一、文件读写:
一、打开文件:open函数用来打开文件,语法:open (name, [ , mode[ , buffering]])
open函数使用一个文件名作为唯一的强制参数,然后返回一个文件对象,模式(mode)和缓冲(buffering)参数都是可选的。
例:假如有一个名为somefile.txt的文本文件,其存储路径是C:\text(或者在UNIX下的~/text),则可以这样打开文件:
f = open(r.‘C:\text\somefile.txt‘)
如果文件不存在,则会出现以下异常:
![]()
二、关闭文件:使用close方法关闭文件,通常一个文件对象在退出程序后(也可能在退出前)自动关闭,但关闭文件可以避免在某些操作系统或设置中进行无用的修改,也会避免用完系统中所打开文件的配额。
确保文件被关闭了,应使用try / finally语句,并且在finally子句中调用close语句
#Open your file here
try:
#Write data to your file
finally:
file.close()
有专门为这种情况设计的语句,在python2.5中引入,即with语句:
with Open("somefile.txt") as somefile:
do_something(somefile)
with语句可以打开文件并且将其赋值到变量中,之后就可以将数据写入语句体中的文件(或执行其他的操作),文件在语句结束后会被自动关闭,即便是由于异常引起的结束也是如此。
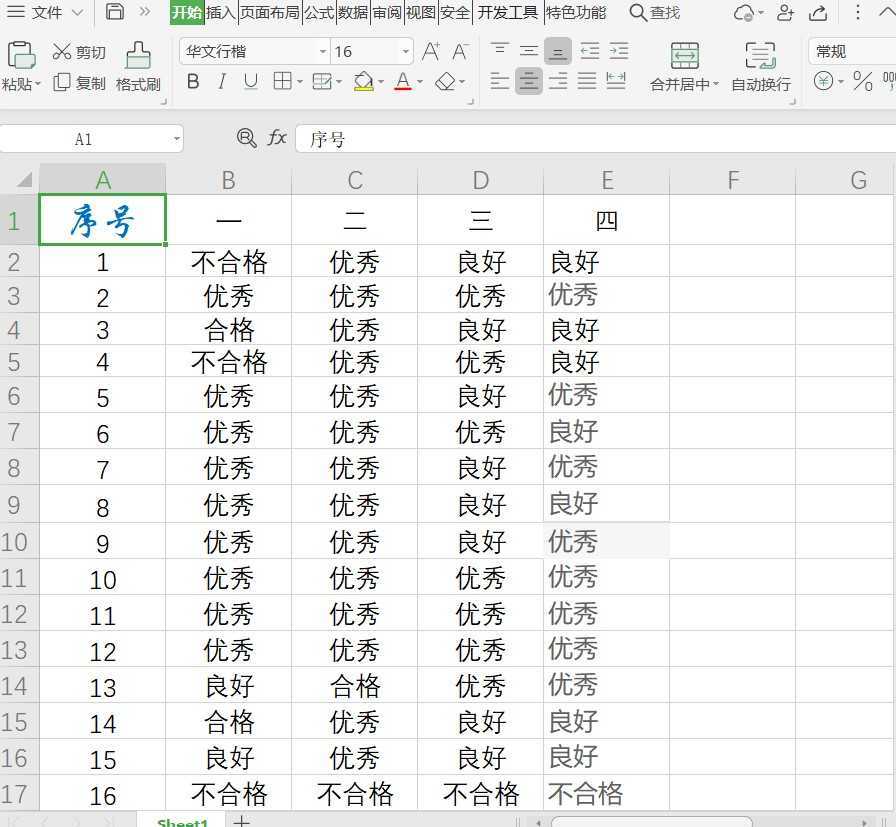
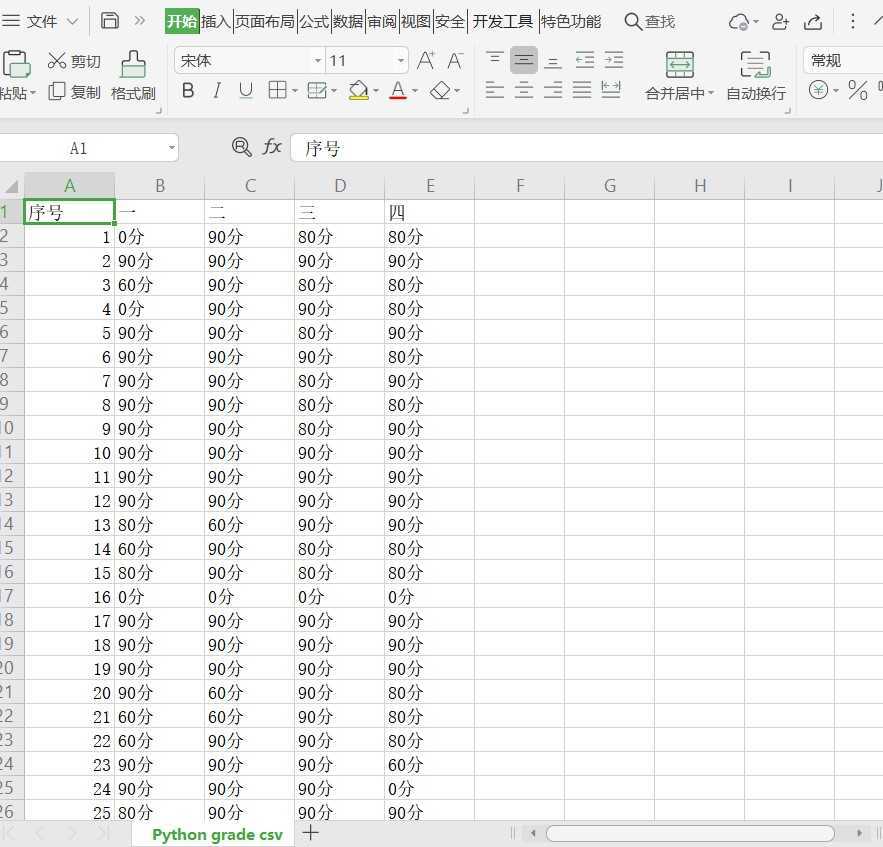
二、读入excel文件,并将其存为csv文件,把优秀改为90分,良好改为80分,及格改为60分,没交的改为0分
import pandas as pd
