一些编程题
js算法题
答:
ie6,7不支持display:inline-block
参考自: 常见浏览器兼容性问题与解决方案
答:
在服务器配置Entity-Tag if-none-match
(1) 可搜索型
(2) 开放性
(3) 费用
(4) 易用性
(5) 易于开发
(1) 多媒体处理
(2) 兼容性
(3) 矢量图形 比SVG,Canvas优势大很多
(4) 客户端资源调度,比如麦克风,摄像头
参考:前端开发的优化问题
CSS3新特性:
参考:CSS3中的一些属性
答:
答:
参考自: 经验分享:CSS浮动(float,clear)通俗讲解
答:
|
1
2
|
.clearfloat:after{display:block;clear:both;content:"";visibility:hidden;height:0}.clearfloat{zoom:1} |
zoom:1的作用: 触发IE下的hasLayout。zoom是IE浏览器专有属性,可以设置或检索对象的缩放比例。
当设置了zoom的值之后,所设置的元素就会扩大或缩小,高度宽度就会重新计算了,这里一旦改变zoom值时其实也会发生重新渲染,运用这个原理,也就解决了ie下子元素浮动时候父元素不随着自动扩大的问题。
答: CSS Sprites其实就是把网页中一些背景图片整合到一张图片文件中,再利用CSS的“background-image”,“background- repeat”,“background-position”的组合进行背景定位,background-position可以用数字能精确的定位出背景图片的位置。
答:
1) <h1><img src="image.gif" alt="Image Replacement"></h1>
2) 移开文字:
|
1
2
3
4
|
<h1><span>Image Replacement</span></h1>h1{ background:url(hello_world.gif) no-repeat; width: 150px; height: 35px; }span { display: none; } |
注意问题:①结构性需要增加一个标签包裹文本 ②需要把背景图设置在外标签上,并把文本外标签隐藏.
缺点: 不利于阅览器浏览网页
3) text-indent属性,并且给其设置一个较大的负值,x达到隐藏文本的效果
|
1
2
3
4
5
6
7
8
|
<h1 class="technique-three">w3cplus</h1>.technique-three { width: 329px; height: 79px; background: url(images/w3cplus-logo.png); text-indent: -9999px;} |
4) 我们此处使用一个透明的gif图片,通过在img标签中的“alt”属性来弥补display:none。这样阅读器之类的就能阅读到所替换的文本是什么

<h1 class="technique-five">
<img src="images/blank.gif" alt="w3cplus" /<
<span>w3cplus</span>
</h1>
.technique-five {
width: 329px;
height: 79px;
background: url(images/w3cplus-logo.png);
}
.technique-five span {
display: none;
}
5) 使用零高度来隐藏文本,但为了显示背景图片,需要设置一个与替换图片一样的大小的padding值
|
1
2
3
4
5
6
7
8
9
10
|
<h1 class="technique-six">w3cplus</h1>.technique-six { width: 329px; padding: 79px 0 0 0; height: 0px; font-size: 0; background: url(images/w3cplus-logo.png); overflow: hidden;} |
6) 通过把span的大小都设置为“0”,来达到隐藏文本效果,这样阅读器就能完全阅读到,而且又达到了图片替换文本的效果
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
<h1 class="technique-seven"> <span>w3cplus</span></h1>.technique-seven { width: 329px; height: 79px; background: url(images/w3cplus-logo.png);}.technique-seven span { display: block; width: 0; height: 0; font-size: 0; overflow: hidden;} |
7) 利用一个空白的span标签来放置背景图片,并对其进行绝对定位,使用覆盖文本,达到隐藏替换文本的效果。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
