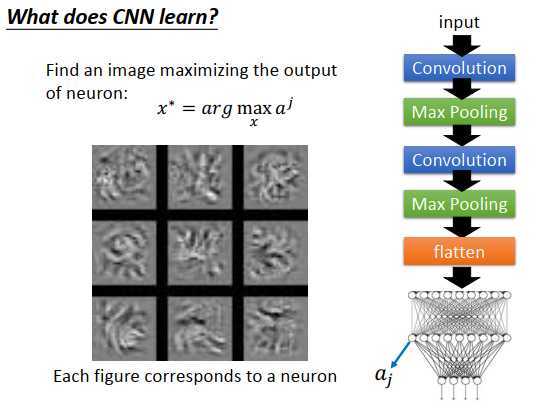
接下来分析全连接的隐藏层。
做完卷积和池化后,会做flatten(压平),把压平后的结果丢到神经网络里去。我们也想知道在这个神经网络的隐藏层里,每个神经元都在干什么。如法炮制之前的做法,定义第j个神经元的输出是\(\large a_j\),然后找一张图像x,使\(\large a_j\)最大。
找到的图像如上图左下所示,9张图像,是对应神经元的输出最大。你会发现跟刚才过滤器观察的图案很不一样,过滤器观察的是类似纹路的东西,因为过滤器只考虑了原图像的一部分区域。输出通过压平后,现在每个神经元是去看整张图像,能使神经元激活程度最高的图像不再是纹路这种小图案,而是一个完整的图形,虽然看起来完全不像是数字,但神经元被激活后也的确在侦测一个完整的数字。
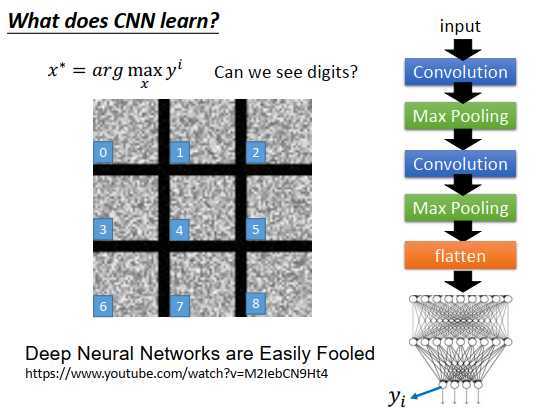
考虑最后的输出呢?
如果最后的输出是10维的,每一维对应一个数字。把某一维拿出来,找一张图像使那个维度的输出最大。例如现在要找一张图像,使输出层上对应数字1的神经元的输出最大,理论上这张图像看起来就是数字1
但是实际的图像如上图左边所示,每张图像分别代表0,1,2,3,4,5,6,7,8
那为什么是这种像电视雪花一样的图像,而不是数字呢?
因为今天这个神经网络,学习到的东西跟人类一般认知是不一样的。

能不能让这些图像看起来更像数字?
我们知道,一张图像是不是一个数字,有一些基本的假设。比如上图左边,人类看起来显示不是数字。那么我们对x做一些正则约束,告诉机器,虽然有些x可以让y很大,但是这些x不是数字。
那加些什么约束呢?