start=[‘优秀‘,‘良好‘,‘合格‘,‘不合格‘]
change=[‘90分‘,‘80分‘,‘60分‘,‘0分‘]
file=pd.read_excel("Python grade.xlsx")
l=len(file.index)
for index in range (l):
for i in range(4):
file.iloc[index]=file.iloc[index].replace(start[i],change[i])
file.to_csv("Python grade csv.csv",index=False,header=1)
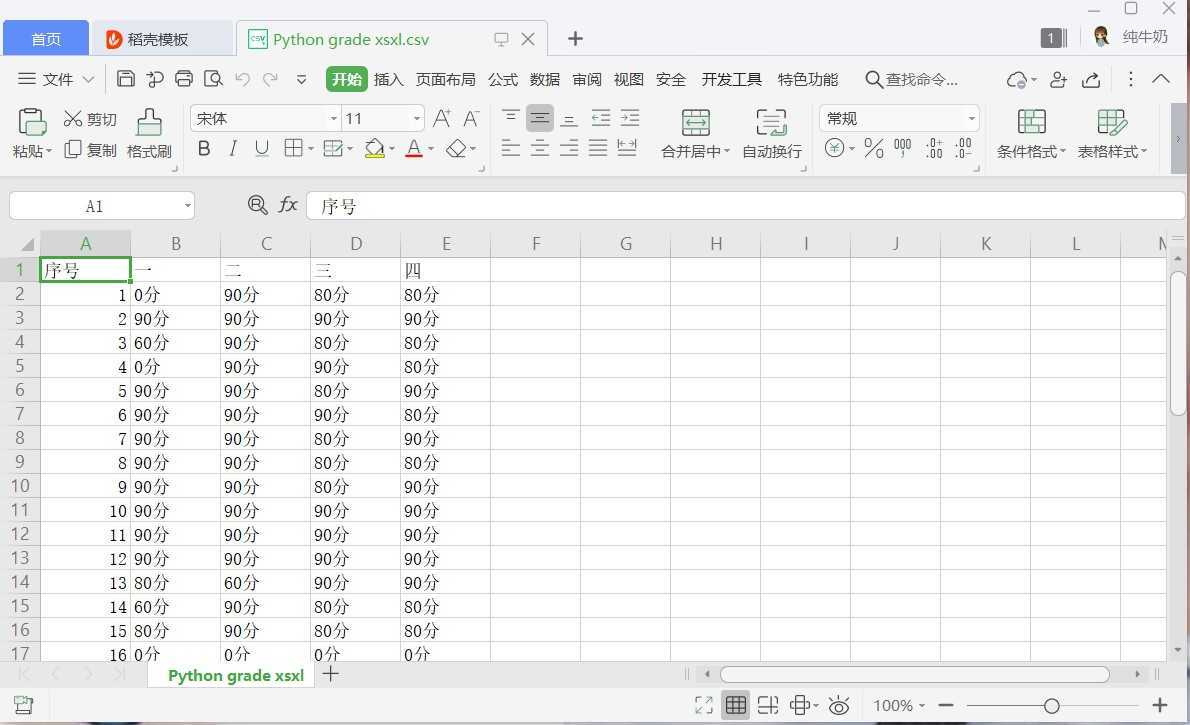
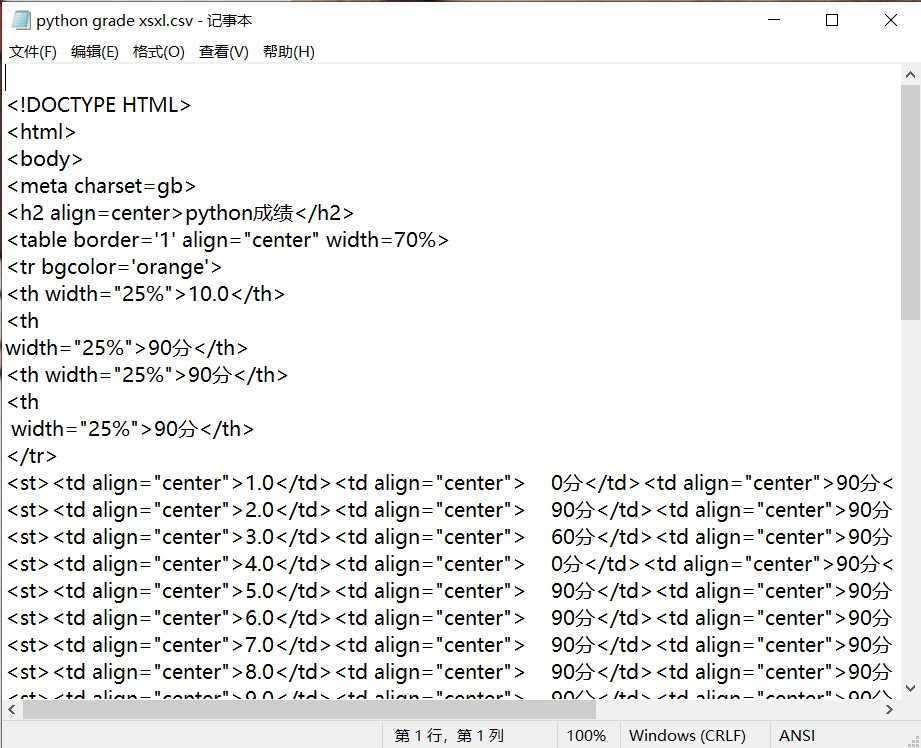
三、将上述的csv格式的文件转换为html文件(html文件用记事本打开):
seg1=‘‘‘
<!DOCTYPE HTML>\n<html>\n<body>\n<meta charset=gb>
<h2 align=center>python成绩</h2>
<table border=‘1‘ align="center" width=70%>
<tr bgcolor=‘orange‘>\n‘‘‘
seg2="</tr>\n"
seg3="</table>\n<body>\n</html>"
def fill_data(locls):
seg=‘<st><td align="center">{}</td><td align="center"> {}</td><td align="center">{}</td><tdalign="center"> {}</td></tr>\n‘.format(*locls)
return seg
fr=open("C:\code_python\Python grade xsxl.csv","rb+")