<h1 class="technique-eight"> <span></span>w3cplus</h1>.technique-eight { width: 329px; height: 79px; position: relative;}.technique-eight span { background: url(images/w3cplus-logo.png); position: absolute; width: 100%; height: 100%;} |
8) 设置字体为微小值,但这里需要注意一点不能忘了设置字体色和替换图片色一样,不然会有一个小点显示出来
|
1
2
3
4
5
6
7
8
9
|
<h1 class="technique-nine">w3cplus</h1>.technique-nine { width: 329px; height: 79px; background: url(images/w3cplus-logo.png); font-size: 1px; color: white;} |
9) 使用css的clip属性来实现图片替换文本的效果
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
<h1 class="technique-ten"><span>w3cplus</span></h1>.technique-ten { width: 329px; height: 79px; background: url(images/w3cplus-logo.png);} .technique-ten span { border: 0 !important; clip: rect(1px 1px 1px 1px); clip: rect(1px,1px,1px,1px); height: 1px !important; margin: -1px; overflow: hidden; padding: 0 !important; position: absolute !important; width: 1px;} |
参考自: 十种图片替换文本CSS方法
|
1
2
3
4
5
6
7
8
9
10
|
<!--[if !IE]><!--> 除IE外都可识别 <!--<![endif]--><!--[if IE]> 所有的IE可识别 <![endif]--><!--[if IE 6]> 仅IE6可识别 <![endif]--><!--[if lt IE 6]> IE6以及IE6以下版本可识别 <![endif]--><!--[if gte IE 6]> IE6以及IE6以上版本可识别 <![endif]--><!--[if IE 7]> 仅IE7可识别 <![endif]--><!--[if lt IE 7]> IE7以及IE7以下版本可识别 <![endif]--><!--[if gte IE 7]> IE7以及IE7以上版本可识别 <![endif]--><!--[if IE 8]> 仅IE8可识别 <![endif]--><!--[if IE 9]> 仅IE9可识别 <![endif]--> |
答: 功能限制的浏览器, 比如低版本IE, 手机浏览器, 等会在很多功能上不符合Web标准, 而应对方式主要有:
参考自: 如何为有功能限制的浏览器提供网页
答:
1)reset。参照下题“描述下 “reset” CSS 文件的作用和使用它的好处”的答案。
2)规范命名。尤其对于没有语义化的html标签,例如div,所赋予的class值要特别注意。
2)抽取可重用的部件,注意层叠样式表的“优先级”。
针对打印机的样式: @media print{...}
参考:如何优化网页的打印样式? 移动端H5知识普及 - CSS3媒体查询
答: 优点:
参考: 再谈 CSS 预处理器
作者:张靖超链接:https://www.zhihu.com/question/24959507/answer/29672263来源:知乎著作权归作者所有,转载请联系作者获得授权。
body.ready #wrapper > .lol233答:
盒模型:文档中的每个元素被描绘为矩形盒子,渲染引擎的目的就是判定大小,属性——比如它的颜色、背景、边框方面——及这些盒子的位置。
在CSS中,这些矩形盒子用标准盒模型来描述。这个模型描述了一个元素所占用的空间。每一个盒子有四条边界:外边距边界margin edge,边框边界border edge,内边距边界padding edge和内容边界content edge。
内容区域是真正包含元素内容的区域,位于内容边界的内部,它的大小为内容宽度或content-box宽及内容高度或content-box高。如果box-sizing为默认值,width、min-width、max-width、height、min-height和max-height控制内容大小。
内边距区域padding area用内容可能的边框之间的空白区域扩展内容区域。通常有背景——颜色或图片(不透明图片盖住背景颜色)。
边框区域扩展了内边距区域。它位于边框边界内部,大小为border-box宽和border-box高。
外边距区域margin area用空白区域扩展边框区域,以分开相邻的元素。它的大小为margin-box的高宽。
在外边距合并的情况下,由于盒之间共享外边距,外边距不容易弄清楚。
对于非替换的行内元素来说,尽管内容周围存在内边距与边框,但其占用空间(行高)由line-height属性决定。
盒子模型分为两类:W3C标准盒子模型和IE盒子模型 (微软确实不喜欢服从他家的标准)
这两者的关键差别就在于:
