1.查询语句写的烂
2.索引失效
单值索引
复合索引
3.关联查询太多 join (设计缺陷或不得已的需求)
4.服务器调优即各个参数的设置(缓冲、线程等)
1.SQL执行顺序
手写
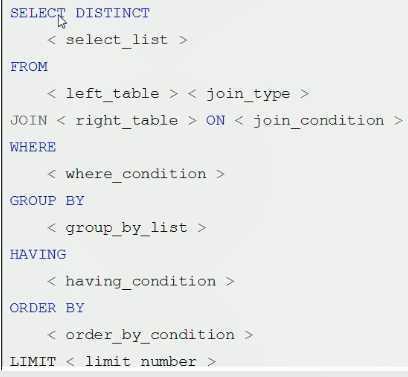
机读

总结
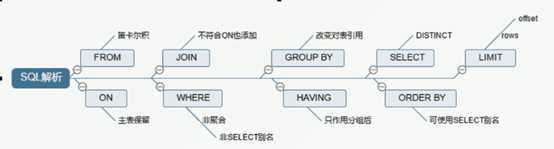
2.join 7种方法
1/inner join select <select_list> from tablea a inner join tableb b on a.key = b.key; 2/left join select <select_list> from tablea a left join tableb b on a.key = b.key; 3/right join select <select_list> from tablea a right join tableb b on a.key = b.key 4/左外join select <select_list> from tablea a left join tableb b on a.key = b.key where b.key is null; 5/右外join select <select_list> from tablea a right join tableb b on a.key = b.key where a.key is null; 6/full outer join select <select_list> from tablea a full outer join tableb b on a.key = b.key 7/满外join select <select_list> from tablea a full outer join tableb b where a.key is null or b.key is null
1.是什么
mysql官方对索引的定义为:索引(index)是帮助mysql高效获取数据的数据结构。 可以得到索引的本质:索引是数据结构。

1、可以理解为 “排好序的快速查找数据结构”
1. 详解(重要)
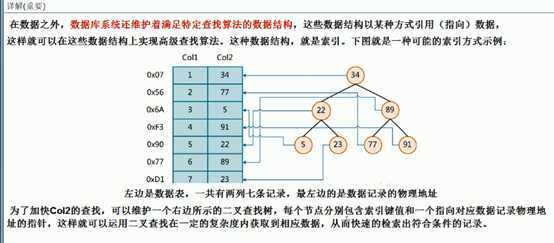
2. 结论
数据本身之外,数据库还维护着一个满足特定查找的数据结构,这些数据结构一某种方式指向数据,这样就可以在这些数据结构的基础上实现高级查找算法, 这种数据结构就是索引。
2、一般来说索引本身也很大,不可能全部存储在内存中,因此索引往往以索引文件的形式存储在磁盘上,
![]()
2.优势
类似图书馆,提高数据检索效率,降低数据库的IO成本,通过索引列对数据进行排序,降低数据排序的成本 和 CPU的消耗
3.劣势

4.mysql 索引分类
1、单值索引
即一个索引只包含单个列,一个表可以有多个单列索引
2、唯一索引
索引列的值必须唯一,但允许有空值 。
3、复合索引
即一个索引包含多个列
4、基本语法
#创建
create [unique]index indexName on mytable(columnname(length)); #unique 表示唯一字段
alter mytable add [unique]index[indexName] on (columnname(length))
#删除
drop index [indexName] on mytable;
#查看
show index from table_name\G
#使用alter 命令
5.mysql索引结构
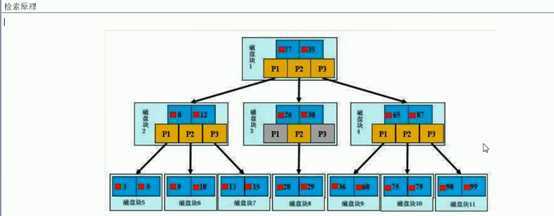
1、BTree索引
检索原理
2、Hash索引
3、full_text 全文索引
4、R_Tree索引
6那些情况需要创建索引

7,那些情况不需要创建索引
1、表太少
2、经常增删改的表:[ 提高了查询速度,同时却会降低更新表的速度,如对表进行INSERT, UPDATE, DELETE。 因为更新表时,mysql不仅要保存数据,还要保存一下索引文件。]
3、数据重复且分布平均的表字段,因此应该只为最经常查询和最经常排序的数据建立索引。【注:如果某个列包含许多重复的内容,为它建立索引就没有太大的实际效果。】