ls=[]
for line in fr:
line=line.decode()
line=line.replace("\n","")
ls.append(line.split(","))
fr.close()
fw=open("C:\code_python\python grade xsxl.csv.html","w")
fw.write(seg1)
fw.write(‘‘‘<th width="25%">{}</th>\n<th
width="25%">{}</th>\n<th width="25%">{}</th>\n<th
width="25%">{}</th>\n‘‘‘.format(*ls[10]))
fw.write(seg2)
for i in range(len(ls)-1):
fw.write(fill_data(ls[i+1]))
fw.write(seg3)
fw.close()
(1、在运行序列化过程中可能会出现的报错:UnicodeDecodeError : ‘ gbk ‘ codec can‘t decode byte 0x80 in position 0 : illegal multibyte sequence:
原因分析:序列化操作时,文件模式不正确,改为“rb+”即可
如:>>>fp = open("a.txt", " r+")
改为:>>>fp = open("a.txt", "rb+") #文件模式为字节处理
2、另外一种报错:TypeError : a bytes-like object is required, not ‘str‘:
字节流实际上是byte,而不是str,要想把byte变成str需要使用decode()方式,将str变成byte则需要encode()方法


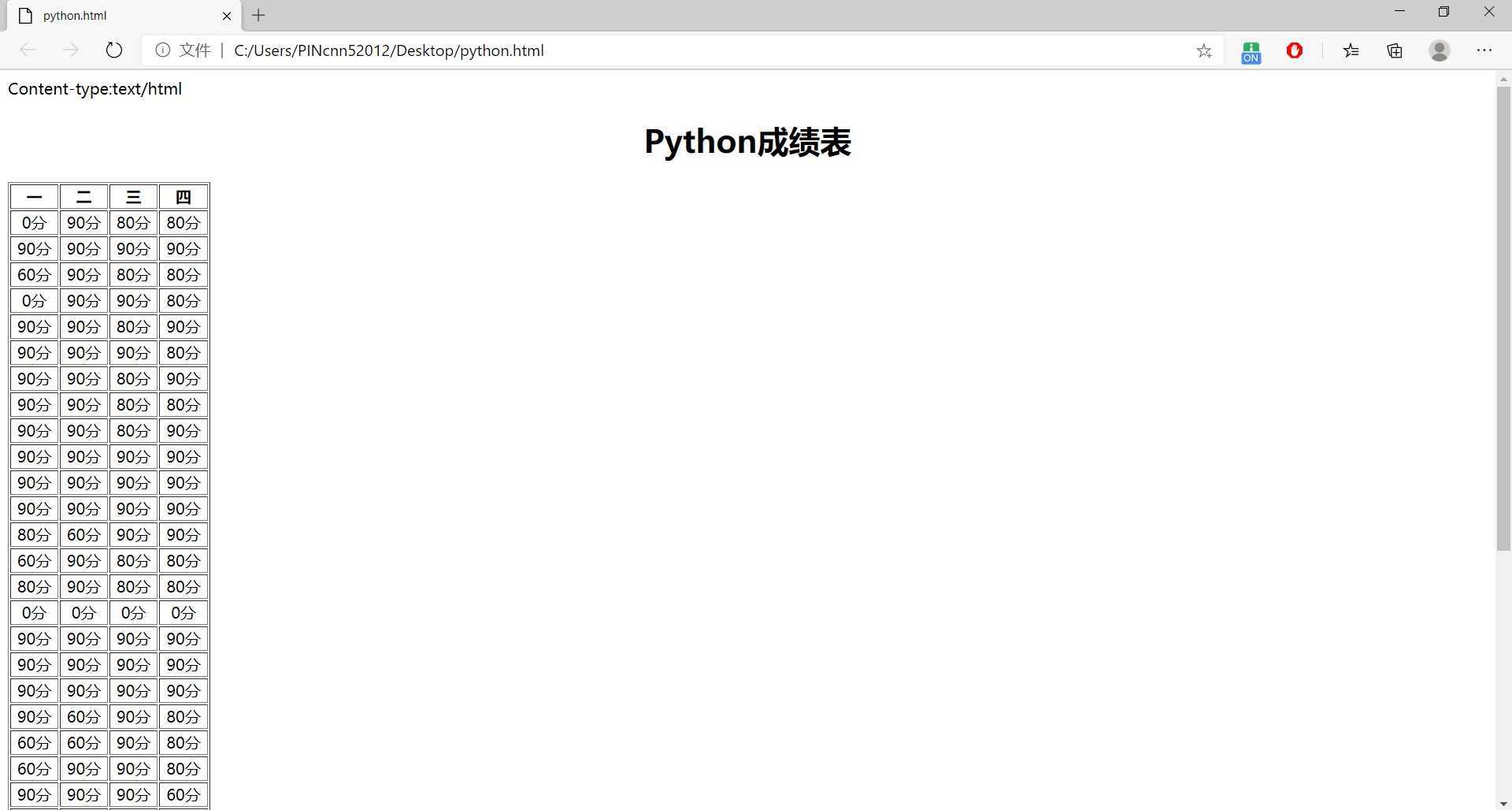