我们在编写页面代码的时候应该尽量使用标准的W3C盒子模型(需要在页面中声明DOCTYPE类型)。
各浏览器盒模型的组成结构是一致的,区别只是在"怪异模式"下宽度和高度的计算方式,而“标准模式”下则没有区别。组成结构以宽度为例:总宽度=marginLeft+borderLeft+paddingLeft+contentWidth+paddingRight+borderRight+marginRight(W3C标准盒子模型)。页面在“怪异模式”下,css中为元素的width和height设置的值在标准浏览器和ie系列(ie9除外)里的代表的含义是不同的(IE盒子模型)。
因而解决兼容型为题最简洁和值得推荐的方式是:下述的第一条。
参考: 解释一下你对盒模型的理解,以及如何在 CSS 中告诉浏览器使用不同的盒模型来渲染你的布局。
reset.css能够重置浏览器的默认属性。不同的浏览器具有不同的样式,重置能够使其统一。比如说ie浏览器和FF浏览器下button显示不同,通过reset能够统一样式,显示相同的效果。但是很多reset是没必要的,多写了会增加浏览器在渲染页面的负担。
比如说,
1)我们不应该对行内元素设置无效的属性,对span设置width和height,margin都不会生效的。
2)对于absolute和fixed定位的固定尺寸(设置了width和height属性),如果设置了top和left属性,那么bottom和right,margin和float就没有作用。
3)后面设置的属性将会覆盖前面重复设置的属性。
说到 IE 的 bug,在 IE6以前的版本中,IE对盒模型的解析出现一些问题,跟其它浏览器不同,将 border 与 padding 都包含在 width 之内。而另外一些浏览器则与它相反,是不包括border和padding的。对于IE浏览器,当我们设置 box-sizing: content-box; 时,浏览器对盒模型的解释遵从我们之前认识到的 W3C 标准,当它定义width和height时,它的宽度不包括border和padding;对于非IE浏览器,当我们设置box-sizing: border-box; 时,浏览器对盒模型的解释与 IE6之前的版本相同,当它定义width和height时,border和padding则是被包含在宽高之内的。内容的宽和高可以通过定义的“width”和 “height”减去相应方向的“padding”和“border”的宽度得到。内容的宽和高必须保证不能为负,必要时将自动增大该元素border box的尺寸以使其内容的宽或高最小为0。
使用 * { box-sizing: border-box; }能够统一IE和非IE浏览器之间的差异。
答:
CSS3的动画
JavaScript的动画
结论
答:
通过媒体查询可以为不同大小和尺寸的媒体定义不同的css,适合相应的设备显示;即响应式布局
参考自: CSS3媒体查询 使用 CSS 媒体查询创建响应式网站 《响应式Web设计实践》学习笔记
答:
display:none或者visibility:hidden,overflow:hidden。
一般来讲,越详细的级别越高。CSS优先级包含四个级别(文内选择符,ID选择符,Class选择符,元素选择符)以及各级别出现的次数。根据这四个级别出现的次数计算得到CSS的优先级
参考: CSS样式选择器优先级
答:
答: BFC指的是Block Formatting Context, 它提供了一个环境, html元素在这个环境中按照一定规则进行布局. 一个环境中的元素不会影响到其他环境中的布局. 决定了元素如何对其内容进行定位, 以及和其他元素的关系和相互作用.
其中: FC(Formatting Context): 指的是页面中的一个渲染区域, 并且拥有一套渲染规则, 它决定了其子元素如何定位, 以及与其他元素的相互关系和作用.
BFC: 块级格式化上下文, 指的是一个独立的块级渲染区域, 只有block-level box参与, 该区域拥有一套渲染规则来约束块级盒子的布局, 且与区域外部无关.
参考: 我对BFC的理解 CSS BFC和IE Haslayout介绍
答:
参考自: 猿教程
答:
参考自: 理解HTML语义化
答:
答:
答:
答: 采用统一编码utf-8模式
参考自: 多语言的网站怎么做呀 多语言网站设计需要注意的问题
为前端开发者提供自定义的属性,这些属性集可以通过对象的dataset属性获取,不支持该属性的浏览器可以通过 getAttribute方法获取
<div data-author="david" data-time="2011-06-20" data-comment-num="10">...</div>
div.dataset.commentNum; // 可通过js获取 10
答:
1)Web Storage API
2)基于位置服务LBS
3)无插件播放音频视频
4)调用相机和GPU图像处理单元等硬件设备
5)拖拽和Form API
答:
 View Code
View Code答:
答:
答:
参考: 《JavaScript》高级程序设计第21章:Ajax和Comet
参考自: 区别和详解:js中call()和apply()的用法
new操作符创建对象:这种行为就像把原函数当成构造器。提供的 this 值被忽略,同时调用时的参数被提供给模拟函数。 答: 事件委托利用了事件冒泡, 只指定一个事件处理程序, 就可以管理某一类型的所有事件.
