分布式协调工具Zookeeper:
Java语言编写开源框架
ZK应用场景:
1.注册中心->一般都是集群版本,consul\eureka\zk\redis高可用
2.分布式配置中心->动态管理配置文件信息
3.消息中间件->事件通知,类似发布订阅功能
4.解决分布式事务->全局协调者
5.分布式锁
6.选举策略(哨兵机制)
7.本地动态负载均衡(Dubbo服务负载均衡原理)->服务注册临时节点,客户端从zk获取父节点,得到服务器信息,本地使用负载均衡算法去访问得到的服务器
8.消息中间件集群管理
存储结构:
以节点方式进行存储,类似XML树状结构(目录结构)
节点路径(节点名称),不能重复,唯一
节点类型:
永久Persistent:创建节点永久的持久化在硬盘上
临时Ephemeral:当前节点和会话连接保持,如果连接断开,那该节点也会被删除(分布式锁原理)
节点事件通知:
每个节点都有事件通知,对该节点发生增删改都会有事件通知。类似于消息中间件
分布式锁:
1.产生原因,因为服务器产生集群
2.在单台服务器上如何生成订单,保证唯一性
UUID+时间戳,集群中无法保证唯一性
大型电商,使用redis,提前生成一定量订单号存放redis中,客户下单就直接取对应订单号就行,redis是单线程的,可以保证唯一性,当redis里面订单快用完的时候,会自动继续补上
3.需要使用锁的客户端在zk上同时去创建临时节点,创建成功则表示获取到锁,使用zk节点路径名称的唯一性,保证已有一个客户端能拿到锁。同时没有获取到锁的其他客户端,都去监听这个节点(可以监听节点的删除和改变),一旦获取到锁的客户端做完操作就删除节点表示释放锁,其他客户端收到消息就会再一起去创建节点,大家一起重新去获取锁。
分布式Session:
分布式Session一致性:
集群服务器Session共享的问题
作用:服务器端与客户端保存整个通讯的会话基本信息
应用场景:登陆流程做法(登陆成功后,获取userId存放session中,下次再获取,就直接从session获取),防表单重复提交
类似于Token也可做到
分布式网站跨域问题:
属于浏览器安全策略问题
一定要端口号和域名保持一致。请求可以访问,但是获取不到结果。
两个项目之间使用ajax实现通讯,如果浏览器访问的域名地址与ajax访问的地址不一致的情况下,默认情况下浏览器会有安全机制致使无法获取到返回,即为跨域问题
解决方案:
1.使用jsonp解决,但是只支持get请求,不支持post.浏览器生成一个随机数,传给服务端,服务端返回时也把随机数返回过来,有点麻烦
2.使用HttpClient进行转发,效率低,会发送两次求情。前端调用自己接口,自己服务端使用httpclient调用目的域名获取返回给前端,发送了两次请求
3.设置响应头允许跨域,setHeader。response.setHeader("Access-Control-Allow-Origin", "*");所有域名都允许跨域,放在过滤器中。小项目快速解决问题
4.使用Nginx搭建API接口网关。A项目里直接调用www.ddd.com/b/***就行了
配置nginx:
server {
listen 80;
server_name www.ddd.com;
###A项目
location /a {
proxy_pass http://a.ddd.com:8080/;
index index.html index.htm;
}
###B项目
location /b {
proxy_pass http://b.ddd.com:8081/;
index index.html index.htm;
}
}
5.使用zuul微服务搭建API接口网关。同nginx,就是在springcloud里新增Zuul服务,配置下网关,然后用zuul访问,微服务通讯不会产生跨域问题
ZK集群选举环境搭建:
为什么:服务器集群保证高并发,注册中心集群为了保证系统高可用,进行服务治理,必须集群,实时的控制服务。服务从注册中心获取到相应服务地址后,把其缓存再jvm缓存一份,并设置个监听,如果节点改变则重新更新
搭建:
安装JDK,因为ZK是Java写的,所以需要jdk环境
配置环境变量
修改profile文件 vi /etc/profile export JAVA_HOME=/usr/local/jdk1.8.0_181 export ZOOKEEPER_HOME=/usr/local/zookeeper export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar export PATH=$JAVA_HOME/bin:$ZOOKEEPER_HOME/bin:$PATH 刷新profile文件 source /etc/profile
安装ZK:
进入目录 cd /usr/local/zookeeper/conf mv zoo_sample.cfg zoo.cfg vi zoo.cfg dataDir=/usr/local/zookeeper/data server.0=192.168.212.154:2888:3888 server.1=192.168.212.156:2888:3888 server.2=192.168.212.157:2888:3888
服务器标识配置:
创建文件夹
mkdir /usr/local/zookeeper/data 创建文件myid并填写内容为0 vi myid (内容为服务器标识 : 0)
再在另外两台服务上搭建ZK
server.1=192.168.212.156:2888:3888
server.2=192.168.212.157:2888:3888
修改相应的myid
springboot需要自己配置ZK版本号,没有集成
分布式任务调度平台:
传统定时任务调度(单点系统)方案:
1、使用Thread方式(线程睡眠时间就是周期,最简单);
2、TimerTask方式(单线程,任务会相互影响,且执行周期任务时依赖系统时间):
timer.scheduleAtFixedRate(new TimerTask() {
@Override
public void run() {...}
}, delay天数, period秒数);
3、ScheduledExecutorService方式(线程池,多线程并发执行,任务互不影响,基于时间的延迟,不会由于系统时间的改变发生执行变化):周期执行和使用Callable延迟执行。
ScheduledExecutorService service = Executors.newSingleThreadScheduledExecutor();
// 第二个参数为首次执行的延时时间,第三个参数为定时执行的间隔时间
service.scheduleAtFixedRate(new Runnable() {
public void run() {...}
}, 1, 1, TimeUnit.SECONDS);
4、使用Quartz:
//实现Job接口,创建任务类
public class MyJob implements Job {
public void execute(JobExecutionContext context) throws JobExecutionException {}}
//1.创建Scheduler的工厂
SchedulerFactory sf = new StdSchedulerFactory();
//2.从工厂中获取调度器实例
Scheduler scheduler = sf.getScheduler();
//3.创建JobDetail
JobDetail jb = JobBuilder.newJob(MyJob.class).........
//4.创建Trigger触发器
Trigger t......
//5.注册任务和定时器
scheduler.scheduleJob(jb, t);
//6.启动 调度器
scheduler.start();
需要使用crontab表达式
定时任务需要考虑高并发,以备在同一时间点执行多个任务:如果定时任务宕机怎么办?使用心跳检测监控自动重启,补偿机制(每个任务打一个小标记),定时任务代码终端突然报错,使用日志记录错误,跳过继续执行。
5.分布式中定时任务,就要保证定时Job幂等性
1.使用ZK实现分布式锁(效率差),要执行就去zk创节点,就避免其他执行了
2.配置文件中加上启动Job的开关,设置一个启动,其他不启动
3.XXL-Job 轻量级分布式任务调度平台
a.支持Job集群,保证幂等,Job负载均衡轮询机制
b.支持Job补偿,失败自动重试,多次失败则发邮件
c.Job日志记录
d.动态配置定时规则
XXL-Job原理:执行器(定时Job实际执行的服务地址)和任务管理(配置任务定时规则、路由策略、运行模式等)
分布式配置中心携程Apollo:
1.特点:
a.吃内存,对外部依赖少
b.基于springBoot和SpringCloud开发,提供Java和.Net原生客户端
c.统一管理不同环境environment、不同集群cluster、不同命名空间namespace的配置
d.配置修改实时生效(热发布,客户端于服务保持长连接),也可灰度发布(点了发布支队部分应用实例生效,没问题后再推给所有实例)
e.版本发布管理,配置发布都有版本概念,支持回滚
f.权限管理、发布审核、操作审计日志
g.客户端可以配置信息监控,看到配饰被那些实例使用
2.原理:
核心模块:ConfigService(服务于Apollo客户端,提供配置获取和推送接口)、AdminService(服务Portal,提供配置管理和修改发布接口)、Client(为应用获取配置,支持实时更新)、Portal(配置管理界面)