四、运用python CGI把上述csv格式文件,用网页显示:
def fill_data(excel, length=4):
‘‘‘
函数功能:填充表格的一行数据,返回html格式的字符串text
excel: 表格中的一行数据
length: 表格中需要填充的数据个数(即列数),默认为4个
由于生成csv文件时自动增加了1列数据,因此在format()函数从1开始
‘‘‘
text = ‘<tr>‘
for i in range(1,length):
tmp = ‘<td align="center">{}</td>‘.format(excel[i])
text += tmp
text += "</tr>\n"
return text
def GetCsv(csvFile):
‘‘‘
函数功能:打开csv文件并获取数据,返回文件数据
csvFile: csv文件的路径和名称
‘‘‘
ls = []
csv = open(csvFile, ‘r‘, encoding="utf-8")
for line in csv:
line = line.replace(‘\n‘, ‘‘)
ls.append(line.split(‘,‘))
return ls
def CsvToHtml(csvFile, thNum):
‘‘‘
csvFile: 需要打开和读取数据的csv文件路径
HTMLFILE: 保存的html文件路径
thNum: csv文件的列数,需注意其中是否包括csv文件第1列无意义的数据,
此处包含因此在调用时需要增加1
‘‘‘
csv_list = GetCsv(csvFile) # 获得csv文件数据
print("Content-type:text/html\r\n\r\n")
print(‘‘‘
<!DOCTYPE HTML>\n<html>\n<body>\n<meta charset=gbk2313>
