/**
*
* 仔细想想已经快一个月没有更新每日一题了。
* 最近这一个月,伴随着返校的事情以及一些其他的事情对算法的认知程度并不是很想思考,导致后期开始逐渐停下了更新的频率与质量。
* 最近几天再写spark的关联规则,以及虚拟机遇到了一些比较奇怪的问题。这些作为今天从头开始的基础我会将代码以及虚拟机ping不通
* 外网的解决办法附在文内。
*
*/
// spark关联规则 代码
package com.swust.nfy.glgz;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function2;
import scala.Tuple2;
import scala.Tuple3;
import java.util.*;
/**
*
* 返回特征之间的关联关系
* @author 雪瞳
* @solgan 时钟尚且前行,人怎能就此止步!
* @return
*
*/
public class FindAssociationRules {
static JavaSparkContext createJavaSparkContext() throws Exception{
SparkConf conf = new SparkConf();
conf.setMaster("local").setAppName("local");
//建立一个快速串行化器
conf.set("spark.seriallizer","org.apache.spark.serializer.KryoSerializer");
//设置缓冲区大小为32M
conf.set("spark.kryoseriallizer.buffer.mb","32");
JavaSparkContext jsc = new JavaSparkContext(conf);
return jsc;
}
static List<String> toList(String transaction){
String line;
String[] items = transaction.trim().split(",");
List<String> list = new ArrayList<>();
for (String item : items){
list.add(item);
}
return list;
}
static List<String> removeOneItem(List<String> list , int i){
if (list == null || list.isEmpty()){
return list;
}
if (i < 0 || i > (list.size() - 1)){
return list;
}
List<String> cloned = new ArrayList<>(list);
//从列表中删除指定元素的第一个出现(如果存在)。 如果此列表不包含该元素,则它将保持不变
cloned.remove(i);
return cloned;
}
public static void main(String[] args) throws Exception {
//处理输入参数
// if (args.length < 1){
// throw new IllegalArgumentException("error!");
// }
// String transactionsFileName = args[0];
String transactionsFileName = "./data/input/in.txt";
JavaSparkContext jsc = createJavaSparkContext();
jsc.setLogLevel("Error");
//从HDFS中读取数据并创建RDD
JavaRDD<String> textFile = jsc.textFile(transactionsFileName, 1);
//生成频繁模式
JavaPairRDD<List<String>, Integer> patterns = textFile.flatMapToPair(line -> {
List<String> list = toList(line);
List<List<String>> combinations = findSortCombinations(list);
List<Tuple2<List<String>, Integer>> result = new ArrayList<>();
for (List<String> combinlist : combinations) {
if (combinlist.size() > 0) {
result.add(new Tuple2<>(combinlist, 1));
}
}
return result.iterator();
});
//组合归约频繁模式
// ( [a,b],2 )
JavaPairRDD<List<String>, Integer> combined = patterns.reduceByKey(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
}
});
//生成所有的子模式
// ([b],([a,b],2))
JavaPairRDD<List<String>, Tuple2<List<String>, Integer>> subpatterns = combined.flatMapToPair(line -> {
List<Tuple2<List<String>, Tuple2<List<String>, Integer>>> result = new ArrayList<>();
List<String> list = line._1();
Integer frequency = line._2();
//自身的子模式频繁度为其本身
Tuple2<List<String>, Integer> theSelf = new Tuple2<>(null, frequency);
result.add(new Tuple2<>(list, theSelf));
// 只有一个元素 就是其本身 没有继续向下挖掘的必要
if (list.size() == 1) {
return result.iterator();
}
for (int i = 0; i < list.size(); i++) {
// 挖掘频繁n-1项集
List<String> sublist = removeOneItem(list, i);