例:
html部分: 要点击li弹出其id
<ul id="list">
<li id="li-1">Li 2</li>
<li id="li-2">Li 3</li>
<li id="li-3">Li 4</li>
<li id="li-4">Li 5</li>
<li id="li-5">Li 6</li>
<li id="li-6">Li 7</li>
</ul>
//js部分
document.getElementById("list").addHandler("click", function(e){ var e = e || window.event; var target = e.target || e.srcElement; if(target.nodeName.toUpperCase == "LI"){ console.log("List item", e,target.id, "was clicked!"); } });
答:
this 在 JavaScript 中主要由以下五种使用场景。
参考:js怎么实现继承?
答: AMD是依赖提前加载,CMD是依赖延时加载
答: 哈希表(Hash table,也叫散列表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
使用哈希查找有两个步骤:
元素特征转变为数组下标的方法就是散列法。散列法当然不止一种,下面列出三种比较常用的:
1,除法散列法
最直观的一种,上图使用的就是这种散列法,公式:
index = value % 16
学过汇编的都知道,求模数其实是通过一个除法运算得到的,所以叫“除法散列法”。
2,平方散列法
求index是非常频繁的操作,而乘法的运算要比除法来得省时(对现在的CPU来说,估计我们感觉不出来),所以我们考虑把除法换成乘法和一个位移操作。公式:
index = (value * value) >> 28 (右移,除以2^28。记法:左移变大,是乘。右移变小,是除。)
如果数值分配比较均匀的话这种方法能得到不错的结果,但我上面画的那个图的各个元素的值算出来的index都是0——非常失败。也许你还有个问题,value如果很大,value * value不会溢出吗?答案是会的,但我们这个乘法不关心溢出,因为我们根本不是为了获取相乘结果,而是为了获取index。
3,斐波那契(Fibonacci)散列法
解决冲突的方法:
1. 拉链法
将大小为M 的数组的每一个元素指向一个条链表,链表中的每一个节点都存储散列值为该索引的键值对,这就是拉链法.
对采用拉链法的哈希实现的查找分为两步,首先是根据散列值找到等一应的链表,然后沿着链表顺序找到相应的键。
2. 线性探测法:
使用数组中的空位解决碰撞冲突
参考: 哈希表的工作原理 浅谈算法和数据结构: 十一 哈希表
答:
参考自: js闭包的用途
参考: 伪数组
(1) 作为函数的参数,表示该函数的参数不是对象。
(2) 作为对象原型链的终点。
(1)变量被声明了,但没有赋值时,就等于undefined。
(2) 调用函数时,应该提供的参数没有提供,该参数等于undefined。
(3)对象没有赋值的属性,该属性的值为undefined。
(4)函数没有返回值时,默认返回undefined。
从目标元素开始,往顶层元素传播。途中如果有节点绑定了相应的事件处理函数,这些函数都会被一次触发。如果想阻止事件起泡,可以使用e.stopPropagation()(Firefox)或者e.cancelBubble=true(IE)来组织事件的冒泡传播。
答:
而函数定义(语句以function关键字开始)是不能被立即执行的,这无疑会导致语法的错误(SyntaxError)。当函数定义代码段包裹在括号内,使解析器可以将之识别为函数表达式,然后调用。IIFE: (function foo(){})()
区分 (function(){})(); 和 (function(){}()); 其实两者实现效果一样。
函数字面量:首先声明一个函数对象,然后执行它。(function () { alert(1); })();
优先表达式:由于Javascript执行表达式是从圆括号里面到外面,所以可以用圆括号强制执行声明的函数。(function () { alert(2); }());
答:
DOM元素的attribute和property两者是不同的东西。attribute翻译为“特性”,property翻译为“属性”。
attribute是一个特性节点,每个DOM元素都有一个对应的attributes属性来存放所有的attribute节点,attributes是一个类数组的容器,说得准确点就是NameNodeMap,不继承于Array.prototype,不能直接调用Array的方法。attributes的每个数字索引以名值对(name=”value”)的形式存放了一个attribute节点。<div class="box" id="box" gameid="880">hello</div>