<h1 align=center>Python成绩表</h2>
<table border=‘blue‘>\n‘‘‘) # 写html文件首部
for i in range(1, thNum): # 写表格的表头(即第1行)
print(‘<th width="20%">{}</th>‘.format(csv_list[0][i]))
print("</tr>\n")
for i in range(1, len(csv_list)): # 写表格的数据,从第2行开始为数据
print(fill_data(csv_list[i], 5))
print("</table>\n</body>\n</html>") # 写html文件尾部
CsvToHtml("C:\code_python\Python grade xsxl.csv", 5)
(1、在读取文件的过程中可能会出现报错:IndexError : list index out of range
这种错误的出现可能有两种原因:第一种:list [index] index 超出范围;第二种:list是一个空的,没有元素的列表,进行list[0]就会出现该错误。文件中有空行,删除并重新run一下就可以解决了。
2、在运行过程中python报错:PermissionError : [Error 13] Permission denied
这种错误的出现的原因是文件无法打开,可能产生的原因为:文件找不到、或者被占用、或者无权访问、或者打开的不是文件,而是一个目录。
解决:一、检查对应路径下的文件是否存在,且被占用;如果文件不存在,就找到对应文件即可,如果文件存在,被占用,将占用程序暂时关闭
二、修改cmd的权限,以管理员身份运行
三、检查是否打开了文件夹 )
原文:https://www.cnblogs.com/cnn-ljc/p/12953470.html