1. ZooKeeper 是什么?
直译:从名字上直译就是动物管理员,动物指的是 Hadoop 一类的分布式软件,管理员三个字体现了 ZooKeeper 的特点:维护、协调、管理、监控。
简述:有些软件你想做成集群或者分布式,你可以用 ZooKeeper 帮你来辅助实现。
特点:
最终一致性:客户端看到的数据最终是一致的。可靠性:服务器保存了消息,那么它就一直都存在。实时性:ZooKeeper 不能保证两个客户端同时得到刚更新的数据。独立性(等待无关):不同客户端直接互不影响。原子性:更新要不成功要不失败,没有第三个状态。注意:回答面试题,切忌只是简单一句话回答,可以将你对概念的理解,特点等多个方面描述一下,哪怕你自己认为不完全切中题意的也可以说说,面试官不喜欢会打断你的,你的目的是让面试官认为你是好沟通的。当然了,如果不会可别装作会,说太多不专业的想法。
2. 描述一下 ZAB 协议
ZAB 协议是 ZooKeeper 自己定义的协议,全名 ZooKeeper 原子广播协议。
ZAB 协议有两种模式:Leader 节点崩溃了如何恢复和消息如何广播到所有节点。
整个 ZooKeeper 集群没有 Leader 节点的时候,属于崩溃的情况。比如集群启动刚刚启动,这时节点们互相不认识。比如运作 Leader 节点宕机了,又或者网络问题,其他节点 Ping 不通 Leader 节点了。这时就需要 ZAB 中的节点崩溃协议,所有节点进入选举模式,选举出新的 Leader。整个选举过程就是通过广播来实现的。选举成功后,一切都需要以 Leader 的数据为准,那么就需要进行数据同步了。
3. 四种类型的数据节点 Znode
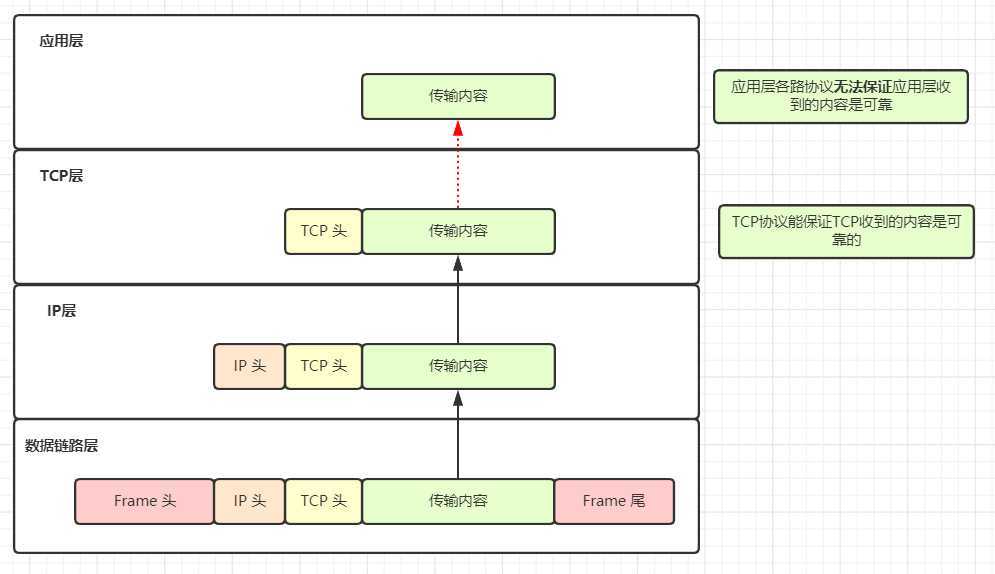
4. TCP 不是可靠连接吗,为什么分布式要考虑网络信息丢失的问题?
TCP 协议只能保证 TCP 层的可靠,所以数据到了应用层就不受控制了,而且我们需要的是应用层的可靠性。
看下图一目了然:
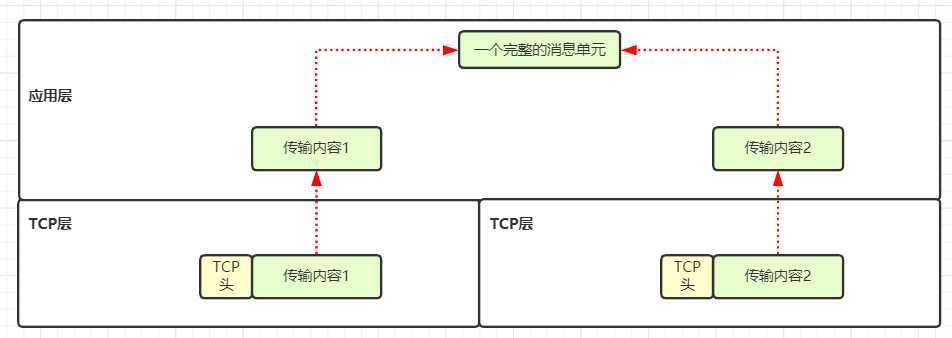
看到上图,这是在一台机器内部,可能传输出问题的概率不高,还有第二个原因:
TCP 协议只能保证同一个 TCP 连接内的消息是有序的。但在分布式系统中,发送数据,可能多个 TCP 连接一起发送一段数据,这个不同 TCP 连接的数据顺序 TCP 协议不会保证的,应用层协议也不保证,只能我们代码实现时控制。
5. 介绍一下两阶段提交协议 2PC
第一阶段:
协调者问所有参与者你那里是否能够提交数据,不管能不能都告诉我结果;参与者收到数据就开始执行,将 Undo 和 Redo 信息写入日志,执行但是没有真正提交,等下一步操作再做最终处理,现在的情况是可进可退。每个参与者都把结果如实告诉协调者。第二阶段:当协调者从所有参与者获得的相应消息都为同意时:
协调者向所有参与者发出开干的命令;参与者完成最终的数据操作;参与者告诉协调者节点一定都搞定了;协调者得到所有参与者节点的好消息,这才算是完成事务。如果执行失败呢,也是一样的回滚流程。
两阶段提交看似不错,但是有个阻塞的问题,这个问题 两阶段无法解决,需要三阶段来解决。
6. 介绍一下三阶段提交协议 3PC
三阶段提交针对两阶段提交有两个改动点:
引入超时。如果等待时间过长那就超过了,不会一直等下去,解决了如果出现阻塞的麻烦。多了一个准备阶段。一些可能出现的地方放到准备阶段了,这也是名字的由来。第一阶段
2PC 的准备阶段很像。协调者向参与者发送处理数据的请求,参与者如果如果做好了就给好消息,搞砸了就给坏消息。
第二阶段
协调者根据参与者的好消息们来判断是否可以继续事务的 预提交操作。
如果都是好消息,那么就会执行事务的预执行。
发送请求:向参与者发送预提交请求。预提交:参与者接收到预提交请求后,会执行事务操作,并将 Undo 和 Redo 信息记录到事务日志中。反馈:如果参与者成功的执行了事务操作,继续返回好消息,然后等待最终指令。万一有谁向协调者报告了坏消息,或者超时了,协调者都没有接到参与者的消息,那么就执行事务的中断。
发送请求:协调者通知所有参与者中断事务。中断事务:参与者收到中断请求之后,中断事务。第三阶段最终的事务提交:
执行提交
协调者发送请求:协调通知所有参与者真正的提交事务请求。参与者事务提交:参与者接收到真正提交事务的请求之后,执行正式的事务提交。参与者反馈:事务提交后,告诉协调者好消息。协调者完成事务:协调者接收到所有参与者的好消息之后,完成事务。中断事务
规定时间内,协调者收到的好消息数量不够,那么就会执行中断事务。
协调者发送中断请求:协调者向所有参与者发送中断事务请求。参与者事务回滚:参与者接收到中断事务请求之后,利用其在阶段二记录的 Undo 信息来执行事务的回滚操作。参与者反馈:事务回滚之后,向协调者发送 回滚完了。协调者中断事务:协调者接收到参与者反馈的回滚完成的消息之后,执行事务的中断。三阶段提交的问题:
网络分区可能会带来问题。但是很少会有人再提四阶段了,事实上大家一般用 TCC 的思想来解决分布式事务的问题。
7. ZooKeeper 宕机如何处理?
ZooKeeper 本身也是集群,推荐配置奇数个服务器。因为宕机就需要选举,选举需要半数 +1 票才能通过,为了避免打成平手。进来不用偶数个服务器。
如果是 Follower 宕机了,没关系不影响任何使用。用户无感知。如果 Leader 宕机,集群就得停止对外服务,开始选举,选举出一个 Leader 节点后,进行数据同步,保证所有节点数据和 Leader 统一,然后开始对外提供服务。
为啥投票需要半数 +1,如果半数就可以的话,网络的问题可能导致集群选举出来两个 Leader,各有一半的小弟支持,这样数据也就乱套了。
8. 描述一下 ZooKeeper 的 session 管理的思想?