比如最简单的想法,图像上的白点是有墨水(笔画)的地方,对一个数字来说,有白点的部分是有限的,数字的笔画只占图的一小部分,所以我们要对x做一些限制。
假设\(\large x_{ij}\)是图像像素点的值,每张图像有28 * 28个像素点。把所有像素点的值取绝对值并求和(相当于L1正则),我们希望找一个x,让\(y^i\)越大的同时,也让像素点绝对值之和越小。那我们找出来的图像大部分的地方就不是白色的。
最后得到的结果如上图右边所示,和左边的图看起来,已经可以隐约看出来是个数字了。

你给机器一张图像,机器会在这张图像里面,加上它学习到的东西。
比如把上图丢到CNN里面去,然后把某过滤器或者某个全连接隐藏层拿出来(一个向量),假设是\(\begin{bmatrix} 3.9 \\ -1.5 \\ 2.3 \\ \vdots \end{bmatrix}\)
然后把3.9、2.3调大(本来是正的值调大),-1.5调小(负的值调小),正的更正,负的更负。找一个图像使过滤器或者隐藏层(拿出来的)的输出是调整后的向量。这么做的意思是让CNN夸大化它看到的东西。

找到的图像会变成上图所示,出现很多奇怪的东西。右边看起来是一头熊,原来是一颗石头。对机器来说,本来就觉得石头像一头熊,强化它的认知后,就学习出来更像一头熊的图案。这个就是Deep Dream。
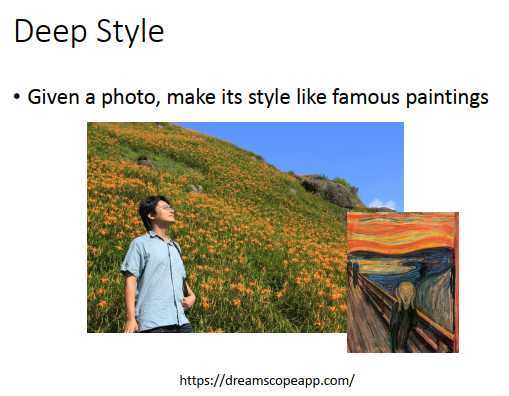
比Deep Dream更进阶的版本
今天input一张图像,然后让机器去修改这张图像,让它有另一张图的风格,比如让上图看起来是呐喊。

得到的结果就如上图。
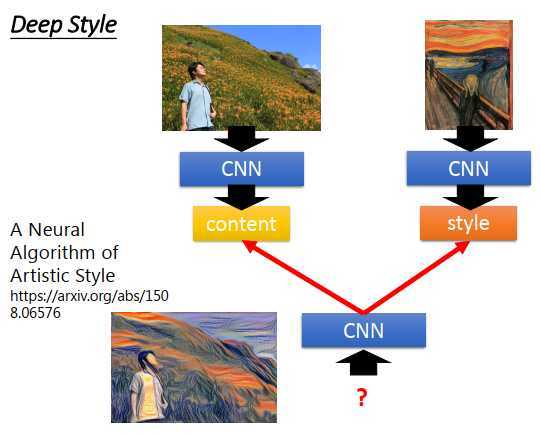
这个做法的精神是,把原来的图像丢给CNN,得到CNN过滤器的输出,代表一张图像里有什么样的内容。
然后把呐喊这张图也丢到CNN里,也得到过滤器的输出,但这时候考虑的不是过滤器输出的绝对值,而是考虑过滤器和过滤器输出之间的关系,这个关系代表了一张图像的风格。接下来用同一个CNN找一张图像,这张图像的内容像原图像的内容(过滤器的输出类似),同时这张图像的风格像呐喊的风格(过滤器输出之间的关系类似)。
找一张图片同时最大化内容和风格(使用梯度上升更新参数),得到的结果就像两张图片结合一样。
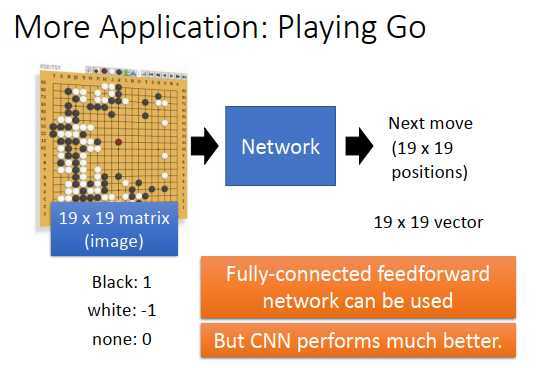
CNN现在应用在不同领域,不只是图像处理,比如知名的应用有下围棋。
为什么可以用在下围棋上?
要让机器下围棋,不一定要用CNN,一般的神经网络也可以做这件事情。只要学习一个网络,也就是找一个函数,输入是棋盘,输出是棋盘上的位置,根据棋盘的盘势,判断下一步落子的位置。
输入是19 * 19 向量,向量每一维是棋盘上的一个位置(是黑子则值为1,是白子则值为-1,反之则为0),丢到一个全连接的神经网络,输出也是19 * 19 的向量(每一维对应棋盘一个位置),那这样机器就可以学会下围棋了。
实际采用CNN会得到更好的效果
采用CNN是什么意思?