property就是一个属性,如果把DOM元素看成是一个普通的Object对象,那么property就是一个以名值对(name=”value”)的形式存放在Object中的属性。要添加和删除property和普通的对象类似。
很多attribute节点还有一个相对应的property属性,比如上面的div元素的id和class既是attribute,也有对应的property,不管使用哪种方法都可以访问和修改。
总之,attribute节点都是在HTML代码中可见的,而property只是一个普通的名值对属性。
答:
在所有的函数 (或者所有最外层函数) 的开始处加入 "use strict"; 指令启动严格模式。
"严格模式"有两种调用方法
1)将"use strict"放在脚本文件的第一行,则整个脚本都将以"严格模式"运行。如果这行语句不在第一行,则无效,整个脚本以"正常模式"运行。如果不同模式的代码文件合并成一个文件,这一点需要特别注意。
2)将整个脚本文件放在一个立即执行的匿名函数之中。
好处
- 消除Javascript语法的一些不合理、不严谨之处,减少一些怪异行为;
- 消除代码运行的一些不安全之处,保证代码运行的安全;
- 提高编译器效率,增加运行速度;
- 为未来新版本的Javascript做好铺垫。
坏处
同样的代码,在"严格模式"中,可能会有不一样的运行结果;一些在"正常模式"下可以运行的语句,在"严格模式"下将不能运行
答: 核心( ECMAScript) , 文档对象模型(DOM), 浏览器对象模型(BOM)
答: DOM是针对HTML和XML文档的一个API(应用程序编程接口). DOM描绘了一个层次化的节点树, 允许开发人员添加, 移除和修改页面的某一部分.
参考: HTML DOM 方法
答: Undefined, Null, Boolean, Number, String
Object是复杂数据类型, 其本质是由一组无序的名值对组成的.
答:
参考: 《JavaScript高级程序设计》
js是一门具有自动垃圾回收机制的编程语言,开发人员不必关心内存分配和回收问题
答: try-catch 和with延长作用域. 因为他们都会创建一个新的变量对象.
这两个语句都会在作用域链的前端添加一个变量对象. 对with语句来说, 会将指定的对象添加到作用域链中. 对catch语句来说, 会创建一个新的变量对象, 其中包含的是被抛出的错误对象的声明.
function buildUrl(){
var qs = "?debug=true";
//with接收location对象, 因此其变量对象中就包含了location对象的所有属性和方法, 而这个变量对象被添加到了作用域链的前端
with(location){
//这里的href其实是location.href. 创建了一个名为url的变量, 就成了函数执行环境的一部分
var url = href + qs;
}
return url;
}
参考: js try、catch、finally语句还有with语句 JavaScript 开发进阶:理解 JavaScript 作用域和作用域链
答:
答: 捕获->处于目标->冒泡,IE应该是只有冒泡没有捕获。
事件代理就是在父元素上绑定事件来处理,通过event对象的target来定位。
答: 用定时器 setTimeout和setInterval
答:
transition-delaytransition-durationtransition-propertytransition-timing-function,对应动画的4种属性: 延迟、持续时间、对应css属性和缓动函数,transform 包含7种属性:animation-nameanimation-durationanimation-timing-functionanimation-delayanimation-directionanimation-iteration-countanimation-fill-modeanimation-play-state,它们可以定义动画名称,持续时间,缓动函数,动画延迟,动画方向,重复次数,填充模式。
参考自: 前端动画效果实现的简单比较
答: 封装, 继承, 多态
答: hasOwnPrototype
答:
1) 箭头操作符 inputs=>outputs: 操作符左边是输入的参数,而右边则是进行的操作以及返回的值
2) 支持类, 引入了class关键字. ES6提供的类实际上就是JS原型模式的包装
3) 增强的对象字面量.
