一:cuda编程模型
1:主机与设备
主机---CPU 设备/处理器---GPU
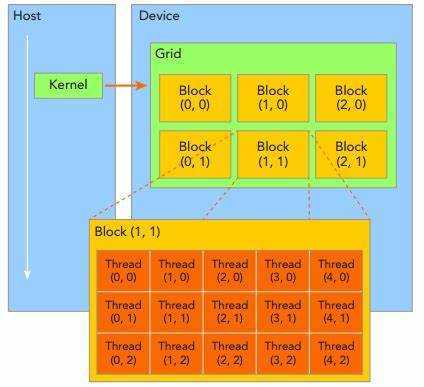
CUDA编程模型如下:
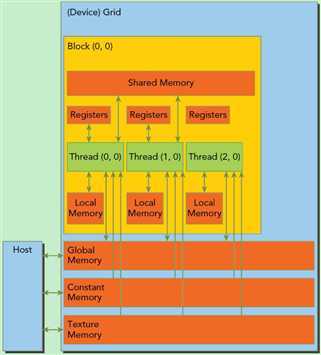
GPU多层存储空间结构如图:
2:Kernel函数的定义与调用
A:运行在GPU上,必须通过__global__函数类型限定符定义且只能在主机端代码中调用;
B:在调用时必须声明内核函数的执行参数----<<<>>>。
C:先为内核函数中用到的变量分配好足够空间再调用kernel函数
D:每个线程都有自己对应的id----由设备端的寄存器提供的内建变量保存,且是只读的。
3:线程结构
1)线程标识
dim3类型(基于uint3定义的矢量类型----由三个unsigned int组成的结构体)的内建变量threadIdx和blockIdx。
2)一维block
线程threadID----threadIdx.x.
3)二维block---(Dx,Dy)
线程threadID----threadIdx.x+threadIdx.y*Dx;
4)三维block---(Dx,Dy,Dz)
线程threadID----threadIdx.x+threadIdx.y*Dx+threadIdx.z*Dx*Dy;
4:硬件映射
1)计算单元
SM---流多处理器 SP---流处理器
A:一个SM包含8个SP,共用一块共享存储器
2)warp
线程束在采用Tesla架构的gpu中:一个线程束由32个线程组成,且其线程只和threadID有关
A:warp才是真正的执行单位
3)执行模型
SIMT---单指令多线程 SIMD---单指令多数据
4)deviceQuery实例

1 #include <stalib.h> 2 #include <stdio.h> 3 #include<string.h> 4 #include <cutil.h> 5 6 int main() 7 { 8 int deviceCount; 9 CUDA_SAFE_CALL(cudaGetDeviceCount(&deviceCount)); 10 if(0 == deviceCount) 11 { 12 printf("no deice\n"); 13 } 14 int dev; 15 for(dev = 0;dev <deviceCount;dev++) 16 { 17 cudaDeviceProp deviceProp; 18 CUDA_SAFE_CALL(cudaGetDeviceProperties(&deviceProp,dev)); 19 print(); 20 } 21 }
5)cuda程序编写流程
A:主机端
1 启动CUDA,使用多卡时需加上设备号,或使用cudaSetDevice()设置 2 为输入数据分配空间 3 初始化输入数据 4 为GPU分配显存,用于存放输入数据 5 将内存中的输入数据拷贝到显存 6 为GPU分配显存,用于存放输出数据 7 调用device端的kernel进行计算,将结果写到显存中对应区域 8 为CPU分配内存,用于存放GPU传回来的输出数据 9 使用CPU对数据进行其他处理 10 释放内存和显存空间 11 退出CUDA
B:设备端
1 从显存读数据到GPU片内 2 对数据进行处理 3 将处理后的数据写回显存
(1)在显存全局内存分配线性空间--cudaMalloc()/cudaFree()
(2)拷贝存储器中的数据 --cudaMemcpy()
拷贝操作类型:cudaMemcpyDeiceToHost cudaMemcpyHostToDevice cudaMemcpyDeviceToDevice
(3)网格定义
<<<Dg,Db,Ns,S>>>
Dg----grid纬度与尺寸 Db---block维度与尺寸 Ns--可分配动态共享内存大小 s--stream_t类型的可选参数
(4)设备端内建变量
gridDim blockIdx blockDim threadIdx warpSize
6)内核实例
A:与shared memory有关
1 __global__ void 2 testKernel(float* g_idata,float* g_odata) 3 {
//分配共享内存 将全局内存的数据写入共享内存 进行计算,将结果写入共享内存 将结果写回全局内存 4 extern __shared__ float sdata[];//动态分配共享内存空间--__device__ __global__函数中
//动态分配大小是执行参数中的第三个参数。当静态分配时必须指明大小 5 6 const unsigned int bid = blockIdx.x; 7 const unsigned int tid_in_block = threadIdx.x; 8 const unsigned int tid_in_grid = blockIdx.x*blockDim.x+threadIdx.x; 9 sdata[tid_in_block] = g_idata[tid_in_grid]; 10 __syncthreads(); 11 12 sdata[tid_in_block] *= (float)bid; 13 14 __syncthreads();
g_odata[tid_in_grid] = sdata[tid_in_block]; 15 }
原文:https://www.cnblogs.com/pengtangtang/p/13052776.html