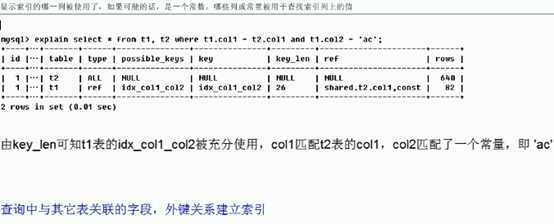


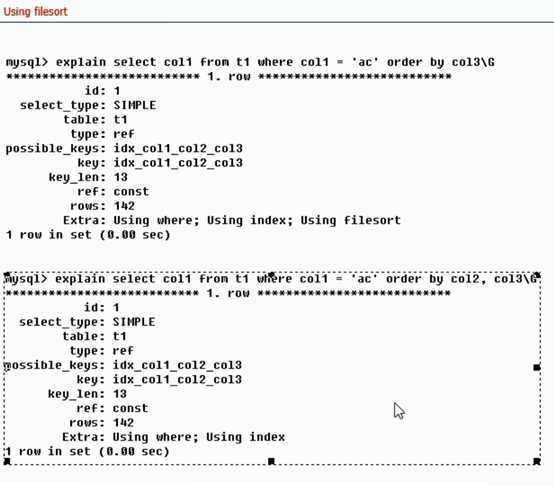

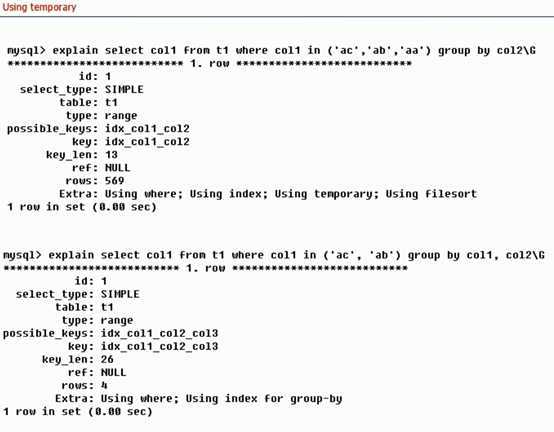





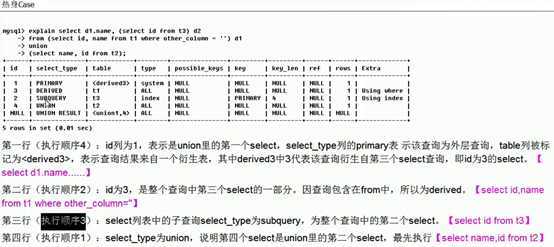

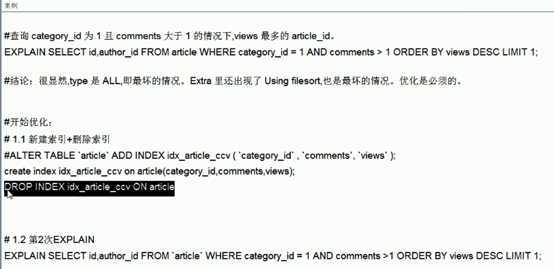




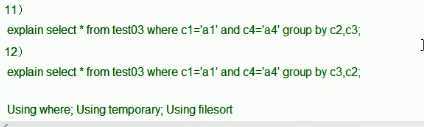
。。。。。
索引优化(左连接索引添加到右表):
索引优化(右连接索引添加到左表)



结论: join语句的优化: 尽可能减少 join 语句中的NestedLoop循环总数;"永远记住小结果集驱动大结果集"。 尽可能优化 NestedLoop 的内层循环; 保证Join语句中被驱动表驱动表上的 join 字段被索引 当无法保证被驱动表的join条件字段被索引且内存资源充足的前提下,不要太吝啬joinBuffer的设置。
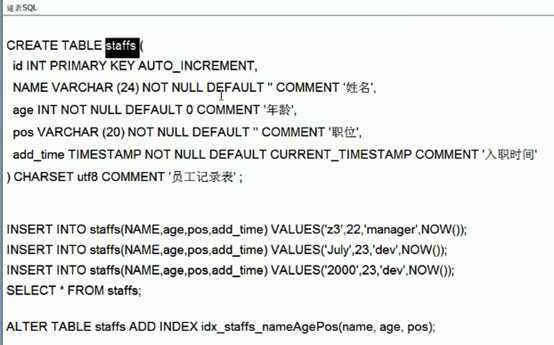