分桶策略:
简单地说,就是不同的会话过期可能都有时间间隔,比如 15 秒过期、15.1 秒过期、15.8 秒过期,ZooKeeper 统一让这些 session 16 秒过期。这样非常方便管理,看下面的公式,过期时间总是 ExpirationInterval 的整数倍。
计算公式:
ExpirationTime = currentTime + sessionTimeout
ExpirationTime = (ExpirationTime / ExpirationInrerval + 1) * ExpirationInterval
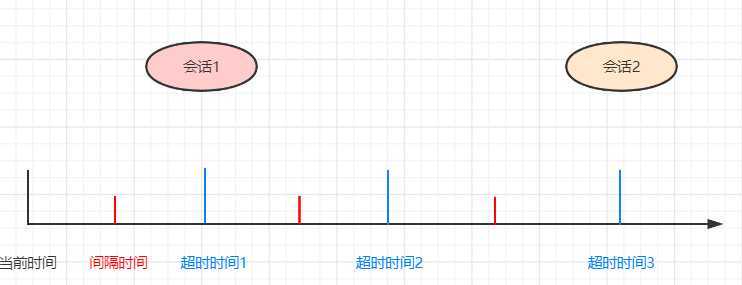
默认配置的 session 超时时间是在 2 * tickTime~20 * tickTime。
9. ZooKeeper Watcher 机制
监听是设计模式的一种思想,监听的节点发生了变化,监听者就会知道。一定按钮事件,异步通知都采用了类似的思想。
ZK 保存的节点,如果发生了变化,怎么通知使用者呢?可以通过 Watcher 机制。
整个使用流程:
客户端要先注册监听,指明要监听的节点。服务端把这些信息保存,操作节点时,检查是否有监听信息,有的话,就通知客户端。
注意,ZK Watcher 有个特点就是一次性的,这样看上去使用很麻烦。但是节省了资源,否则监听太多,或者监听一次就不用了,但是 ZK 还一遍一遍地通知是不合适的。一次性就表示有需要就注册。
10. ZooKeeper Server 的角色
Leader:
整个集群就一个,修改数据的操作只有 Leader 能执行,执行完同步给整个集群。Follower:
处理客户端的读请求,也就是不改变数据的都可以处理,改变数据的转发请求给 Leader 服务器。如果 Leader 宕机了,参与选举,自己可以给自己投票。Observer:
处理客户端的读请求,也就是不改变数据的都可以处理,改变数据的转发请求给 Leader 服务器。这点和 Follower 很像。不能投票,没有选举权和被选举权。11. ZooKeeper Server 的状态
服务器具有四种状态,分别是 LOOKING、FOLLOWING、LEADING、OBSERVING。
LOOKING:集群宕机了,无法对外提供服务了,这时需要选举,所有节点都是这个状态。FOLLOWING:Follower 节点正常情况下就是这个状态。LEADING:Leader 节点正常情况下就是这个状态。OBSERVING:Observer 节点正常情况下是这个状态。对比三种角色,你会发现多了一种状态 Looking,这是在选举时大家的状态,表明需要选举,无法正常工作。
12. ZooKeeper 负载均衡和 Nginx 负载均衡区别
ZooKeeper:
不存在单点问题,zab 机制保证单点故障可重新选举一个 Leader只负责服务的注册与发现,不负责转发,减少一次数据交换(消费方与服务方直接通信)需要自己实现相应的负载均衡算法Nginx:
存在单点问题,单点负载高数据量大,需要通过 KeepAlived 辅助实现高可用每次负载,都充当一次中间人转发角色,本身是个反向代理服务器自带负载均衡算法13. ZooKeeper 的序列化
序列化:
内存数据,保存到硬盘需要序列化。内存数据,通过网络传输到其他节点,需要序列化。ZK 使用的序列化协议是 Jute,Jute 提供了 Record 接口。接口提供了两个方法:
serialize 序列化方法deserialize 反序列化方法要系列化的方法,在这两个方法中存入到流对象中即可。
14. Zxid 是什么,有什么作用
Zxid,也就是事务 id,为了保证事务的顺序一致性,ZooKeeper 采用了递增的事务 Zxid 来标识事务。proposal 都会加上了 Zxid。Zxid 是一个 64 位的数字,它高 32 位是 Epoch 用来标识朝代变化,比如每次选举 Epoch 都会加改变。低 32 位用于递增计数。
Epoch:可以理解为当前集群所处的年代或者周期,每个 Leader 就像皇帝,都有自己的年号,所以每次改朝换代,Leader 变更之后,都会在前一个年代的基础上加 1。这样就算旧的 Leader 崩溃恢复之后,也没有人听它的了,因为 Follower 只听从当前年代的 Leader 的命令。
15. 讲解一下 ZooKeeper 的持久化机制
什么是持久化?
数据,存到磁盘或者文件当中。机器重启后,数据不会丢失。内存 -> 磁盘的映射,和序列化有些像。ZooKeeper 的持久化:
SnapShot 快照,记录内存中的全量数据TxnLog 增量事务日志,记录每一条增删改记录(查不是事务日志,不会引起数据变化)为什么持久化这么麻烦,一个不可用吗?
快照的缺点,文件太大,而且快照文件不会是最新的数据。 增量事务日志的缺点,运行时间长了,日志太多了,加载太慢。二者结合最好。
快照模式:
将 ZooKeeper 内存中以 DataTree 数据结构存储的数据定期存储到磁盘中。由于快照文件是定期对数据的全量备份,所以快照文件中数据通常不是最新的。
16. 投票信息的五元组
Leader:被选举的 Leader 的 SIDZxid:被选举的 Leader 的事务 IDSid:当前服务器的 SIDelectionEpoch:当前投票的轮次peerEpoch:当前服务器的 EpochEpoch > Zxid > Sid
Epoch,Zxid 都可能一致,但是 Sid 一定不一样,这样两张选票一定会 PK 出结果。
17. Quorum 与脑裂
当某选票,占参与选举的数量的一半以上,选举结果
脑裂:大脑裂开了,成了两个大脑。这时数据不一致,客户端访问的结果就很佛系了。
半数以上的选票就是解决之道,只有拿到大于半数的选票才能成为大脑。
18. 选举的全过程
两种情况会出现选举:
1. 服务器们启动的时候2. 服务器运行过程中,Leader 失联了服务器们启动的选举,三台服务器 server1、server2、server3:
1. server1 启动,一台机器不会选举。
2. server2 启动,server1 和 server2 的状态改为 looking,广播投票
3. server3 启动,状态改为 looking,加入广播投票。
4. 初识状态,互不认识,大家都认为自己是王者,投票也投自己为 Leader。
5. 投票信息说明,票信息本来为五元组,这里为了逻辑清晰,简化下表达。
初识 zxid = 0,sid 是每个节点的名字,这个 sid 在 zoo.cfg 中配置,不会重复。

6. 初始 zxid=0,server1 投票(1,0),server2 投票(2,0),server3 投票(3,0)
7. server1 收到 投票(2,0)时,会先验证投票的合法性,然后自己的票进行 pk,pk 的逻辑是先比较 zxid,server1(zxid)=server2(zxid)=0,zxid 相等再比较 sid,server1(sid)< server2(sid),pk 结果为 server2 的投票获胜。server1 更新自己的投票为 (2,0),server1 重新投票。
8. TODO 这里最终是 2 还是 3,需要做实验确定。
9. server2 收到 server1 投票,会先验证投票的合法性,然后 pk,自己的票获胜,server 不用更新自己的票,pk 后,重新在发送一次投票。
10. 统计投票,pk 后会统计投票,如果半数以上的节点投出相同的票,确定选出了 Leader。
11. 选举结束,被选中节点的状态由 LOOKING 变成 LEADING,其他参加选举的节点由 LOOKING 变成 FOLLOWING。如果有 Observer 节点,如果 Observer 不参与选举,所以选举前后它的状态一直是 OBSERVING,没有变化。
简单地说:
开始投票 -> 节点状态变成 LOOKING -> 每个节点选自己-> 收到票进行 PK -> sid 大的获胜 -> 更新选票 -> 再次投票 -> 统计选票,选票过半数选举结果 -> 节点状态更新为自己的角色状态。
19. 数据同步全过程
数据同步,麻烦的地方在于有不同的情况。选举结束后的首要工作就是数据同步。Learner 服务器会发送给 Leader 服务器一个数据包,其中的 lastZxid 会表明自己的数据新旧程度。
这里需要三个变量,辅助判断:
peerLastZxid:Follower 最后处理的 ZxidminCommittedLog:Leader 缓存队列中的最小 ZxidmaxCommittedLog:Leader 缓存队列中的最大 Zxid1. DIFF 同步
peerLastZxid > minCommittedLog && peerLastZxid < maxCommittedLog
这种情况,就是 Follower 少了一部分数据,直接同步 Leader 即可。
2. TRUNC 同步
peerLastZxid > maxCommittedLog
Follower 的数据比 Leader 多,但是一切要以 Leader 为准,这就需要回滚。多余的数据删除掉。
3. 全量同步(SNAP 同步)
peerLastZxid < minCommittedLog
这时 Follower 已经无法依赖队列的数据进行同步,因为它缺少的不仅仅是增量的数据,这时只能全量同步了。
20. 分布式锁
本地锁,可以用 JDK 实现,但是分布式锁就必须要用到分布式的组件。比如 ZooKeeper、Redis。网上代码一大段,面试一般也不要写,我这说一些关键点。
几个需要注意的地方如下。
死锁问题:锁不能因为意外就变成死锁,所以要用 ZK 的临时节点,客户端连接失效了,锁就自动释放了。锁等待问题:锁有排队的需求,所以要 ZK 的顺序节点。锁管理问题:一个使用使用释放了锁,需要通知其他使用者,所以需要用到监听。监听的羊群效应:比如有 1000 个锁竞争者,锁释放了,1000 个竞争者就得到了通知,然后判断,最终序号最小的那个拿到了锁。其它 999 个竞争者重新注册监听。这就是羊群效应,出点事,就会惊动整个羊群。应该每个竞争者只监听自己前面的那个节点。比如 2 号释放了锁,那么只有 3 号得到了通知。追问 1:watch 监听为什么是一次性的?