1. 可以在对象字面量中定义原型 __proto__: xxx //设置其原型为xxx,相当于继承xxx
2. 定义方法可以不用function关键字
3. 直接调用父类方法
4) 字符串模板: ES6中允许使用反引号 ` 来创建字符串,此种方法创建的字符串里面可以包含由美元符号加花括号包裹的变量${vraible}。
5) 自动解析数组或对象中的值。比如若一个函数要返回多个值,常规的做法是返回一个对象,将每个值做为这个对象的属性返回。但在ES6中,利用解构这一特性,可以直接返回一个数组,然后数组中的值会自动被解析到对应接收该值的变量中。
6) 默认参数值: 现在可以在定义函数的时候指定参数的默认值了,而不用像以前那样通过逻辑或操作符来达到目的了。
7) 不定参数是在函数中使用命名参数同时接收不定数量的未命名参数。在以前的JavaScript代码中我们可以通过arguments变量来达到这一目的。不定参数的格式是三个句点后跟代表所有不定参数的变量名。比如下面这个例子中,…x代表了所有传入add函数的参数。
8) 拓展参数则是另一种形式的语法糖,它允许传递数组或者类数组直接做为函数的参数而不用通过apply。
9) let和const关键字: 可以把let看成var,只是它定义的变量被限定在了特定范围内才能使用,而离开这个范围则无效。const则很直观,用来定义常量,即无法被更改值的变量。
10) for of值遍历 每次循环它提供的不是序号而是值。
11) iterator, generator
12) 模块
13) Map, Set, WeakMap, WeakSet
14) Proxy可以监听对象身上发生了什么事情,并在这些事情发生后执行一些相应的操作。一下子让我们对一个对象有了很强的追踪能力,同时在数据绑定方面也很有用处。
15) Symbols Symbol 通过调用symbol函数产生,它接收一个可选的名字参数,该函数返回的symbol是唯一的。之后就可以用这个返回值做为对象的键了。Symbol还可以用来创建私有属性,外部无法直接访问由symbol做为键的属性值。
16) Math, Number, String, Object的新API
17) Promises是处理异步操作的一种模式
参考: ES6新特性概览
答: getElementById() getElementsByTagName()
节点遍历: 先序遍历DOM树的5种方法
答: 可以自定义一个函数
|
1
2
3
4
5
6
7
8
|
.border-radius(@values) { -webkit-border-radius: @values; -moz-border-radius: @values; border-radius: @values;}div { .border-radius(10px);} |
答:
答:
我在回答这个题的时候说是两个事件, 先执行捕获的后执行冒泡的. 其实是不对的.
绑定在目标元素上的事件是按照绑定的顺序执行的!!!!
即: 绑定在被点击元素的事件是按照代码顺序发生,其他元素通过冒泡或者捕获“感知”的事件,按照W3C的标准,先发生捕获事件,后发生冒泡事件。所有事件的顺序是:其他元素捕获阶段事件 -> 本元素代码顺序事件 -> 其他元素冒泡阶段事件 。
参考: JavaScript-父子dom同时绑定两个点击事件,一个用捕获,一个用冒泡时执行顺序
答:
块级作用域引入了两种新的声明形式,可以用它们定义一个只存在于某个语句块中的变量或常量.这两种新的声明关键字为:
let: 语法上非常类似于var, 但定义的变量只存在于当前的语句块中const: 和let类似,但声明的是一个只读的常量使用let代替var可以更容易的定义一个只在某个语句块中存在的局部变量,而不用担心它和函数体中其他部分的同名变量有冲突.在let语句内部用var声明的变量和在let语句外部用var声明的变量没什么差别,它们都拥有函数作用域,而不是块级作用域.
