Apache ZooKeeper 是一个开源的实现高可用的分布式协调服务器。ZooKeeper是一种集中式服务,用于维护配置信息,域名服务,提供分布式同步和集群管理。所有这些服务的种类都被应用在分布式环境中,每一次实施这些都会做很多工作来避免出现bug和竞争条件。
ZooKeeper 允许分布式进程通过共享的分层命名空间相互协调,ZooKeeper命名空间与文件系统很相似,每个命名空间填充了数据节点的注册信息 - 叫做Znode,这是在 ZooKeeper 中的叫法,Znode 很像我们文件系统中的文件和目录。ZooKeeper 与典型的文件系统不同,ZooKeeper 数据保存在内存中,这意味着 ZooKeeper 可以实现高吞吐量和低时延。
与它协调的分布式进程一样,ZooKeeper本身也可以在称为集群的一组主机上进行复制。
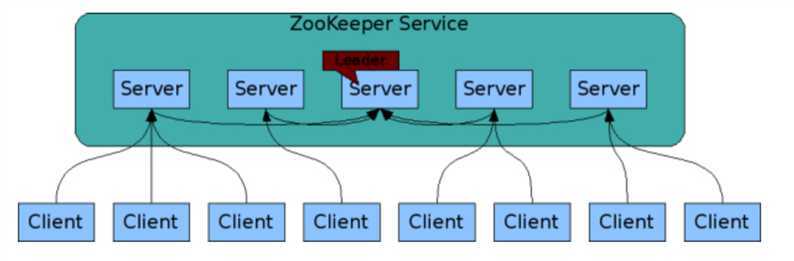
组成 ZooKeeper 服务的单个服务端必须了解彼此。它们维护内存中的状态、持久性的事务日志和快照。只要大多数服务可用,ZooKeeper 服务就可用。
客户端可以连接到单个的服务器。客户端通过连接单个服务器进而维护 TCP 连接,通过连接发送请求,获取响应,获取监听事件以及发送心跳,很像Eureka Server 的功能。如果与单个服务器的连接中断,客户端会自动的连接到ZooKeeper Service 中的其他服务器。
ZooKeeper使用时间戳来记录导致状态变更的事务性操作,也就是说,一组事务通过时间戳来保证有序性。基于这一特性。ZooKeeper可以实现更加高级的抽象操作,如同步等。
ZooKeeper包括读写两种操作,基于ZooKeeper的分布式应用,如果是读多写少的应用场景(读写比例大约是10:1),那么读性能更能够体现出高效。
ZooKeeper提供的命名空间非常类似于标准文件系统。名称是由斜杠(/)分隔的路径元素序列。 ZooKeeper名称空间中的每个节点都由路径标识。
ZooKeeper的分层命名空间图
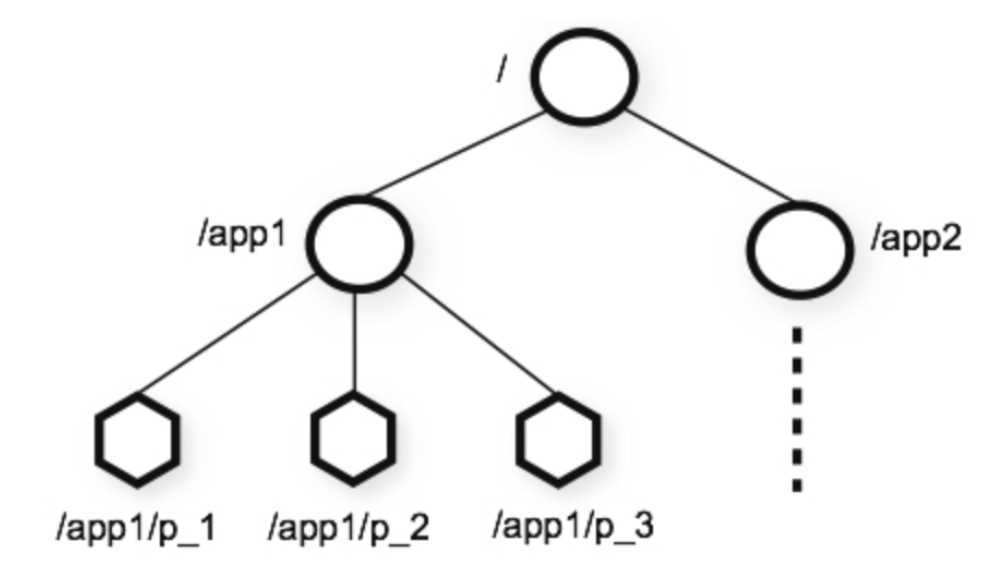
与标准的文件系统所不同的是,ZooKeeper命名空间中的每个节点都可以包含与之关联的数据以及子项,这就像一个文件也是目录的文件系统。ZooKeeper被设计用来存储分布式数据:状态信息,配置,定位信息等等。所以每个ZooKeeper 节点能存储的容量非常小,最大容量为 1MB。我们使用术语 Znode 来表明我们正在谈论ZooKeeper数据节点。
Znodes 维护了一个 stat 结构,包括数据变更,ACL更改和时间戳的版本号,用来验证缓存和同步更新。每一次Znode 的数据发生了变化,版本号的数量就会进行增加。每当客户端检索某个znode 数据时,它也会接收该数据的版本。
命名空间下数据存储的Znode 节点都会以原子性的方式读写,也就是保证了原子性。读取所有Znode 相关联的节点数据并通过写的方式替换节点数据。每一个节点都会有一个 访问控制列表(ACL)的限制来判断谁可以进行操作。