如果服务端变动频繁,而监听的客户端很多情况下,每次变动都要通知到所有的客户端,给网络和服务器造成很大压力。
一般是客户端执行 getData(节点 A,true),如果节点 A 发生了变更或删除,客户端会得到它的 watch 事件,但是在之后节点 A 又发生了变更,而客户端又没有设置 watch 事件,就不再给客户端发送。
在实际应用中,很多情况下,我们的客户端不需要知道服务端的每一次变动,我只要最新的数据即可。
追问 2:ZooKeeper 为什么不用数据库做持久化?
基础组件,就是基础,不能依赖太多。
追问 3:ZooKeeper 的 session 为什么由 server 维护,client 不行吗?
如果 session 由 client 管理,那么集群宕机了,然后恢复了,session 并不知道 client 失效了,临时节点也不会被清理,对 server 来说它依然是临时节点。
1. String 的内部结构及实现原理
Redis 是 C 语言实现的,但是 C 语言中的字符串无法满足 Redis 复杂需求,Redis 自己定义了一种名为 简单动态字符串 simple dynamic string,SDS 的结构体。
内部结构最好扫一眼源码看看,打开 sds.h:
typedef char *sds;
/* Note: sdshdr5 is never used, we just access the flags byte directly.
* However is here to document the layout of type 5 SDS strings. */
struct __attribute__ ((__packed__)) sdshdr5 {
unsigned char flags; /* 3 lsb of type, and 5 msb of string length */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* used */
uint8_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 {
uint32_t len; /* used */
uint32_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr64 {
uint64_t len; /* used */
uint64_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
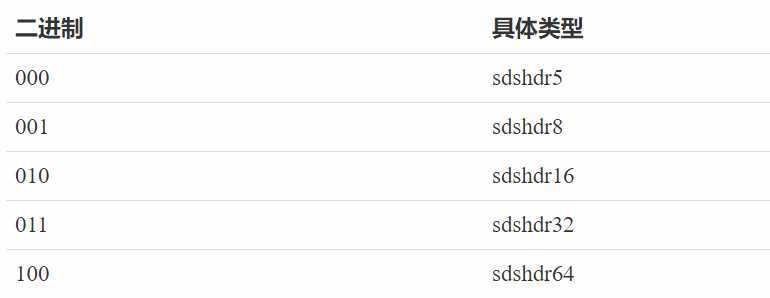
可以看到定义了五种不同的结构体 sdshdr5、sdshdr8、sdshdr16、sdshdr32、sdshdr64。
以 sdshdr8 为例来讲解下:
sds 是 simple dynamic string 的缩写hdr 是 header 的缩写。8 表示给字符串分配的长度是 2^8 - 1 =255。根据字符串的不同长度选择不同的 sdshdr。注意 sdshdr5 在实际中未使用。sdshdr8 内部的变量又都是什么含义呢,加上中文注释?
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* 实际字符串占用长度 */
uint8_t alloc; /* 分配的空间长度 */
unsigned char flags; /* 区分是 sdshdr8 还是 sdshdr16 ...... */
char buf[];/* 存放的位置 */
};
以字符串 HelloWorld 为例,长度 < 255,选择了 sdshdr8:
len = 10alloc = 255flags = 1buf[] 指向具体位置flag = 1 是一件很迷惑人的事,原理是什么?
一共有 5 种结构体,取的二进制来区分不同类型:
代码内部根据不同情况使用不同的 sdshdr,于是下面的 case-when 随处可见:
switch(type&SDS_TYPE_MASK) {
case SDS_TYPE_5:
return sizeof(struct sdshdr5);
case SDS_TYPE_8:
return sizeof(struct sdshdr8);
case SDS_TYPE_16:
return sizeof(struct sdshdr16);
case SDS_TYPE_32:
return sizeof(struct sdshdr32);
case SDS_TYPE_64:
return sizeof(struct sdshdr64);
Redis 作为一个缓存中间件,最重要的就是读取数据的速度。更简单的说法就是尽量不要每次修改字符串,就重新申请释放内存空间,这点 C 语言原生的字符串做不到,sds 可以做到。
buf 的内存分配策略如下:
当 SDS 的 len 属性长度小于 1 MB 时,Redis 会分配 2*len 的空间。短期你再使用时,如果不超过 len,不必申请内存。当 SDS 的 len 属性长度大于 1 MB 时,Redis 会分配 len+1 MB 的空间。这时候翻倍的代价太大,就预留 1 MB。内存回收策略如下:
Redis 的内存回收采用惰性回收,空闲先不释放,免得你一会用时还得分配,折腾内存,折腾内存就是折腾自己。#define SDS_MAX_PREALLOC (1024*1024)
sds sdsMakeRoomFor(sds s, size_t addlen) {
......
if (newlen < SDS_MAX_PREALLOC)
newlen *= 2;
else
newlen += SDS_MAX_PREALLOC;
......
}
2. List 的内部结构及实现原理
List 老版本是 ZipList 和 LinkedList 切换,二者总是取其一,后来两者相结合的实现方式。
打开源码文件 quicklist.h,quicklist 有 head 和 tail 首尾指针,是一个双向链表,也就是 LinkedList,内部节点是 quicklistNode。
typedef struct quicklist {
quicklistNode *head;
quicklistNode *tail;
unsigned long count; /* total count of all entries in all ziplists */
unsigned long len; /* number of quicklistNodes */
int fill : 16; /* fill factor for individual nodes */
unsigned int compress : 16; /* depth of end nodes not to compress;0=off */
} quicklist;
quicklistNode 除了前后指针,还有一些压缩信息,也就是 ZipList。
typedef struct quicklistNode {
struct quicklistNode *prev;
struct quicklistNode *next;
unsigned char *zl;
unsigned int sz; /* ziplist size in bytes */
unsigned int count : 16; /* count of items in ziplist */
unsigned int encoding : 2; /* RAW==1 or LZF==2 */
unsigned int container : 2; /* NONE==1 or ZIPLIST==2 */
unsigned int recompress : 1; /* was this node previous compressed? */
unsigned int attempted_compress : 1; /* node can‘t compress; too small */
unsigned int extra : 10; /* more bits to steal for future usage */
} quicklistNode;
疑问:为什么 quicklistNode 也有 count 属性?
答:因为一个 quicklistNode 会包含多个元素。
疑问:为什么要用双向链表?
答:因为提供了 LPOP、RPOP 这类左侧入队出队,右侧入队出队这样的操作。
疑问:为什么要用压缩链表?