答:
1. 直接调用function,每一个类的实例都会拷贝这个函数,弊端就是浪费内存(如上)。prototype方式定义的方式,函数不会拷贝到每一个实例中,所有的实例共享prototype中的定义,节省了内存。
2. 但是如果prototype的属性是对象的话,所有实例也会共享一个对象(这里问的是函数应该不会出现这个情况),如果其中一个实例改变了对象的值,则所有实例的值都会被改变。同理的话,如果使用prototype调用的函数,一旦改变,所有实例的方法都会改变。——不可以对实例使用prototype属性,只能对类和函数用。
答:
因为js中数据类型分为基本数据类型(number, string, boolean, null, undefined)和引用类型值(对象, 数组, 函数). 这两类对象在复制克隆的时候是有很大区别的. 原始类型存储的是对象的实际数据, 而对象类型存储的是对象的引用地址(对象的实际内容单独存放, 为了减少数据开销通常放在内存中). 此外, 对象的原型也是引用对象, 它把原型的属性和方法放在内存中, 通过原型链的方式来指向这个内存地址.
于是克隆也会分为两类:
深度克隆实现:
function clone(obj){
if(typeof(obj)== ‘object‘){
var result = obj instanceof Array ? [] : {};
for(var i in obj){
var attr = obj[i];
result[i] = arguments.callee(attr);
}
return result;
} else {
return obj;
}
};
参考: JavaScript深克隆 javascript中对象的深度克隆
1. var obj = {a : 1}; (function (obj) { obj = {a : 2}; })(obj); //问obj怎么变?
答: 外部的obj不变. 因为匿名函数中obj传入参数等于是创建了一个局部变量obj, 里面的obj指向了一个新的对象 . 如果改成(function () { obj = {a : 2}; })(obj); 就会变了
2. var obj = { a:1, func: function() { (function () { a=2; }(); }} ; obj.fun() //a 怎么变? 匿名函数里的this 是什么?
答: obj里的a不会变. 匿名函数里的this指向全局对象window. 这等于是给window加了一个名为a的属性
要改变obj中a的值 , 应当:
(function() { this.a = 2}).call(this);
或者obj中定义func : func: function() { var self = this; (function(){self.a=2;})();}
3. 要实现函数内每隔5秒调用自己这个函数,100次以后停止,怎么办
想到了用闭包, 但是写错了...
一开始是这么写的
|
1
2
3
4
5
6
7
|
//注意!!这种写法是错误的!!! for(var i=0; i<oLis.length; i++){ oLis[i].onclick = function(){ return (function(j){ alert(j); })(i); }} |
但是这样做的话, 点击所有的li都会弹出最后一个序号. 因为每个li对应的onclick事件的函数, 返回的那个函数的参数还是最后的那个i, 并没有改变. 应该是这么写
方法1 :
|
1
2
3
4
5
6
7
|
for(var i=0; i<oLis.length; i++){ oLis[i].onclick = (function(j){ return function(){ alert(j); } })(i);} |
这样的话, 给每个li绑定onclick事件时, 其实绑的是一个立即执行函数, 这个立即执行函数的参数是i, 因为它是立即执行的, 循环时已经把i的值赋给了li的onclick事件, 所以在外部函数里的i改变后并不会影响i的值.
另一种实现方法:(立即执行函数)
|
1
2
3
4
5
6
7
|
for(var i=0; i<oLi.length; i++){ (function(j){ oLi[j].onclick = function(){ alert(j); }; })(i);} |
或者不用闭包
方法2:
var oLi = document.getElementsByTagName(‘li‘);
function func(obj,i){
obj.onclick = function(){
alert (i);
}
}
for(var i = 0; i<oLi.length; i++){
func(oLi[i], i);
}
方法3: 设置属性:
|
1
2
3
4
|
var oLi = document.getElementsByTagName(‘li‘);for(var i=0; i<oLi.length; i++){ oLi[i].setAttribute("onclick", "alert("+i+");");} |
方法4: 设置index保存
|
1
2
3
4
5
6
|
for(var i=0; i<oLi.length; i++){ oLi[i].index = i; oLi[i].onclick = function(){ alert(this.index); }} |
或者也可以用事件代理来做.