ZooKeeper 也有临时节点的概念。只要创建的 Znode 的会话(session)处于活动状态,就会存在这些临时节点。当会话结束,临时节点也就被删除。
ZooKeeper支持watches的概念。客户端可以在 Znode 上设置监听。当 Znode 发生变化时,监听会被触发并移除。触发监听时,客户端会收到一个数据包告知 Znode 发生变更。如果客户端与其中一个 ZooKeeper 服务器之间的连接中断,则客户端将收到本地通知。
通常在分布式系统中,构成一个集群中的每一台机器都有一个自己的角色,最典型的集群模式就是 master/slave (主备模式)。在这种模式中,我们把能够处理写操作请求的机器成为 Master ,把所有通过异步复制方式获取最新数据,并提供读请求服务的机器成为 Slave 机器。
而 ZooKeeper 没有采用这种方式,ZooKeeper 引用了 Leader、Follower和 Observer 三个角色。ZooKeeper 集群中的所有机器通过选举的方式选出一个 Leader,Leader 可以为客户端提供读服务和写服务。除了 Leader 外,集群中还包括了 Follower 和 Observer 。Follower 和 Observer 都能够提供读服务,唯一区别在于,**Observer ** 不参与 Leader 的选举过程,也不写操作的"过半写成功"策略,因此 Observer 可以在不影响写性能的情况下提升集群的读性能。
Session 指的是客户端会话,在讲解会话之前先来了解一下客户端连接。客户端连接指的就是客户端和服务器之间的一个 TCP长连接,ZooKeeper 对外的端口是 2181,客户端启动的时候会与服务器建立一个 TCP 连接,从第一次连接建立开始,客户端会话的生命周期也就开始了,通过这个连接,客户端能够通过心跳检测与服务器保证有效的会话,也能够向 ZooKeeper 服务器发送请求并接受响应,同时还能够通过该连接来接收来自服务器的Watch 事件通知。
ZooKeeper 非常快并且很简单。但是,由于其开发的目的在于构建更复杂的服务(如同步)的基础,因此它提供了一系列的保证,这些保证是:
ZooKeeper 设计之初提供了非常简单的编程接口。作为结果,它支持以下操作:
ZooKeeper Components 展现了ZooKeeper 服务的高级组件。除请求处理器外,构成 ZooKeeper 服务的每个服务器都复制其自己的每个组件的副本。
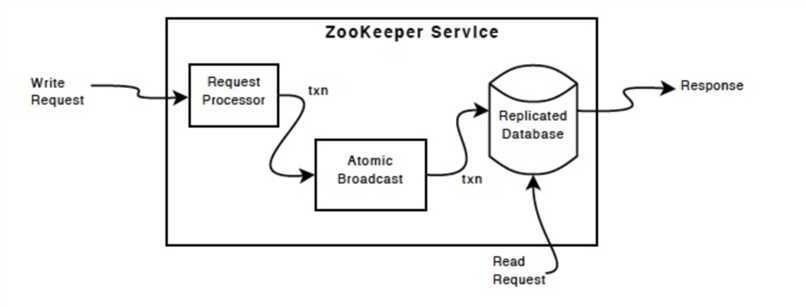
图中的 Replicated Database (可复制的数据库)是一个包含了整个数据树的内存数据库。更新将记录到磁盘以获得可恢复性,并且写入在应用到内存数据库之前会得到序列化。
每一个 ZooKeeper 服务器都为客户端服务。客户端只连接到一台服务器用以提交请求。读请求由每个服务器数据库的本地副本提供服务,请求能够改变服务的状态,写请求由"同意协议"进行通过。