答:ZipList 使用的连续内存,存储效率高,这样又不利于修改,所以和双向链表结合最好。而且压缩链表不益太长,所以,最合理的方案,就是每个节点用压缩链表,整体用双向链表。
3. Map 的内部结构及实现原理
Redis 的 map 使用了两种实现方式,数据量很小使用前面写过的 ZipList,数据量大使用 HashTable,读到这有没有一种感觉,Redis 底层总是采用多个数据结构来切换、结合使用,没有最好的数据结构,只有最适合它的场景。
熟悉 Java 的人一定会记得 HashMap 是标准的散列表 = 数组 + 链表,key 通过 hash 取模定位到数组的索引上,如果冲突加入链表,当然后续优化还有红黑树,Redis 没用树,我们这里也不提它。
打开源码文件 dict.h,dictht 就是 HashMap 的数组。
typedef struct dictht {
dictEntry **table;
unsigned long size;
unsigned long sizemask;
unsigned long used;
} dictht;
dictEntry 是每个节点,它包含 key 和 val,同时 next 指针表明它就是那个链表。
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next;
} dictEntry;
前面两个结构已经可以实现 HashMap 了,但是 Hash 还有一些复杂的操作,比如扩容、缩容,这些操作由 dict 辅助完成。
typedef struct dict {
dictType *type;
void *privdata;
dictht ht[2];
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
unsigned long iterators; /* number of iterators currently running */
} dict;
4. Set 的内部结构及实现原理
打开源码文件 inset.h:
typedef struct intset {
uint32_t encoding;
uint32_t length;
int8_t contents[];
} intset;
编码、长度、数组,intset 可以说就是一个简单的整形数组。
我不说,你也会猜到,底层依然是两种数据结构,如果都是整数就用 inset,如果还有其他类型就用 hashtable。
特殊:inset 是排序的,从小到大排列。
数组最重要的就是扩容。
5. SortedSet 的内部结构及实现原理
排序:
前面 inset 是根据大小排序的,条件是元素都是整数,那 SortedSet 可以存储所有元素,如何比较大小呢? 答案是分数,用户存入元素时,需要指定分数,也就是说用户告诉 SortedSet 怎么排序。
底层实现:
依然是多种数据结构,ziplist 或者 skiplist + hashtable,这里主要讲讲跳跃表 skiplist。
跳跃表:
顾名思义,可以跳着遍历链表。我们知道链表的缺点是遍历时只能一个一各遍历,哪怕是排序的,也没法像数组那样使用索引访问,毕竟链表的空间不是连续的。
跳跃表很抽象,需要看图帮助大家理解一下:

说白了,一些节点不只一个 next 指针,链表内部一些不挨着的节点可以通过指针连接在一起。最层面即 level = 1 的链表节点是最全面的。
打开源码文件 server.h,可以看到三个定义。
dict 这个字典是辅助 API 功能的,zscore 通过元素得到对应的分数。zskiplist 就是跳跃表的实现。typedef struct zset {
dict *dict;
zskiplist *zsl;
} zset;
跳跃表定义了首尾节点、链表长度、层数。这里的层数表示跳跃表的最大层数,层数的概念需要解释下:
level = 1 的节点level = 2 的节点level = 3 的节点typedef struct zskiplist {
struct zskiplistNode *header, *tail;
unsigned long length;
int level;
} zskiplist;
跳跃表的节点,这个节点可以有多个 level,所以这里用数组定义 level。
typedef struct zskiplistNode {
sds ele;
double score;
struct zskiplistNode *backward;
struct zskiplistLevel {
struct zskiplistNode *forward;
unsigned long span;
} level[];
} zskiplistNode;
那么一个节点,到底需要多少个 level 呢?数据分布并不均匀,跳跃表采用随机算法定义一个节点的 level。
/* Returns a random level for the new skiplist node we are going to create.
* The return value of this function is between 1 and ZSKIPLIST_MAXLEVEL
* (both inclusive), with a powerlaw-alike distribution where higher
* levels are less likely to be returned. */
int zslRandomLevel(void) {
int level = 1;
while ((random()&0xFFFF) < (ZSKIPLIST_P * 0xFFFF))
level += 1;
return (level<ZSKIPLIST_MAXLEVEL) ? level : ZSKIPLIST_MAXLEVEL;
}
6. Redis 有 timeout 机制,请问到了过期时间,数据是否真的被删除了?
答案是:不一定。
Redis 针对删除有两种机制:
消极方法(passive way):在主键被访问时如果发现它已经失效,那么就删除它。积极方法(active way):周期性地从设置了失效时间的主键中选择一部分失效的主键删除对于那些从未被查询的 key,即便它们已经过期,被动方式也无法清除。因此 Redis 会周期性地随机测试一些 key,已过期的 key 将会被删掉。Redis 每秒会进行 10 次操作,具体的流程:
随机测试 20 个带有 timeout 信息的 key删除其中已经过期的 key也就是说了,无论是消极方法还是消极方法,到了过期时间,数据依然可能还在。只是逻辑上访问不到,对用户来说和删除了一样。
7. Redis 的持久化机制
两种方式:
RDB:全量备份。当符合条件时,Redis fork 一个子线程,数据写入临时文件,生成 dump.rdb。不会对主进程操作影响。AOF:增量事务日志,记录每次的操作。RDB 文件大,备份频率不可能太高,AOF 文件小,但是小文件太多,数据恢复会非常慢。
所以,需要二者结合,定期 RDB,然后两次的 RDB 之间使用 AOF。
8. Redis 是单进程单线程?性能为什么这么快
单线程和多线程:
多线程解决的什么问题,对多核 CPU 的利用,但是 Redis 官方提到,Redis 的瓶颈不是 CPU,而是内存和网络。这样使用单线程,并不影响速度,反而因为没有多线程的上下文频繁的切换,提高了性能。
内存:
Redis 把数据都加载到内存中,后续操作都在内存中,也是速度快的一个原因。
IO 多路复用:
IO 多路复用也叫异步阻塞 IO。多路是指多个网络连接,复用是指复用一个线程,大家经常搞混同步非阻塞和异步阻塞,这里画图区分下。
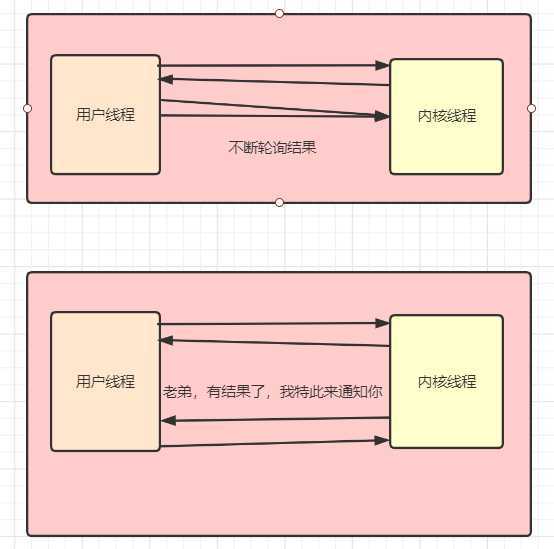
区别:
同步非阻塞:直接返回,不断主动轮询。异步阻塞:我不去轮询,太费 CPU,有结果你通知我下。注意,异步不等于多线程,多线程是一种异步实现,监听也是一种异步实现。
9. Redis 的集群
解决单点的故障方案:
主从复制 master-slave,之前的 MongDB 和 MySQL 都是这种方式。那么是不是存储,都是这种方式更好。
集群就要面对一致性的问题,还有选举。(主从可以实现读写分离)
选举:
有了主从,就得有选举,如果主宕机了,那么从就应该通过选举上台继续做主的工作。还记得 ZooKeeper 通过 ZAB 协议自己选举。
选举的方式:
内部选举 ZooKeeper外部选举 RedisRedis 自己没有选举的能力,只能依靠外部的哨兵节点帮助自己选举。
10. Redis 的哨兵
哨兵有两个作用:
监控 master 和 slave 是否正常运行。当 master 出现故障时,从 slave 中选举一个新的 master。问题:如果哨兵节点挂了怎么办?
答:哨兵也得用集群,哨兵之间相互感知,pub/sub 所有哨兵都会订阅,sub(channel:sentinel:hello)。
新哨兵加入,会发布消息给 master,master 收到消息,订阅消息的其他哨兵都会收到信息,这样新哨兵就和其他哨兵建立了连接。
问题:多个哨兵节点,具体哪个哨兵去协助选举呢?
答:哨兵也有 Leader,通过分布式一致性算法 Raft 选举的。
11. Redis-Cluster,希望相应的数据都落在同一台机器上,怎么做?
Cluster 是做数据分片的,因为 Redis 的数据都存放在内存中,那么数据量终究会受到单机内存的限制,分片可以均匀的将数据打到不同的节点上。但是问题来了,希望某类数据在同一个节点,该怎么?
Redis 的架构师很聪明,在设计时就想到了这种场景。
HashTag
举个例子,假设存了用户的一些信息 name、phone,那么 key 可能是这样的:
user:userId:name
user:userId:phone
我们当然希望,同一个用户的信息,落在同一个节点,换句话说能否以 userId 作为分片的依据呢,可以,只需要一个 {}。
user:{userId}:name
Redis 做 hash 时,发现 key 有大括号 {},就会提取内容 userId,并且只对 userId 做 hash 去分片。
12. Redis 缓存与数据一致性的问题
强一致性:
首先,Redis 的数据和数据库的数据,毕竟是两个不同服务,还隔着网络,是百分百不能做到事务级别的强一致性了。
最终一致性:
我们能做到的就是让 Redis 的数据最终和数据库保持一致,最终就意味着有一小段时间,数据不一致,那该如何权衡下面两个问题:
1. 更新缓存,还是让缓存失效?
如果更新过程很复杂,有很多前置操作,比如查询多个接口,那么就应该让缓存失效如果更新缓存代价小,就更新缓存2. 先操作数据库还是先操作缓存?