方法1. 创建一个新的临时数组来保存数组中已有的元素
|
1
2
3
4
5
6
7
8
9
10
11
12
|
var a = new Array(1,2,2,2,2,5,3,2,9,5,6,3);Array.prototype.unique1 = function(){ var n = []; //一个新的临时数组 for(var i=0; i<this.length; i++){ //如果把当前数组的第i已经保存进了临时数组, 那么跳过 if(n.indexOf(this[i]) == -1){ n.push(this[i]); } } return n;}console.log(a.unique1()); |
方法2. 使用哈希表存储已有的元素
|
1
2
3
4
5
6
7
8
9
10
11
|
Array.prototype.unique2 = function(){ var hash = {}, n = []; //hash 作为哈希表, n为临时数组 for(var i=0; i<this.length; i++){ if(!hash[this[i]]){ //如果hash表中没有当前项 hash[this[i]] = true; //存入hash表 n.push(this[i]); //当前元素push到临时数组中 } } return n;} |
方法3. 使用indexOf判断数组元素第一次出现的位置是否为当前位置
|
1
2
3
4
5
6
7
8
9
10
11
12
|
Array.prototype.unique3 = function(){ var n = [this[0]]; for(var i=1; i<this.length; i++) //从第二项开始遍历 { //如果当前数组元素在数组中出现的第一次的位置不是i //说明是重复元素 if(this.indexOf(this[i]) == i){ n.push(this[i]); } } return n;} |
方法4. 先排序再去重
|
1
2
3
4
5
6
7
8
9
10
|
Array.prototype.unique4 = function(){ this.sort(function(a, b){ return a - b;}); var n = [this[0]]; for(var i=1; i<this.length; i++){ if(this[i] != this[i-1]){ n.push(this[i]); } } return n;} |
第一种方法和第三种方法都使用了indexOf(), 这个函数的执行机制也会遍历数组
第二种方法使用了一个哈希表, 是最快的.
第三种方法也有一个排序的复杂度的计算.
然后做了个测试, 随机生成100万个0-1000的数组结果如下:

第三种方法总是第二种方法的将近两倍, 而第四种方法与数组的范围有关,
如果是0-100的数组
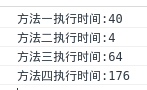
而如果是0-10000, 方法四看着就效果还不错了

而第二种方法永远是最好的, 但是是以空间换时间
全部代码如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
|
var a = [];for(var i=0; i<1000000; i++){ a.push(Math.ceil(Math.random()*10000));}Array.prototype.unique1 = function(){ var n = []; //一个新的临时数组 for(var i=0; i<this.length; i++){ //如果把当前数组的第i已经保存进了临时数组, 那么跳过 if(n.indexOf(this[i]) == -1){ n.push(this[i]); } } return n;}Array.prototype.unique2 = function(){ var hash = {}, n = []; //hash 作为哈希表, n为临时数组 for(var i=0; i<this.length; i++){ if(!hash[this[i]]){ //如果hash表中没有当前项 hash[this[i]] = true; //存入hash表 n.push(this[i]); //当前元素push到临时数组中 } } return n;}Array.prototype.unique3 = function(){ var n = [this[0]]; for(var i=1; i<this.length; i++) //从第二项开始遍历 { //如果当前数组元素在数组中出现的第一次的位置不是i //说明是重复元素 if(this.indexOf(this[i]) == i){ n.push(this[i]); } } return n;}Array.prototype.unique4 = function(){ this.sort(function(a, b){ return a - b;}); var n = [this[0]]; for(var i=1; i<this.length; i++){ if(this[i] != this[i-1]){ n.push(this[i]); } } return n;}var begin1 = new Date();a.unique1();var end1 = new Date();var begin2 = new Date();a.unique2();var end2 = new Date();var begin3 = new Date();a.unique3();var end3 = new Date();var begin4 = new Date();a.unique4();var end4 = new Date();console.log("方法一执行时间:" + (end1 - begin1));console.log("方法二执行时间:" + (end2 - begin2));console.log("方法三执行时间:" + (end3 - begin3));console.log("方法四执行时间:" + (end4 - begin4)); |
原文:https://www.cnblogs.com/onesea/p/13065914.html