result.add(new Tuple2<>(sublist,
new Tuple2<>(list, frequency)
));
}
return result.iterator();
});
// 组合关联规则
//([b],[([a,b],2),([b,c],2)])
JavaPairRDD<List<String>, Iterable<Tuple2<List<String>, Integer>>> rules = subpatterns.groupByKey();
//生成关联规则
//[([a,b],[d],0.5),([a,b],[c],0.5)]
JavaRDD<List<Tuple3<List<String>, List<String>, Double>>> associationRules = rules.map( line -> {
List<Tuple3<
List<String>, List<String>, Double
>> result = new ArrayList<>();
// 获取子模式
List<String> fromList = line._1();
// 获取子模式所从属的频繁项集
Iterable<Tuple2<List<String>, Integer>> to = line._2();
// 存储所有的包含子模式的频繁项集
List<Tuple2<List<String>, Integer>> toList = new ArrayList<>();
Tuple2<List<String>, Integer> fromCount = null;
for (Tuple2<List<String>, Integer> tuple2 : to) {
//找到count对象
if (tuple2._1() == null) {
//将频繁项集写入fromcount
fromCount = tuple2;
} else {
//将频繁项集下面的子模式写入到toList中
toList.add(tuple2);
}
}
//得到生成关联规则所需的对象
//fromlist fromcount tolist
if (toList.isEmpty()) {
//没有生成输出 由于spark不接受null对象 模拟一个null对象
//如果该子模式是频繁项集本身 则result为null
return result;
}
//创建关联规则
for (Tuple2<List<String>, Integer> tuple2 : toList) {
double confidence = (double) tuple2._2() / (double) fromCount._2();
List<String> tuple2List = new ArrayList<>(tuple2._1());
//移除当前子模式的元素
tuple2List.removeAll(fromList);
result.add(new Tuple3<>(fromList, tuple2List, confidence));
}
return result;
});
associationRules.count();
associationRules.foreach(line ->{
System.out.println(line);
});
}
//Combination规约类 获取所有可能出现的规约项集合
public static
<T extends Comparable<? super T>>
List< List<T>> findSortCombinations(Collection<T> elements , int n){
List<List<T>> result = new ArrayList<>();
if ( n == 0){
result.add( new ArrayList<T>());
return result;
}
// n=1的时候通过遍历list集合 获取单一元素
List<List<T>> combinations = findSortCombinations(elements, n-1);
for ( List<T> combination : combinations){
for (T element :elements){
if (combination.contains(element)){
continue;
}
List<T> list = new ArrayList<>();
list.addAll(combination);
if (list.contains(element)){
continue;
}
list.add(element);
//使用Collections工具类对项排序
Collections.sort(list);
if (result.contains(list)){
continue;
}
result.add(list);
}
}
return result;
}
public static
<T extends Comparable<? super T>>
List< List<T>> findSortCombinations(Collection<T> elements ){
List<List<T>> result = new ArrayList<>();
for (int i=0; i <= elements.size() ;i++){
result.addAll(findSortCombinations(elements,i));
}
return result;
}
}
// 虚拟机pin不通百度
前记:我的问题是比较特殊的 主要是可以xshell连接虚拟机但是却无法ping百度
我查了很多资料 发现网上的大都是互相抄
直接上解决方案:
1.查看主机vmware服务是否开启
右击开始菜单 进入服务管理 查看vm服务是否自动启动
2.查看虚拟网络编辑器
点击net模式 设置好子网ip和网关
3.查看主机vm虚拟网卡 右击属性 设置好对应的ip地址和子网掩码
4.进入虚拟机
vi /etc/sysconfig/network-scripts-ifcfg-eth0
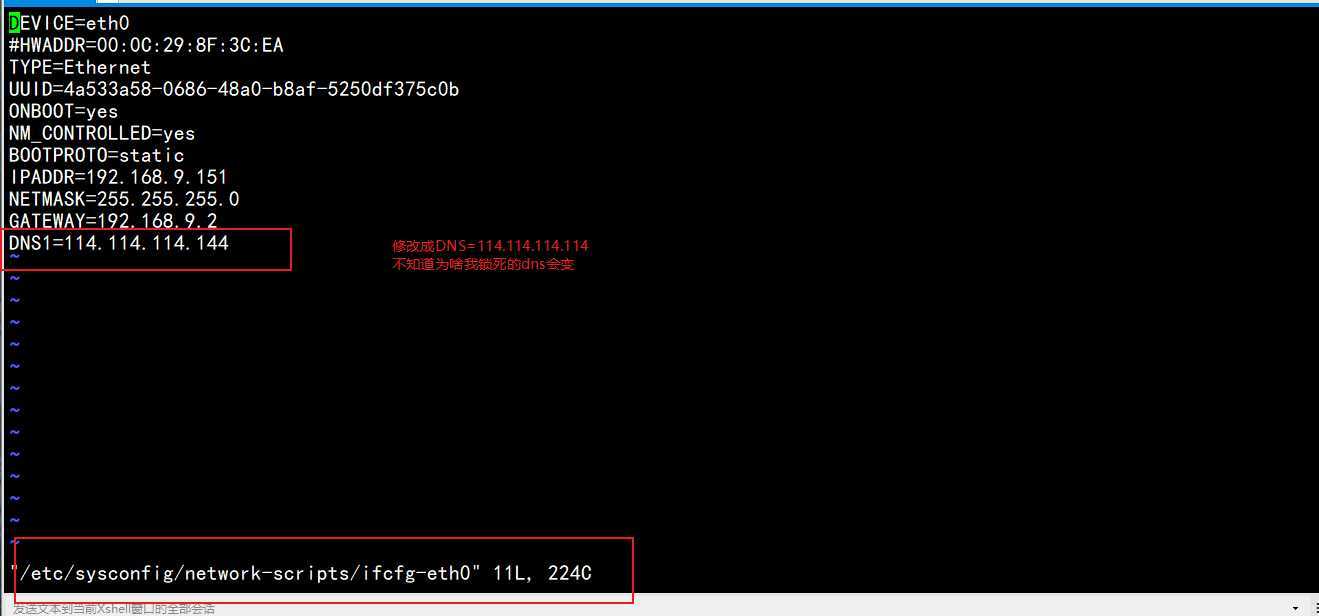
5.service network restart
6.vi /etc/resolv.conf
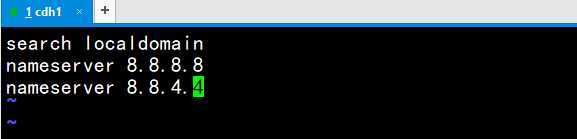
7.成功ping通

原文:https://www.cnblogs.com/walxt/p/13066484.html