先操作哪个都是不一致的,看哪个对业务最合适,就选择哪个13. 缓存雪崩
同一时刻,缓存大面积失效,大量请求同时到了数据库,缓存雪崩最受伤的是数据库。
如何避免雪崩:
从缓存中取不到值,加锁访问数据库,放入缓存,必须要排队,保证只有一个线程访问到数据库。过期时间,加入随机值,不让数据同时大量过期。缓存如果挂了,不要直接就进入数据,建立多级缓存。比如 Redis 缓存失效,下一步就去读 Memcached,而不是 MySQL。14. 缓存击穿
请求的 key 不存在,就去在 Redis 查一次,MySQL 查一次。如果有大量这样的请求进来,Redis 不会有事,但是 MySQL 很快就会挂掉。
如何避免击穿:
key 不存在,就给一个默认值,去 Redis 缓存。利用布隆过滤器,所有存在的数据哈希到一个足够大的过滤器中,不存在的数据请求会被拦掉。15. Redis 的内存回收策略
Java 内存不足时,JVM 会把没有用的对象都从内存中淘汰掉。Redis 也是一样,内存中数据越来越多,超过了限制怎么办?容量不足,也就有了淘汰策略。
最大内存策略:
noeviction:没有策略,默认值。volatile-random:从已设置过期时间的数据集中任意选择数据淘汰。volatile-lru:从已设置过期时间的数据集中挑选最近最少使用的数据淘汰。volatile-ttl:从已设置过期时间的数据集中挑选将要过期的数据淘汰疑问:如何保证 Redis 存的都是热点数据?
答:选择 volatile-lru,把用得少都淘汰了,留下的都是热点。
采样:
为了保证性能,Redis 没有采用全轮询的方式,而是用的采样的方式,每次删除部分数据。
16. 管道和 Lua 脚本
批量连接:
每一次网络连接,都是一笔开销,批量的请求怎么办,管道技术可以一次连接处理多次命令。但是 Redis 的管道和 Linux 的管道不一样,后边命令拿到前边命令的处理结果。
Lua 脚本:
有多个命令,如果希望后边命令拿到前边命令的处理结果,可以通过 Lua 脚本实现。比如事务性的请求。
Lua 脚本如何保证原子性?
如果 Lua 脚本操作 key = user:1 时,其他客户端再操作这个 key 时,会被 Redis 阻塞,知道 Lua 脚本执行完毕。
17. 一致性哈希算法
数据存储,必然会有分片,因为一个节点容量是有上限的。有了分片,必然又会有数据分片均衡的话,否则新增或者减少节点,会影响大量的请求。
正常的操作就是取模,有 3 个节点,就模 3,结果无非就是 0,1,2。如果现在增了一个节点 4,那么他也只能分担 一个节点的压力,这个是不能接受的。放开思路:
假设节点 4 很有的基地,分散在世界各地,那么它能分担的数据,就会影响所有的节点。
一致性哈希,对 2^32 取模,得到的结果是远远大于 3 的数字,没关系,映射过去。这样每个节点都会环上大量的不同的位置。带来的结果,就是新增节点,减少节点。数据都会比较均衡。
1. 消息队列的作用与使用场景
六字大法总结:异步削峰解耦。
异步:批量数据异步处理,比如批量上传照片。削峰:高负载任务负载均衡,比如电商秒杀抢购。解耦:串行任务并行化,比如下订单的整个流程。2. 怎么自动删除没人消费的消息?
设置 TTL,TTL 也就是存活时间 Time To Live。
两种设置方式:
批量方式,设置一个队列的消息的 TTL单个方式:设置一个指定消息的 TTL3. 无法被路由的消息,去了哪里?
无法被路由的消息去了死信队列 Dead Letter Queue。
4. 消息在什么时候会变成 Dead Letter
三种消息会变成 Dead Letter:
消息设置了 TTL,并且已经过期了。拒绝的消息或者不应答消息,并且设置了不重新入队。队列达到最大长度,超过限制了,先入队的陈旧消息会变成死信。5. RabbitMQ 如何实现延时队列?
问这个问题,是因为 RabbitMQ 没有直接提供这个功能。
我们还可以通过 设置超时时间的方式 + 一个死信队列 + 转发队列的方式来实现:
ttl 超时时间可以设置在消息上,也可以设置在队列上。死信队列是一个普通的队列,它没有消费者,用来存储有超时时间信息的消息。转发队列,用来接收死信队列超时消息,在接收到之后,消费者将消息解析。总之:消息设置超时时间,然后进入死信队列,超时过后,信息转发到转发队列。消费者监听转发队列实现消费。
6. 如何保证消息的可靠性投递?
这是一个很复杂的答案,不是因为事先逻辑多复杂,而是因为,消息的投递途径多个环节,每个环节都可能出问题。
生产者到路由这段路需要保证安全消息从路由到队列这段路需要保证安全队列是个存储的数据结构,需要保证数据不能丢失队列到消费者这段路需要保证安全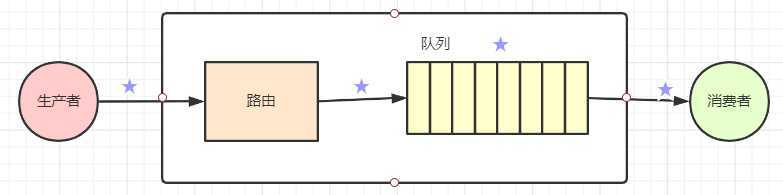
1. 生产者到路由这段的安全
方式 1:需要将 Channel 设置成事务模式。缺点:开始事务,性能差。
方式 2:不使用事务,通过监听方式获得结果。效率高,推荐使用。
2. 路由到队列这段的安全
这种情况,生产环境很多遇到,有备无患,打印日志便于突发异常。
3. 队列数据的安全
deliveryMode = 2 代表持久化。
4. 队列到消费者这段的安全
通过消费者应答来实现:
7. 消息幂等性
消息幂等性是指,由于生产者代码问题或者网络问题或者其他什么原因,导致消费者多次接收到了同一个消息,那么消费者要保证对消息的处理结果要和只收到一次的处理结果一致。
说白了,用户下了一单,消费者哪怕收到多次,也只能下一单。给用户扣款,消费者哪怕收到多次,也只能扣一次款。
重复消息的问题,从源头上是不可避免,只能从幂等性考虑。
方案:消息加上唯一业务 ID,处理完保存起来。再次遇到重复 ID 的消息,舍弃不处理。
8. 如何在服务端/消费端做限流?
为什么消费端做限流?
假如队列里堆积了 几十万条消息,一个消费者连进来,可以瞬间就被大量消息打垮,而且每个消息的处理并不一定非常快。
RabbitMQ 提供了一种 BasicQos API。规则就是还有消息没有处理完,就不接收新信息。
怎么算没有处理完?
消费者没有确认就是,因此自动确认的属性需要关闭。
9. 如何保证消息的顺序性?
很多业务是有先后顺序,比如开通用户、绑定银行卡、激活会员功能。问题出在这三个消息,可能分到不同消息队列,由不同的消费者处理,根本无法保证顺序。
可按照如何方案保证顺序性:
需要设计路由规则,同一个业务的消息需要进入同一个队列一个队列只对应一个消费者10. RabbitMQ 的集群模式和集群节点类型?
集群主要用于实现高可用与负载均衡。RabbitMQ 通过 /var/lib/rabbitmq/.erlang.cookie 来验证身份,需要在所有节点上保持一致。
集群有两种节点类型,一种是磁盘节点,一种是内存节点。集群中至少需要一个磁盘节点以实现元数据的持久化,未指定类型的情况下,默认为磁盘节点。集群通过 25672 端口通信,需要开放防火墙的端口。
RabbitMQ 集群无法搭建在广域网上,除非使用 federation 插件。
1. Kafka ISR 的设计思想
ISR In Sync Replicas,副本同步是解决备份数据的安全同时不太影响性能的一种折中方案。
Kafka 的分区思想解决了并发负载的问题,但是单点故障怎么办,分区都是单点的,分区挂了,数据就挂了。
副本:
每个分区都设置多个副本,分区和它的副本组成一个集合,叫做副本集,这就是 ISR。
副本集中会存在一个 leader 的副本,所有的读写请求都是由 leader 处理。剩余的其他副本就是从 leader 副本同步消息日志。这里的思想就像 MySQL 的副本而不是 ZooKeeper 的副本。
选举:
副本为了安全,分布在不同的 Broker 节点上,如果一台 Broker 节点挂了,不影响一个副本。
如果是 Leader 挂了,这时候就需要从 Follower 中重新选举出来一个做 Leader。
ISR 维护
ISR 一直由 Leader 来维护,如果 Follower 复制的速度慢,Leader 就会将 这个 Follower 从 ISR 中剔除。这样 ISR 中的副本总是保证了一定的相似性,就是 Follower 的数据几乎和 Leader 一致,差一点可都被开除了。
2. Kafka 的速度为什么那么快?
数据写入用的顺序写入数据读取用的零拷贝批量压缩大文件拆分索引文件3. Kafka 如何保证消息的顺序消费?