作为"同意协议" 的一部分,所有的请求都遵从一个单个的服务,由这个服务来询问除自己之外其他服务是否可以同意写请求,而这个单个的服务被称为Leader。除自己之外其他的服务被称为follower,它们接收来自Leader 的消息并对消息达成一致。消息传底层负责替换失败的 leader 并使 follower 与 leader 进行同步。
ZooKeeper 使用自定义的原子性消息传递协议。因为消息传底层是原子性的,ZooKeeper 能够保证本地副本永远不会产生分析或者冲突。当 leader 接收到写请求时,它会计算系统的状态以确保写请求何时应用,并且开启一个捕获新状态的事务。
ZooKeeper 的编程接口非常简单,但是通过它,你可以实现更高阶的操作。
ZooKeeper 旨在提供高性能,但是真的是这样吗?ZooKeeper是由雅虎团队开发。当读请求远远高于写请求的时候,它的效率很高,因为写操作涉及同步所有服务器的状态。(读取数量超过写入通常是协调服务的情况。)
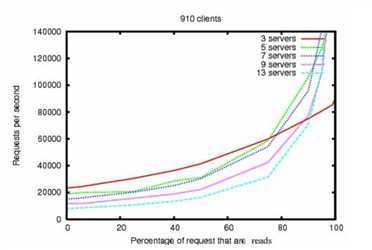
ZooKeeper吞吐量作为读写比率变化是在具有双2Ghz Xeon和两个SATA 15K RPM驱动器的服务器上运行的ZooKeeper版本3.2的吞吐量图。一个驱动器用作专用的ZooKeeper日志设备。快照已写入OS驱动器。写请求是1K写入,读取是1K读取。 “服务器”表示ZooKeeper集合的大小,即构成服务的服务器数量。 大约30个其他服务器用于模拟客户端。 ZooKeeper集合的配置使得Leader不允许来自客户端的连接。(此部分来源于翻译结果)
基准也表明它也是可靠的。 存在错误时的可靠性显示了部署如何响应各种故障。 图中标记的事件如下:
为了在注入故障时显示系统随时间的行为,我们运行了由7台机器组成的ZooKeeper服务。我们运行与以前相同的饱和度基准,但这次我们将写入百分比保持在恒定的30%,这是我们预期工作量的保守比率。(此部分来源于翻译结果)
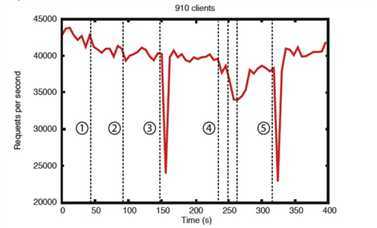
该图中有一些重要的观察结果。 首先,如果follower 失败并迅速恢复,那么即使失败,ZooKeeper也能够维持高吞吐量。 但也许更重要的是,leader 选举算法允许系统足够快地恢复以防止吞吐量大幅下降。 在我们的观察中,ZooKeeper 选择新 leader 的时间不到200毫秒。 第三,随着follower 的恢复,ZooKeeper能够在开始处理请求后再次提高吞吐量。
文章来源:
https://zookeeper.apache.org/doc/current/zookeeperOver.html
《从Paxos到zookeeper分布式一致性原理与实践》
原文:https://www.cnblogs.com/cxuanBlog/p/13057553.html