使用缓存减轻服务器端的压力,提高访问速度
分类:
单点缓存框架(内置缓存框架,针对单个jvm中,缓存容器放在jvm中,每个jvm互不影响)->ehcache(用java写的,针对java。很多优秀java开源框架,如mybatis\hibernate底层都使用)、guava cache、oscache
分布式缓存框架(共享缓存数据库,跨语言)->Redis、Mencache
缓存一定要做实时的持久化机制,将缓存中的值持久化到硬盘上(日志缓存文件)
缓存三种淘汰算法:
FIFO(First In First Out):先进先出,判断被存储时间,淘汰存最久的;
LRU(Least Recently Used):最近最久未使用,判断最近被使用的时间,目前最远的数据优先被淘汰;
LFU(Least Frequently Used):最不经常使用,一段时间内,数据被使用次数最少,优先淘汰
EhCache:
<!--开启 cache 缓存 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-cache</artifactId>
</dependency>
<!-- ehcache缓存 -->
<dependency>
<groupId>net.sf.ehcache</groupId>
<artifactId>ehcache</artifactId>
<version>2.9.1</version><!--$NO-MVN-MAN-VER$ -->
</dependency>
如何解决缓存与db不同步问题:
发生场景:update、del 先修改,改成功后再主动清缓存
定时JOB健康检查
Ehcache可以使用rmi技术实现集群模式
Redis支持分布式共享查询
缓存击穿(缓存宕机,所有请求都去查数据库)解决方案:使用Redis+Ehcache分布式缓存,分为一、二级缓存,二者同步 ,一级完了调二级
NoSQL->Redis:
以key-value方式进行存储,单线程方式存储->线程安全。可以设置有效期,使用持久化机制保证数据高可用
应用场景:1.令牌生成(临时有效期);2.短信验证码(临时有效期);3.热点数据(减轻查询数据库压力);4.实现分布式中间件(发布订阅,仅仅只是能实现);5.分布式锁(zk和redis都行);6.网站计数器(redis是单线程,高并发时,保证记录全局唯一性)
五种数据类型:String、List、Hash、set、Sorted Set
连接Redis客户端 ./redis-cli -h 127.0.0.1 -p 6379 -a "123" 停止Redis服务 ./redis-cli -h 127.0.0.1 -p 6379 -a "123" shutdown
Redis中有16个库,可以分别使用于不同的业务场景
Redis实现发布订阅:
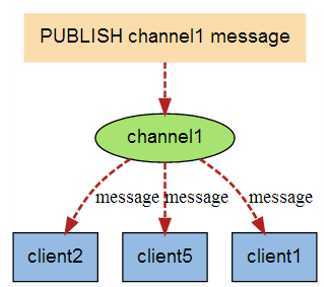
redis 127.0.0.1:6379> SUBSCRIBE redisChat Reading messages... (press Ctrl-C to quit) 1) "subscribe" 2) "redisChat" 3) (integer) 1 PUBLISH redisChat "发布消息"
Redis主从复制:
Redis只允许一主
1:当一个从数据库启动时,会向主数据库发送sync命令
2:主数据库接收到sync命令后会开始在后台保存快照(执行rdb操作),并将保存期间接收到的命令缓存起来
3:当快照完成后,redis会将快照文件和所有缓存的命令发送给从数据库
4:从数据库收到后,会载入快照文件并执行收到的缓存的命令
配置从Redis服务的 .conf文件
slaveof 主Redis服务器IP地址 主Redis端口号 masterauth 主Redis密码
Redis哨兵机制(解决主服务器宕机情况):
心跳检测、管理Redis集群、监控选举策略
配置sentinel.conf文件:
sentinel monitor mymast 主IP 6379 1 #主节点 名称 IP 端口号 选举次数 sentinel auth-pass mymaster 密码 #密码 sentinel down-after-milliseconds mymaster 30 #心跳检测30毫秒 sentinel parallel-syncs mymaster 2 #做多多少合格节点
启动哨兵模式,先把主Redis和备Redis启起来
./redis-server /usr/local/redis/etc/sentinel.conf
集群的条件下,配置:masterauth 主Redis密码 很重要
Redis持久化机制(防止数据丢失):
Redis默认情况下开启RDB
AOF(实时日志记录,记录写操作,效率不高,影响性能,但是安全)
RDB(以二进制文件形式,以某个时间点进行存储,类似定时,非实时,单独线程做写IO操作和当前Redis主进程没任何关联)
Redis事务
stringRedisTemplate.setEnableTransactionSupport(true);
// 开启事务
stringRedisTemplate.multi();
try {
String value = (String) object;
stringRedisTemplate.opsForValue().set(key, value);
} catch (Exception e) {
// 回滚
stringRedisTemplate.discard();
} finally {
// 提交
stringRedisTemplate.exec();
}
缓存就是将数据从读取较慢的介质上读取出来放到读取较快的介质上,如磁盘-->内存
使用Ehcache和Redis做一、二级缓存,Ehcache->Redis->DB
需要注意一级和二级缓存时效问题,因为在DB后,要存放两个缓存,可能会发生二级缓存失效,一级缓存还有效的情况
Redis集群搭建(redis-cluster):
常见Redis集群方案(阿里云版Redis集群比云服务器还贵):
1.客户端分片技术(mycat),没有故障转移功能
2.主从复制。数据很冗余,浪费内存,日志备份
3.使用代理工具转向Redis
4.RedisCluster
Redis3.0版本。redis-cluster,采用了P2P的模式,完全去中心化