Kafka 分布式的单位是分区,同一个分区用一个 write ahead log 组织,所以可以保证先进先出的顺序。分区和分区之间没有顺序。如果需要实现顺序问题,将数据发往同一个分区,同一个 key 的 message 只发送到同一个 partition。
发送消息的时候,可以指定 partition 参数。如果你指定了 partition,那么数据就会发给这个分区。
消费端,一个 partition 只能被一个消费者消费。
4. 活锁的问题怎么解决?
为什么会出现活锁,就因为消费者不但的发送心跳信息,但是没有处理任何消息。但是这样它就会一直占用分区,Kafka 提供了参数 max.poll.interval.ms 活跃检测机制。调用的 poll 的频率超过了设定的间隔时间,客户端将离开组,其他消费者也就可以接管该分区。
消费者可以控制 poll 循环:
max.poll.interval.ms:增大间隔,但是值大了将会延迟组重新平衡。max.poll.records:每次的最大返回数量。如果不知道消息处理时间怎么办?
将消息处理派发给其他线程处理,让消费者继续调用 poll。
5. Kafka 高效文件存储设计特点
大文件分成多个小文件段,这个思想和 Lucene 的索引段思想很相似,通过多个小文件段,就容易定期清除或删除已经消费完文件,减少磁盘占用。Index 信息可以检索到消息。Index 元数据都预加载到内存中,减少了频繁的 IO 磁盘操作。Index 通过稀疏存储的方式来减少磁盘空间占用。6. 谈一谈 Kafka 的再均衡
Rebalance 再均衡
消费者数量变化了,就不平衡了,会触发再均衡,这是组内的再分配,之前 A 的分区可能就分配给了 B。
过程如下:
第一步:所有消费者都申请入组。协调者会从其中选一个当 Leader 的角色,并把所有消费者信息发给 Leader。第二步:Leader 开始分配消费方案,分配 consumer 和 partition 的对应关系。分配方案同步给协调者。协调者再告诉每个消费者。7. Kafka 的副本复制过程详解
1.通过 ZK 找到该分区的 Leader。2.将消息发送到该分区的 Leader。3.Leader 将该消息写入本地日志。4.每个副本都从 Leader 拉取数据。5.副本在收到该消息并写入自己的本地日志后,通知 Leader 写入成功。6.当 Leader 收到了 ISR 中的所有副本的成功消息,该消息才是真正提交成功了。7.Leader 将增加 High Watermark 并且向生产者发送提交成功的通知。8. Kafka 的存储机制的特殊处理
1. 消息的保存路径
Kafka 是使用日志文件的方式来保存消息,每条消息都有一个 offset 值来表示它在分区中的偏移量。Kafka 中存储的多少巨量的消息数据,文件过大是常态,因此 Log 并不是对应一个具体的文件,而是对应磁盘上的一个目录。
2. 零拷贝
在消费者获取消息时,服务器先从硬盘读取数据到内存,然后把内存中的数据原封不动的通过 socket 发送给消费者。这个过程需要 4 次数据复制,但是这个过程中,数据没有变化,仅仅是从磁盘复制到网卡缓冲区。
零拷贝,并不是一次不拷贝。通过使用 sendfile,只需要一次拷贝就行,允许操作系统将数据直接从页缓存发送到网络上。
9. Kafka 什么情况下会丢失消息?
前提:min.insync.replicas=1 的时候。
虽然消息被写入 Leader 端的日志就被被认为是已提交,但是 HW 的更新是有延迟的。如果这时 Leader 宕机了,就会选举新 Leader,新 Leader 肯定没有还没同步的 HW 的,这样客户端认为提交成功了,但是对于服务端来说提交没成功。
10. Kafka 所有的 Replica 不工作的情况怎么办
哪怕有一个副本存在,数据都可以不丢失,但如果所有副本都宕机了,就无法保证数据不丢失了。
这是需要选择 Leader,为了可用性,可以选择第一个恢复的副本,但是如果它不属于 ISR,那么它的数据就可能不是最新的。也可以等 ISR 中第一个恢复的副本。
总之选择一个最能接收的副本,然后选举 Leader,继续工作。
1. 单表数据达到多少的时候会影响数据库的查询性能?为什么?
这个问题其实没有标准的答案,最主要的是看具体业务的查询性能。如果只是单表查询的话,几千万根本不成问题。
索引的数据结构采用 B+ 树,见下图:
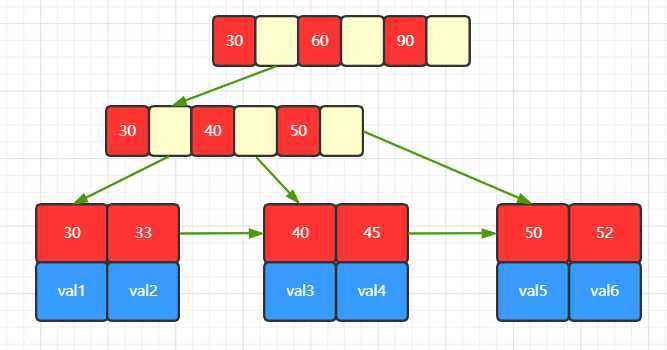
B+ 树有个创新:非叶子节点,不存储数据,只是帮助寻找叶子节点的指路明灯。
这个创新,给 B+ 树带来了两个重要的特性:
由于非叶子节点不包含数据,节点占用空间很小,这样一次磁盘 IO 读取就可以将更多的节点加载到内存。由于非叶子节点不包含数据,那么每次查询都要走到叶子节点,所有关键字查询的时间相差不多,这样查询效率就是稳定的。最后 B+ 树将所有叶子节点通过指针连接在一起,这样范围查询,只需要定位范围的开始节点即可,后面顺序读取即可。
注意,图示展示的是主键索引的 B+ 树。
索引不是万能的:
1. 建了索引,也得命中才行,索引命中不了,就是全表扫描,这时几千万条数据就真的很恐怖了。关于最左边匹配等各种索引命中的思想不是这题的重点,不重点描述了。2. 索引是占用空间的,索引越多,内存需要 通过磁盘 IO 加载的索引数据也越多。磁盘 IO:
既然是磁盘 IO,性能就会受到硬件限制。机械磁盘存储时,很难做到大量的顺序读写,这样磁头就得不断的寻找地址,速度也就慢了下来。而固态硬盘由于设计的原因,没有了寻道这一步,速度快了很多倍。
复杂查询:
如果是复杂查询,数据量也在不断攀升,那么数据库是千万级别是无法承受的。
1. 建立缓存,稳定的数据,热点数据,都应该尽量走缓存。分布式缓存不够,就建立多级缓存,让分布式缓存和本地缓存相结合。2. 复杂 SQL 拆分,尽量单表查询,通过一个表的查询结果再去另外的表做过滤查询。对用户来说,他不可能看太多数据,一页超过 20 条就够多了,用户也没有忍心一遍一遍的翻页,数据太多,他会修改查询条件。我们的 SQL 也可以因此做针对性处理。3. 分库分表,单机的性能毕竟是有上限的,数据不断的上涨就需要不断的分散在不同的节点上。分片规则要考虑表的业务特点,主要是查询方便。2. 主从复制的原理是什么?常见的形式有哪些?
Master 的所有 DDL 操作,都记录成一个二进制日志,binlog。 slave 有 1 个 IO Thread,进行 binaryLog 的日志。Slave 通过 SQL Thread,执行这个 binaryLog 日志文件。
MySQL 主从复制主要有以下几种方式:
1. 基于 SQL 语句的复制(statement-based replication,SBR)2. 基于行的复制(row-based replication,RBR)3. 混合模式复制(mixed-based replication,MBR)3. 分库分表,解释一下垂直和水平 2 种不同的拆分?
垂直:基于业务的拆分,业务比较紧密的几张表,捏合在一个小库里。比如用户表,订单表在一个库,日志表在另外的库。水平:拆分的是一张大表,大表拆分为小表。比如 去年的订单一张表,今年的订单一张表。4. 垂直拆分会带来哪些问题?
分布式事务
比如,用户表、订单表、资金表如果不在同一个库中,那么之前的事务就变成了分布式事务。
垮库的关联查询
关联表尽量放在一个库中,但是业务总在变化,之前不做关联的可能现在也做关联了。
5. 分布式数据存储中间件 MyCat 的核心流程是什么?
1. 解析 SQL2. 数据源管理3. 数据源分配4. 请求响应5. 结果整合6. 概述一下 MyCat?
1. 开源的、基于 Cobar 的框架2. 解决分布式存储问题3. 解决分库分表和读写分离4. 是处于数据层和业务层之间的一个中间层,看成数据库的代理。7. 解释一下全局表、ER 表、分片 表?