之前举的例子都是把CNN用在图像上面,input是一个矩阵。用到下棋上,只要把19 * 19 的向量表示为19 * 19 的矩阵。对CNN来说,就是把棋盘和棋子当成一个图像,然后输出下一步落子的位置。
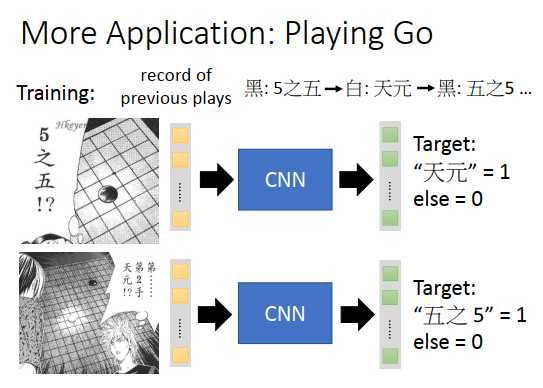
收集很多棋谱,告诉CNN,看到落子在5之五,输出天元的位置为1,其他位置为0
看到5之五和天元都有棋子,输出就是5之五的位置为1,其他位置为0
这个是监督的部分,AlphaGo还有强化学习的部分
什么时候用CNN?为什么可用在围棋上?
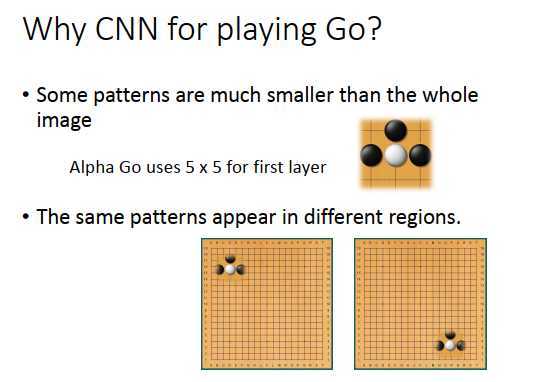
图像要有该有的特性,开头讲过的根据三个特性设计出了CNN的网络结构,在处理图像的时候特别有效。
那为什么这样的结构可以用在围棋上?
因为围棋有一些特性和图像处理是很相似的。
我们说过,在一张图像上面,有一些图案是比整张图像小的,比如鸟嘴。在围棋也有同样的现象,比如看到一些棋子摆放的图案,就要做一些相应的事情(比如上图黑子叫吃的时候,白子要落在下方保证不被吃)。不需要看整个棋盘,只需要看一个小小的范围,就可以侦测白子是不是属于被叫吃的状态。AlphaGo里第一层的过滤器就是用的5 * 5过滤器,显然设计这个过滤器的人觉得围棋上最基本的图案在5 *5 范围内就可以被侦测出来。
图像还有个特性是相同的图案会出现在不同的区域,在围棋上也有同样的特征。例如叫吃的图案,可以出现在棋盘左上角,也可以出现在棋盘右下角,图案代表了同样的意义(叫吃),所以可以用同一个检测器来处理这些在不同位置的图案。
所以围棋是有图像的第一个和第二个特性的。

困惑的是图像的第三个特性,对原图像做子采样不会影响人看到的这张图像的样子,基于第三个特性有了池化层。
对围棋来说,可以做子采样吗?
比如丢弃棋盘的奇数行和偶数列,想想也应该是不可以的。
也许AlphaGo里的CNN架构有特殊的地方。AlphaGo论文附录里描述了它的网络结构,input是一个19 *19 *48的图像,19 *19 是棋盘可以理解,但48是怎么来的?