Redis 把所有的 Key 分成了 16384 个 slot(0-16383),每个 Redis 实例负责其中一部分 slot 。集群中的所有信息(节点、端口、slot等),都通过节点之间定期的数据交换而更新。
Redis 客户端可以在任意一个 Redis 实例发出请求,如果所需数据不在该实例负责的slot中,通过重定向命令引导客户端访问所需的实例。
key到达的时候,redis会根据crc16算法得出一个结果,然后把结果对 16384 求余数,取模结果一定在16384之内,这样每个 key 都会对应一个编号在 0-16383 之间的哈希槽,通过这个值,去找到对应的插槽所对应的节点(所以集群中的sharding(分片)实际就是如何将16384个值在n个主节点间分配),然后直接自动重定向跳转到这个对应的节点上进行存取操作。
复制源码包src目录下的脚本:
mkreleasehdr.sh redis-benchmark #Redis性能测试工具 redis-check-aof #修复 aof 文件 redis-cli #客户端连接,改了端口,则加 -p 端口号 redis-server #启动,后可加上相应的redis.conf redis-trib.rb #官方提供的Redis Cluster的管理工具,需要准备ruby相关的依赖环境
集群各Redis配置文件redis.conf:
port 9001(每个节点的端口号) daemonize yes (配置后台启动) bind 192.168.119.131(绑定当前机器 IP) dir /usr/local/redis-cluster/9001/data/(数据文件存放位置) pidfile /var/run/redis_9001.pid(pid 9001和port要对应,对应端口号) cluster-enabled yes(启动集群模式) cluster-config-file nodes9001.conf(9001和port要对应) cluster-node-timeout 15000 appendonly yes
ps aux | grep ‘redis‘查看进程
安装 ruby 和相关接口:
yum install ruby yum install rubygems wget http://rubygems.org/downloads/redis-3.2.1.gem gem install redis 使用本地上传方式 安装 gem install -l redis-3.2.1.gem 创建集群create,--replicas指定集群中每个主节点配备1个从节点 redis-trib.rb create --replicas 1 ip:端口号 ip:端口号 ip:端口号 确认是否同意这么配置。输入 yes ,开始集群创建
默认分配好每个主节点和对应从节点服务,以及 solt 的大小,默认平均分配,也可指定增减节点重新分配。
springBoot配置Redis集群,application.yml文件配置:
spring:
redis:
database: 0
# host: ip
# port: 端口号
# password: 123
jedis:
pool:
max-active: 8
max-wait: -1
max-idle: 8
min-idle: 0
timeout: 10000
cluster:
nodes:
- 192.168.212.149:9001
- ip:端口号
- ip:端口号
- ip:端口号
- ip:端口号
- ip:端口号
import org.springframework.data.redis.core.StringRedisTemplate; 。。。 StringRedisTemplate stringRedisTemplate; stringRedisTemplate.opsFor...
Redis生产级集群需要容灾,一般部署为n个主,n*m个从,n大小主要取决于单机性能,m大小主要取决于机器稳定性。
Redis集群是弱一致性的,主要指主从之间的数据一致性,因为Redis在做数据更新时,不要求主从数据同步复制一定要成功。
集群最小的主数量=3,主数量应为奇数,方便做选举。
Redis集群默认不支持事务,但是集群里面的每个节点(卡槽)支持事务
写插件解决:Redis+Lua
缓存雪崩:突然间大量Key失效,数据库压力增大
1.使用分布式锁(本地锁)
2.使用消息中间件 同步方式
3.一、二级缓存
4.均摊分配Redis key的失效时间
3>4>2>1
Redis使用redission实现分布式锁
jvm同时去redis上创建相同的Key,谁创建成功谁就得到锁,删除Key就释放锁,但是没有zk得事件通知功能。给Key设置有效期防止死锁问题
setnx和set,set可以覆盖,返回OK,setnx不会覆盖,有了就不能创建,房会0或1,失败或成功
释放锁:
不能直接删除key,保证释放的是自己创建的锁,避免a创建的锁被b给释放了。使用创建所时传入的value和redis里key存储的值做确认
设置锁的超时时间是为了防止锁一直不释放导致死锁,设置超时时间就会发生在规定超时时间业务逻辑没走完,会有新线程获得锁。
ZK防止死锁,设置Session有效期,连接断开就释放锁了
redis和zk实现分布式锁区别:
在集群环境下,保证只有一个jvm去执行
1.redis是创建setnx唯一k,zk是创建唯一临时节点
2.zk使用直接关闭临时节点session会话连接,因为临时节点生命收起于session会话绑定在一起,session关了锁也就释放了;redis使用value值对比redis服务上的key是本jvm创建,确认后直接删除key节点,就是释放锁了;
3.解决死锁问题:zk是用session会话有效期,redis对key设置有效期
4.性能上redis更好,redis是nosql,存放于内存,zk存放硬盘;可靠性上zk更好,redis拿到了锁才设置有效期,可能会有延迟,zk是先天可控有效期
缓存穿透:客户端生成不同的Key,在redis缓存中没有改数据,数据库中也没有该数据,可能导致一直发生jdbc请求。使用对应的key与数据库中数据不存在
1.网关判断客户端传入对应的key规则,不符合查询规则直接返回空,但是太麻烦,治标不治本
2.使用的key在数据库查询不到,直接在redis中存一为null的结果。在存入相应值进数据库的时候,直接清楚对应缓存,在插入数据库

原文:https://www.cnblogs.com/shuG214xin/p/13066352.html