全局:
数据字典表,应该放在哪个分库。为了管理查询,每个节点都放这个表。
ER 表:
有 ER 关系,和用户有 ER 关系的,比如用户收货地址。用户已经拆分了,那么关联的收货地址也拆分。全局表也可以,但是冗余太多了。
分片表:
水平拆分的用户表就是分片表。
8. MyCat 在分库分表之后,是怎么支持连表查询的?
1. 全局表:每个分库都存一份,直接连表即可。2. ER 表:配置关联的主键 ID,比如 order 表的 user_id 是和 user 表关联的,user_id 对应的两张表数据会放在同一个分库里。3. sharejoin,解析 SQL 语句,拆分成单表的 SQL 语句执行,然后把各个节点的数据汇集。9. 库表拆分时,拆分规则怎么取舍?
拆分规则 = 离散 + 连续
离散:数据分布均匀,并发能力强。但是扩容性差。连续:扩容不需要迁移数据,范围查询快,但并发能力受限。抉择:
根据数据特点,和查询需求来选择规则,甚至可以二者结合,先离散再连续,或者先连续再离散。
10. 全局 ID 方案有哪些?程序自定义全局 ID 方案有哪些?
1. 本地方式2. 数据库方式3. 本地时间戳4. 自定义 snowflake11. 一致性 hash 的原理?设计的好处是什么?
把整个节点看成一个换,把节点落在环中。数据落入环,顺时针找节点。好处解决增,减节点的影响问题。
在 MyCat 中,一致性 hash 解决了扩容的问题。
12. 四层负载和七层负载谁性能更高,为什么?
四层性能更高、更底层。只做转发、路由。七层和前端建立连接,不让你直接连接后端。
Haproxy 就是四层负载,有人评价它的性能接近硬件。
13. 讲一讲 MySQL 的高可用方案?
MySQL 高可用,意味着不能一台 MySQL 出了问题,就不能访问了。
1. MySQL 高可用:分库分表,通过 MyCat 连接多个 MySQL2. MyCat 也得高可用:Haproxy,连接多个 MyCat3. Haproxy 也得高可用:通过 keepalived 辅助 Haproxy1. CAP 理论
CAP = Consistency + Availability + Partition
CAP = 一致性 + 可用性 + 分区容错性
CAP 理论说的是 CAP 无法同时满足,最多同时满足两个。
一致性:针对的是数据,多个节点在更新数据后,数据一致的。可用性:针对的是服务状态,用户的请求总是能在合理的时间范围内返回。分区容错性:针对网络故障的情况,系统仍然能够对外提供满足一致性和可用性的服务。由于分布式的特点,系统一定会部署在多个节点上,网络故障不可避免。因此,P 一定需要满足,我们往往在 C 和 A 中抉择。
大家可能会经常听到一致性算法,现实中,我们基本在一致性上做文章,将强一致性改为最终一致性。
2. Paxos 协议
Paxos 是一种居于消息传递且具有高度容错性的一致性算法。
简单说 Paxos 就是为了大家在某件事上能够达成一致的,听起来很简单,麻烦在于几个人不是面对面的,大家距离很远,那么消息在传输中可能出现延迟,重复,丢失,甚至被人修改。
它是一个两阶段 2PC 协议 = Prepare 阶段 + Accept 阶段。这里面定义了两大参与人:Proposer 和 Acceptor。
Proposer 是提出想法的人,Acceptor 是批准想法的人。现实中,一个人可以同时是 Proposer 和 Acceptor。
Proposer 表面上的活就两个:生成 提案 和 收到多数回复就发起最终投票。Acceptor 表面上的活就两个:应答 Prepare 和 接收 Prepare。Prepare 阶段:Proposer,生成一个全局唯一而且递增的 ID,递增很重要。把 ID 发给集群所有节点,比如 ID = 166。
拿到 116 后,Acceptor 明白了两件事:
我已经收到 116 的请求,再来一个 116 的请求我都不会 Prepare 了。116 之前的请求像 115,114 之类的更不会 Prepare。记住 Acceptor 是个懒人,活最多干一遍。116 之前的 Accept 也不会再处理了。因此,Acceptor 需要干一件事,把 116 记住,也就是把 ID 持久化到本地。
Accept 阶段:
1. Proposer 收到半数以上的 Acceptor 的回答,这里就是 116,如果同时有 116 和 115 呢,最也选择最大的 116,带上提案内容发给 Acceptor 们。2. Acceptor 收到 116 和提案后,看看自己是否 Accept 过 116。没有,很好,持久化 116 和 提案内容,回复 Proposer。Proposer 收到多数的回复后,形成决议。关键词:2PC、半数以上、全局唯一递增 ID。
3. Raft 协议
Raft 写在 Paxos 之后,主要就是要做对比。
相同点:
为了实现一致性需要大多数选民投票不同点:
提出 Leader 概念,处理所有客户端请求,不同节点数据复制。Leader 只有一个。提出“选民”概念,等待被通知投票。提出“候选人”概念,选举中提名自己。Raft 算法 = 选举过程 + 数据同步
4. 设计一个全局唯一的 ID
全局:指的是微服务运行时的多个节点中。全局唯一:最保险的方案就是加上全局锁,生成 ID,生成完在校验后 ID 是否已经存在过。绝对的安全往往拉低了性能。时间有序性:时间总是递增的,将时间列入 ID,性能可以保证,而且又不会重复。不同节点时间不同步的问题:这个问题很难避免,因此 ID 中 可以加入 节点的编号。节点的编号不能重复,否则就是人为 bug 了。同一个节点时间倒退怎么办:这个问题也不能避免,因此 ID 中 可以加入 本节点的增长序列。ID = 20 长度的秒时间或者毫秒时间 + 节点 ID + 节点序列数
这就是一个简单的全局 ID,实际开发中可以需求,加入其它元素,方便实现需求,定位问题。
1. 谈谈分词与倒排索引的原理
首先说分词是给检索用的。
英文:一个单词一个词,很简单。I am a student,词与词之间空格分隔。中文:我是学生,就不能一个字一个字地分,我-是-学生。这是好分的。还有歧义的,使用户放心,使用-户,使-用户。人很容易看出,机器就难多了。所以市面上有各种各样的分词器,一个强调的效率一个强调的准确率。倒排索引:倒排针对的是正排。
正排就是我记得我电脑有个文档,讲了 ES 的常见问题总结。那么我就找到文档,从上往下翻页,找到 ES 的部分。通过文档找文档内容。倒排:一个 txt 文件 ES 的常见问题 -> D:/分布式问题总结.doc。所以倒排就是文档内容找文档。当然内容不是全部的,否则也不需要找文档了,内容就是几个分词而已。这里的 txt 就是搜索引擎。
2. 分段存储的思想
Lucene 是著名的搜索开源软件,ElasticSearch 和 Solr 底层用的都是它。
分段存储是 Lucene 的思想。
早期,都是一个整个文档建立一个大的倒排索引。简单,快速,但是问题随之而来。
文档有个很小的改动,整个索引需要重新建立,速度慢,成本高,为了提高速度,定期更新那么时效性就差。
现在一个索引文件,拆分为多个子文件,每个子文件是段。修改的数据不影响的段不必做处理。
3. 段合并的策略思想
分段的思想大大的提高了维护索引的效率。但是随之就有了新的问题。
每次新增数据就会新增加一个段,时间久了,一个文档对应的段非常多。段多了,也就影响检索性能了。
检索过程:
1. 查询所有短中满足条件的数据2. 对每个段的结果集合并所以,定期的对段进行合理是很必要的。真是天下大势,分久必合合久必分。
策略:将段按大小排列分组,大到一定程度的不参与合并。小的组内合并。整体维持在一个合理的大小范围。当然这个大到底应该是多少,是用户可配置的。这也符合设计的思想。
4. 文本相似度 TF-IDF
简单地说,就是你检索一个词,匹配出来的文章,网页太多了。比如 1000 个,这些内容再该怎么呈现,哪些在前面哪些在后面。这需要也有个对匹配度的评分。
TF-IDF 就是干这个的。
TF = Term Frequency 词频,一个词在这个文档中出现的频率。值越大,说明这文档越匹配,正向指标。IDF = Inverse Document Frequency 反向文档频率,简单点说就是一个词在所有文档中都出现,那么这个词不重要。比如“的、了、我、好”这些词所有文档都出现,对检索毫无帮助。反向指标。TF-IDF = TF / IDF
复杂的公式,就不写了,主要理解他的思想即可。
5. ElasticSearch 写索引的逻辑
ElasticSearch 是集群的 = 主分片 + 副本分片。
写索引只能写主分片,然后主分片同步到副本分片上。但主分片不是固定的,可能网络原因,之前还是 Node1 是主分片,后来就变成了 Node2 经过选举成了主分片了。
客户端如何知道哪个是主分片呢? 看下面过程。