辅助服务发现模块:Eureka(ConfigService/AdminService注册实例并定期报心跳,便于Client和Portal发现)、MetaService(Client和Portal用其获取Service服务列表)、MginxLB(软负载路由)
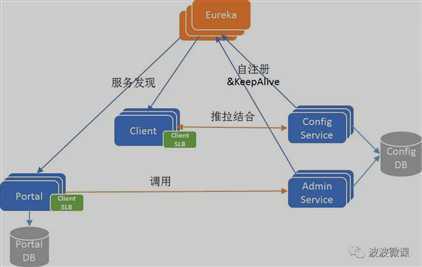
图片来自网络https://github.com/ctripcorp/apollo,侵删
支持.NET:
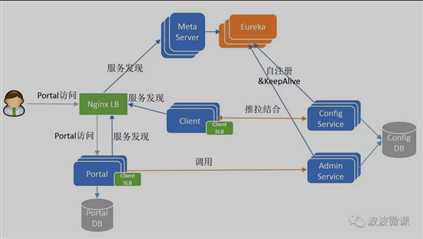
图片来自网络https://github.com/ctripcorp/apollo,侵删
3.快速搭建:
1.安装JDK环境1.8
2.安装Mysql数据库5.7+,创建ApolloPortalDB和ApolloConfigDB数据库
3.编辑demo.sh启动脚本,配置上面新建的两个数据库的连接信息
4.启动脚本demo.sh (service和portal日志文件地址)
4.应用服务器配置:
1.引入jar包,maven库里没有,得自己导入本地maven库。可以使用biuld.bat
2.配置application.yml文件
3.修改环境:修改/opt/settings/server.properties(Mac/Linux)或C:\opt\settings\server.properties(Windows)文件,设置:env=DEV
4.创建apollo-env.properties文件
5.在META-INF文件夹创建app.properties,指定appid
分布式事务:
事务即一个操作序列
产生背景:
传统项目情况下->多数据源,一个项目中,有两个JDBC连接(使用分包或者注解)
微服务项目情况下->每个服务都有自己独立的数据库(数据源),互不影响,即自己的本地事务,当两个服务相互通讯的时候,但是两个本地事务互不影响,就出现分布式事务问题
本地事务的有效范围在同一个JDBC里里面
用户充值,会触发余额增减的抵扣,可能出现事务问题,比如充值在调用余额增减抵扣的时候,已经调用了,但是充值的下一步出问题了,就会发生余额增减抵扣发生,但是充值失败
CAP原理:一致性(分布式系统中所有数据备份在同一时刻具有同样的值,所有节点同一时刻的数据都是最新的数据副本)、可用性(响应性能好,在故障下,服务能在有限的时间内处理完成并进行响应)、分区容忍性(数据必须存放在多节点,以免程序出现节点之间不连通导致分区,分区之间数据无法相互访问,所以服务无法容忍单节点)
总结:要保证分区容忍性,就要把数据复制多个节点,数据要复制存放在多个节点就会带来一致性问题,那为了保证数据一致性,那每次的写操作都要等待所有的节点写成功服务才能使用,那这段时间的服务可能出现可用性问题。三角关系,太极八卦啊
ACID理论:数据库管理系统中事务的四个特性,保证强一致性,即原子性、一致性、隔离性、持久性
BASE理论(是对CAP中一致性和可用性权衡的结果):
基本可用:系统出现不可预知的故障,但是还能用,损失部分可用性,响应时间上的损失,或者功能上的损失,对部分不重要的服务进行降级处理
软状态:允许系统中的数据存在中间状态,并任务改状态不影响系统的整体可用性,即允许系统在多个节点的数据副本存在数据延时
最终一致性:软状态不能一直存在,否则会降低系统的可行性,必须有个时间限制,在期限过后,就要保证所有副本保持数据一致性,达到数据的最终一致性。时间期限取决于网络延时、系统负载、数据复制方案设计等
最终一致性又分为5种类型:因果一致性、读己之所写、会话一致性、单调读一致性、单调写一致性
柔性事务(满足BASE,两阶段型、补偿型、异步确认型、最大努力通知型)与刚性事务(满足ACID)
传统项目解决分布式事务问题:JTA+Atomic
两阶段提交协议:
准备阶段->协调者询问所有参与者是否可以执行提交事务,参与者执行事务但不提交(undo和redo信息写入日志)锁定事务,完成后再相应协调者成功还是失败
提交阶段->a.回滚=协调者收到参与者失败或超时消息,直接向所有参与者节点发出回滚请求,参与者利用写入的undo回滚并向协调者发送回滚完成消息,协调者接受到多有参与者回滚消息,取消事务完成;b.提交=同回滚,协调者发出提交请求,参与者提交并发提交完成消息给协调者,协调者收到所有参与者反馈的成功,完成事务
缺陷:1.执行中,所有参与节点都是事务阻塞型的,会造成同步阻塞问题;2.单点故障,协调者宕机的话,不知道事务现在具体的状态;3.数据不一致,在发送提交请求时,网络故障会导致部分参与节点提交数据,部分没提交;
三阶段提交协议:相比于两阶段,增加了个协调者询问参与者可行性的过程,确保尽可能早的发现无法执行操作而需要终止的行为,但并不能发现所有这种行文,只是减少发生问题的情况。设置超时时间,一旦超过时间,参与者和协调者都默认继续提交事务,默认成功,可能发生不一致问题,但不会发生阻塞和永久锁定资源的问题
原文:https://www.cnblogs.com/shuG214xin/p/13066554.html