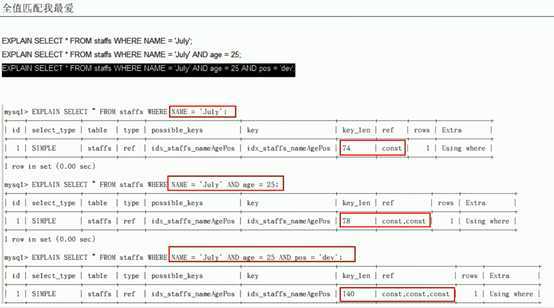
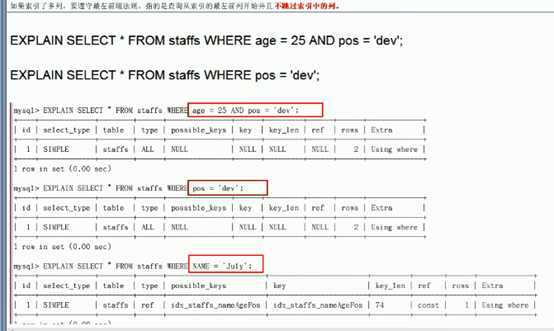
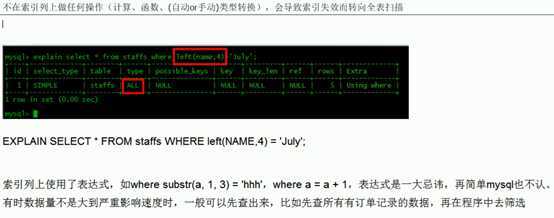
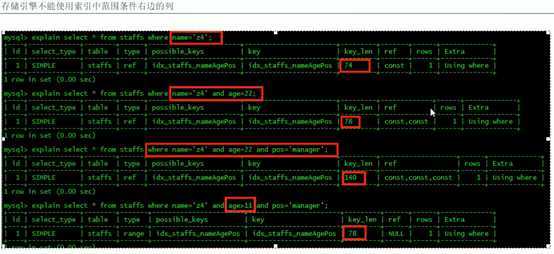
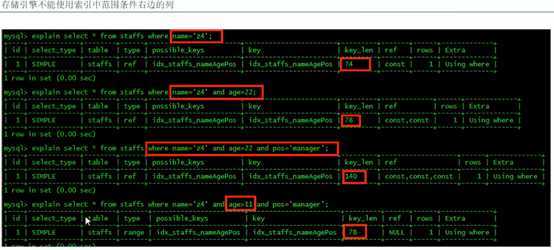
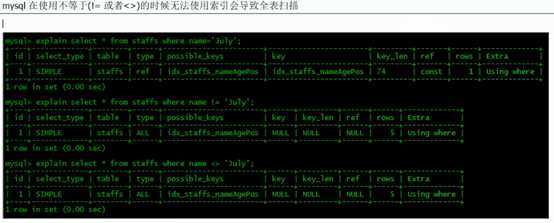


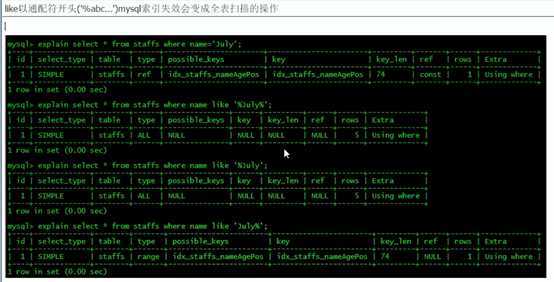
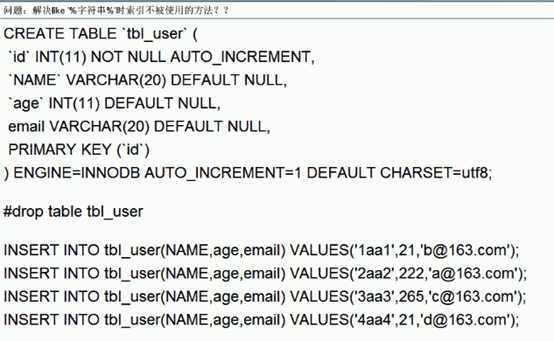


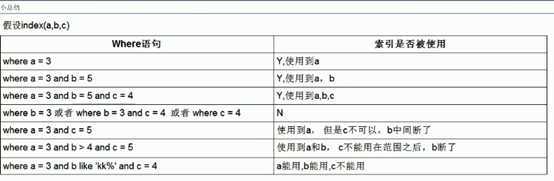
小总结





原文:https://www.cnblogs.com/yh-z/p/13024689.html