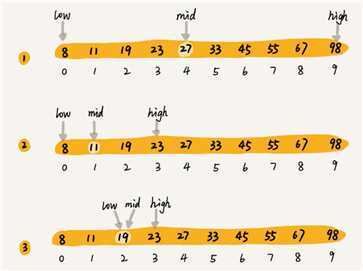
我们假设数据大小是 n,每次查找后数据都会缩小为原来的一半,也就是会除以2。最坏情况下,直到查找区间被缩小为空,才停止。

这是一个等比数列。其中 n/2^k = 1 时, k 的值就是总共缩小的次数。
而每一次缩小操作只涉及两个数据的大小比较,所以,经过了 k 次区间缩小操作,时间复杂度就是 O(k)。通过 n/2^k = 1,我们可以求得 k= log2n,所以时间复杂度就是 O(logn)。
O(logn) 这种对数时间复杂度。这是一种极其高效的时间复杂度,有的时候甚至比时间复杂度是常量级 O(1) 的算法还要高效。
因为 logn 是一个非常“恐怖”的数量级,即便 n 非常非常大,对应的 logn 也很小。
比如 n 等于2的32次方,这个数大约是42亿。也就是说,如果我们在 42 亿个数据中用二分查找一个数据,最多需要比较32次。
大 O 标记法表示时间复杂度的时候,会省略掉常数、系数和低阶。
对于常量级时间复杂度的算法来说, O(1) 有可能表示的是一个非常大的常量值,比如 O(1000)、 O(10000)。
所以,常量级时间复杂度的算法有时候可能还没有 O(logn) 的算法执行效率高。
反过来,对数对应的就是指数。指数时间复杂度的算法在大规模数据面前是无效的。
/**
* 二分法查找,非递归实现
*
* @param arr
* @param a
* @return
*/
public static int binarySearch(int[] arr, int a) {
int start = 0;
int end = arr.length - 1;
while (start <= end) { // 不能是start < end
int mid = start + ((end - start) >> 1); //start + (end - start)/2 位运算符速度快
if (arr[mid] == a) {
return mid;
} else if (arr[mid] > a) {
end = mid - 1; // end = min 有时会造成死循环
} else {
start = mid + 1;
}
}
return -1;
}
/**
* 二分法递归实现
*
* @param arr
* @param start
* @param end
* @param a
* @return
*/
public static int binarySearch2(int[] arr, int start, int end, int a) {
if (start > end) return -1;
int mid = start + ((end - start) >> 1);
if (arr[mid] == a) {
return mid;
} else if (arr[mid] > a) {
end = mid - 1;
return binarySearch2(arr, start, end, a);
} else {
start = mid + 1;
return binarySearch2(arr, start, end, a);
}
}
二分查找的时间复杂度是O(logn),查找数据的效率非常高。不过,并不是什么情况下都可以用二分查找,它的应用场景是有很大局限性的。
首先,二分查找依赖的是顺序表结构,就是数组。
二分查找针对的是有序数据。
数据量太大也不适合二分查找。
原文:https://www.cnblogs.com/xiexiandong/p/13057633.html