对AlphaGo来说,把每一个位置都用48个值来描述(卷积后有48个通道)。本来我们只要描述一个位置是不是白子、黑子就可以了,而AlphaGo加上了领域知识(看这个位置是不是出于叫吃的状态等等)。
AlphaGo有做zero padding(零填充),在原来19 *19 的图像外围补上0值变成23 * 23 的图像,第一层用的是5 *5 过滤器,总共k个过滤器(paper里用的是192个过滤器),步长stride=1,有用到ReLu作为激活函数,有2到12层的过滤器层,最后变成21 *21的图像,接下来再使用 3 * 3的过滤器,步长stride=1。最后发现AlphaGo没有使用池化,针对围棋特性设计CNN结构的时候,是不需要池化这个结构的。
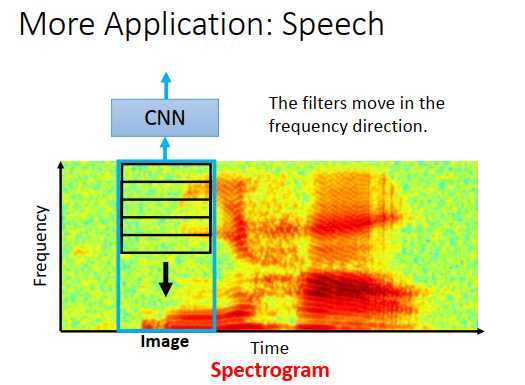
一段声音被表示成频谱图,横轴是时间,纵轴是声音频率。例如上图偏红色的区域,代表那一段时间里,频率的能量比较大。
上图是说你好的频率图,左边红色是你,右边红色是好。人通过训练看频谱图,可以知道是什么音素、声音讯号,判断说的是什么。
既然人可以学习,那也可以让机器学习。把频谱图当做一张图像,input到CNN里,学习音素和声音讯号。神奇的是,把频谱图丢进CNN里的时候,在语音上我们通常只考虑在频率方向移动过滤器,也就是过滤器是长方形的,像上图所示的过滤器移动方向。
为什么不在时间方向移动过滤器呢?
在时间方向移动没有太大的帮助,因为在语音处理里,CNN的输出后面还会接上别的东西,比如LSTM等等(已经考虑到了时间上的信息),所以在CNN里再考虑一次时间上的信息就没有什么特别大的帮助。
为什么频率上的过滤器有帮助?
过滤器的目的是为了检测出现在不同区域的同样的图案,在声音讯号上,虽然男士和女生说同样的话,频谱图看起来不一样,但实际上可能只有一个频率的偏移而已。男士说你好和女生说你好,频谱图的图案是差不多的,有差的可能就是频率(低频和高频),相当于把相同的图案放在频率图的不同位置,所以过滤器在频率方向移动又有效的。
CNN用在一个领域上,永远要想想这个领域的特性是什么,根据特性来设计网络结构。
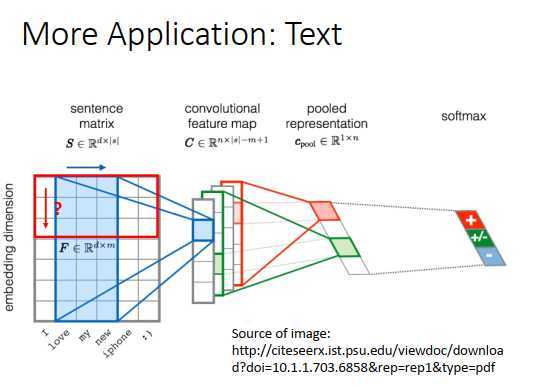
假设input一个句子,要做的是判断这个句子是积极的还是消极的。首先要做的事是把句子里的词语用向量表示,每个向量代表这个词语本身的含义,如果两个词语的含义越接近,对应向量在高维空间上越接近。这个东西叫词嵌入。
当把每个词语用向量表示的时候,把句子里所有的词语再排在一起,就相当于一张图片,那就可以用CNN了。
把CNN用在文字处理上,过滤器如上图所示,高等于图像的高。把过滤器沿着词语的顺序移动,不同的过滤器会得到不同的向量,接下来做池化,把池化的结果放到全连接神经网络里。
在文字处理里,过滤器只在时间的序列上移动。在词向量上,不同维度之间是独立的,在上面做卷积学不到维度与维度之间的关系(同样的图案出现在不同的位置)
原文:https://www.cnblogs.com/wry789/p/13047028.html