1. 客户端向某个节点 NodeX 发送写请求2. NodeX 通过文档信息,请求会转发到主分片的节点上3. 主分片处理完,通知到副本分片同步数据,向 Nodex 发送成功信息。4. Nodex 将处理结果返回给客户端。6. ElasticSearch 集群中搜索数据的过程
1. 客户端向集群发送请求,集群随机选择一个 NodeX 处理这次请求。2. Nodex 先计算文档在哪个主分片上,比如是主分片 A,它有三个副本 A1,A2,A3。那么请求会轮询三个副本中的一个完成请求。3. 如果无法确认分片,比如检索的不是一个文档,就遍历所有分片。补充一点,一个节点的存储量是有限的,于是有了分片的概念。但是分片可能有丢失,于是有了副本的概念。
比如:
ES 集群有 3 个分片,分片 A、分片 B、分片 C,那么分片 A + 分片 B + 分片 C = 所有数据,每个分片只有大概 1/3。分片 A 又有副本 A1 A2 A3,数据都是一样的。
7. ElasticSearch 深翻页的问题及解决
深翻页:比如我们检索一次,轮询所有分片,汇集结果,根据 TF-IDF 等算法打分,排序后将前 10 条数据返回。用户感觉不错,说我看看下一页。ES 依然是轮询所有分片,汇集结果,根据 TF-IDF 等算法打分,排序后将前 11-20 条数据返回。
对用户来说,翻页应该很快啊,但是实际上,第一次检索多复杂,下一次检索就多复杂。
解决的话,可以把用户的检索结果,存入 Redis 中 10 分钟。这样分页就很快,超过 10 分钟,用户不翻页,也就不会翻页了,数据就可以清除了。
8. ElasticSearch 性能优化
1. 批量提交
背景是大量的写操作,每次提交都是一次网络开销。网络永久是优化要考虑的重点。
2. 优化硬盘
索引文件需要落地硬盘,段的思想又带来了更多的小文件,磁盘 IO 是 ES 的性能瓶颈。一个固态硬盘比普通硬盘好太多。
3. 减少副本数量
副本可以保证集群的可用性,但是严重影响了 写索引的效率。写索引时不只完成写入索引,还要完成索引到副本的同步。ES 不是存储引擎,不要考虑数据丢失,性能更重要。 如果是批量导入,建议就关闭副本。
1. 分布式事务的几种实现方式
大家熟悉的 ACID 是针对单机事务的。而 CAP 和 BASE 是针对分布式事务的,最常见的是 BASE。
BASE = Basically Available 基本可用 + Soft state 软状态 + Eventually Consistent 最终一致性
重点就是最终一致性。非 TCC 方案如下:
1. 消息队列
一个完整的服务拆成了几块,就放入几个队列。
服务 A 完成,放入队列 X服务 B 监听队列 X,监听到数据,完成自己的逻辑,放入队列 Y服务 C 监听队列 Y,监听到数据,完成整个服务。如果失败,放入失败队列,服务 A 和服务 B 监听到后回滚2. 最大努力通知方案
服务 A 本地事务执行完之后,发送个消息到队列 X。消费队列 X 的服务就会拿到消息,首先将消息持久化,防止后续执行失败,数据丢失,然后调用下一个服务 B 的接口。如果服务 B 执行失败了,那么消费者会多调用几次服务 B,最后还是不行就会采取人工干预。2. TCC 柔性分布式事务
TCC = try + confirm/cancel
柔性 = 基于 BASE 理论实现的分布式事务
TCC 事务,每个需要实现事务的服务,都需要实现三个接口。
1. try 业务检查,资源预留2. confirm 执行业务,使用资源3. cancel 回滚业务,释放资源TCC 的特点:
1. 借用了 XA 的思想,但不是 2PC2. 事务过程,数据不会加锁3. 出错时可能多次调用 confirm 和 cancel,顺序无法保证4. confirm 和 cancel 需要开发人员满足幂等性3. TCC-Transaction 框架的原理
TCC 思想的一种开源实现。代码中有使用的例子:资金和红包下订单。下面是 GitHub 上关于 TCC 的介绍。
Try:尝试执行业务
1. 完成所有业务检查(一致性)2. 预留必须业务资源(准隔离性)Confirm:确认执行业务
1. 真正执行业务2. 不作任何业务检查3. 只使用 Try 阶段预留的业务资源4. 只使用 Try 阶段预留的业务资源Cancel:取消执行业务
1. 释放 Try 阶段预留的业务资源2. Cancel 操作满足幂等性想必这些描述,大家已经很熟了,就是不知道如何下手。我通过它的例子解释一下。
主业务模块:订单子业务模块:资金,红包try:
主业务:插入订单记录,状态为草稿资金业务:插入资金流水记录,买家资金余额扣除红包业务:插入红包流失记录,买家红包余额扣除confirm:
主业务:修改订单记录,状态为支付资金业务:卖家资金余额增加红包业务:卖家红包余额增加cancel:
主业务:修改订单记录,状态为支付失败资金业务:买家资金余额恢复红包业务:买家红包余额恢复总结下:
1. try 这里预留的资源是买家的资金和红包2. confirm 真正使用资源,就是把资金和红包给卖家3. cancel 释放资源,就是把买家的资金和红包恢复1. Nginx 的动静分离
动是什么?
依赖后台服务器的都是动,比如后台接口返回的数据。
静是什么?
不依赖后台服务器的,比如 css,js,jpg,html 这些都是静。
动静分离有什么意义?
静态文件的特点,很少变化,那么就可以做缓存,压缩提高网络传输的性能。而 Nginx 就是一个静态 Web 服务器。
2. Nginx 的防盗链
网站上总是有些总很多图片,比如有人的网站想调用你的图片怎么办?
你肯定会想到版权的问题,可除了版权还有个问题,就是服务器压力,对方的网站调用一次就会给你服务器一次调用压力,刷新更是所有调用都会重来一次。防盗链可以禁止这种调用。
HTTP 的请求头有个属性 Refer,它包含了请求的来源。Nginx 可以设置 Refer 的校验工作。
题外,Refer 是可以伪造的,Nginx 无法解决所有的问题。
3. Nginx 的跨域访问
请求 = 协议 + 域名 + 端口 + 应用名
如果两个请求,有一项不一样,那就涉及到了跨域。说白了,就是你调用了第三方的请求,或者第三方调用了你的请求。
浏览器为了安全,禁止跨域调用。
说到这里,禁止跨域访问是好事。但是,多系统集成难免涉及到跨域。Nginx 可以设置允许哪些跨域操作。
4. Nginx 的进程模型
启动 Nginx 后,查看进程,你会发现 Nginx 有多个进程。不像 Java 就一个进程。
Nginx = 一个 Master 进程 + 多个 Worker 进程
Worker 进程数随 CPU 核心数量变化而变化。
Master:包工头,到处接活,但是自己不干,给手下的工人干。Worker:接 Master 的活,同样的活就一个 Worker 干。Worker 可以理解 Master 的想法,因为它是 Master fork 来的。
IO 模型用的 epoll 模型,也就是异步非阻塞。底层读写的等待最要命,调用完就返回了,不在阻塞。处理完了通知我下,我好继续处理。
5. Nginx 与网关
网关: 从一个网络到另一个网络,必须要经过的关口。API 网关:访问所有 API 需要先经过的关口。网关是入口: 那么很多共同操作,就可以放在网关了,比如登录认证、流量统计控制、日志处理等待。Nginx 作为反向代理人服务器,天然就是一个网关。
如果 Nginx 要实现复杂的网关功能,就需要结合 OpenResty 来实现。
OpenResty 为什么能实现网关呢?
OpenResty 有一个非常重要的因素是,对于每一个请求,Openresty 会把请求分为不同阶段,这样每个阶段都可以用 Lua 脚本实现不同的业务逻辑。
6. Nginx 的高可用方案
Nginx 是瓶颈:
虽然 Nginx 是一个高性能 Web 服务器,但是单台机器总是有流量上限的。谁能协助 Nginx 搭建集群环境呢。答案是 keepalived。
keepalived:
它最早是 LVS 集群的一部分,后来有了 VRRP 功能,keepalived 就得到突破,可以给其他软件提供高可用方案了。
VRRP:
虚拟路由冗余协议,个别节点宕机,整个网络可以不间断运行。 其实就是把多个设备虚拟成一个设备,对外提供服务,实现主备高可用。
但是虚拟以后,IP 呢,你总要一个 IP,这个 IP 的节点挂了,不还是不行吗?
VIP:
虚拟 IP,LVS 提出了 虚拟 IP 的概念,这样 IP 就和设备无关了。 VRRP 通过解析 VIP 然后处理请求的分发。
Refer:https://gitbook.cn/gitchat/activity/5eb8ce3917121b4e04b41d7f
原文:https://www.cnblogs.com/traditional/p/13053166.html