本文源码:GitHub·点这里 || GitEE·点这里
首先要明确索引是什么:索引是一种数据结构,数据结构是计算机存储、组织数据的方式,是指相互之间存在一种或多种特定关系的数据元素的集合,例如:链表,堆栈,队列,二叉树等等。
其次要清楚索引的作用:索引可以使存储引擎快速找到数据记录,这是最基本的作用,索引是对查询速度最关键的影响,良好的索引设计可以使查询的效率有质的飞越。
索引的使用:如果查询语句使用所有,MySQL会在索引的数据结构上查询,如果查询到,就返回包含该索引的数据行。
索引的种类非常多,如何分类取决多个场景和不同的角度,常见的划分如下:
注意:索引的实现是在存储引擎层面,相同的索引在不同的存储引擎中,其实现方式可能都是不一样的。
普通索引
基本的索引,没有任何使用限制,主要用来加速数据查询。适合经常出现在查询条件或排序条件中的数据列。
主键索引
特殊的唯一索引,不允许有空值,在建表的时候指定主键,就会创建主键索引,MySQL中最核心的索引,大量的业务数据都是基于主键查询。
唯一索引
普通索引类似,不同的就是:索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须是唯一性的。
全文索引
用于全文搜索,通过建立全文索引,基于分词的查询模式,可以极大的提升检索效率。
组合索引
创建的索引覆盖两个或者两个以上的列,适应组合查询的场景,也常用于要素验证的业务,例如判断用户身份ID,手机号,邮箱,是否为同一个用户。
基础用户表
CREATE TABLE user_base (
id INT (11) NOT NULL AUTO_INCREMENT COMMENT ‘主键ID‘,
user_name VARCHAR (20) NOT NULL COMMENT ‘用户名‘,
phone VARCHAR (20) NOT NULL COMMENT ‘手机号‘,
email VARCHAR (32) DEFAULT NULL COMMENT ‘邮箱‘,
card_id VARCHAR (32) DEFAULT NULL COMMENT ‘身份编号‘,
create_time datetime DEFAULT NULL COMMENT ‘创建时间‘,
state INT (1) DEFAULT ‘1‘ COMMENT ‘是否可用,0-不可用,1-可用‘,
PRIMARY KEY (`id`)
) ENGINE = INNODB DEFAULT CHARSET = utf8 COMMENT = ‘用户基础表‘;
创建单列索引
CREATE INDEX card_id_index ON user_base(card_id);
修改添加索引
ALTER TABLE user_base ADD INDEX state_index(state) ;
创建组合索引
CREATE INDEX bind_index ON user_base(phone,card_id);
删除索引
DROP INDEX card_id_index ON user_base ;
修改索引
MySQL不支持真正修改索引的语法规范,可以通过删除旧索引,添加新索引的方式进行操作。
分析MySQL查询,多数情况下用来分析执行语句的SQL中是否使用索引,是否产生临时表等性能相关问题。
基础用法
EXPLAIN SELECT * FROM user_base WHERE id=‘1‘;
参数说明
simple:简单select查询,查询中不包含子查询或者
primary:查询中若包含复杂的子部分,最外层查询则被标记为primary
subquery:select或where中包含子查询
derived:from中包含的子查询被标记为derived衍生,mysql会递归执行这些子查询,且生成临时表
union:第二个select出现在union后,标记为union
union-result:从union表获取结果的select
system-const:对查询的某部分进行优化并转换成一个常量时,会使用该类型
eq_ref:常见于主键或唯一索引扫描,表中只有一条记录与之匹配
ref:非唯一性索引扫描,返回匹配某个单独值的所有行
index:遍历索引结构,索引文件通常比数据文件小
all:遍历全表进行查询
Using-Filesort:查询使用文件排序,最差的执行计划
Using-Temporary:临时表保存中间结果,比文件排序稍微强点
Using-Index:查询操作中使用了覆盖索引
Using-Where:表明使用了where过滤条件
Using-Join-Buffer:表明使用了连接缓存
Impossible-Where:表示where条件false,不能过滤元素
Distinct:优化distinct找到第一匹配的数据后即停止找同样值的动作
Select-Tables-Optimized-Away:不必等到执行阶段再进行计算,查询执行计划生成的阶段即完成优化
MySQL官方比较推荐的索引结构类型,在实际的数据库开发中,基于MySQL中的表结构,大部分使用的都是B-Three索引结构,即二叉树的结构。可以加快数据的访问速度,存储引擎不再需要进行全表扫描来获取数据,数据分布在各个索引节点上,B-Tree索引结构如图:
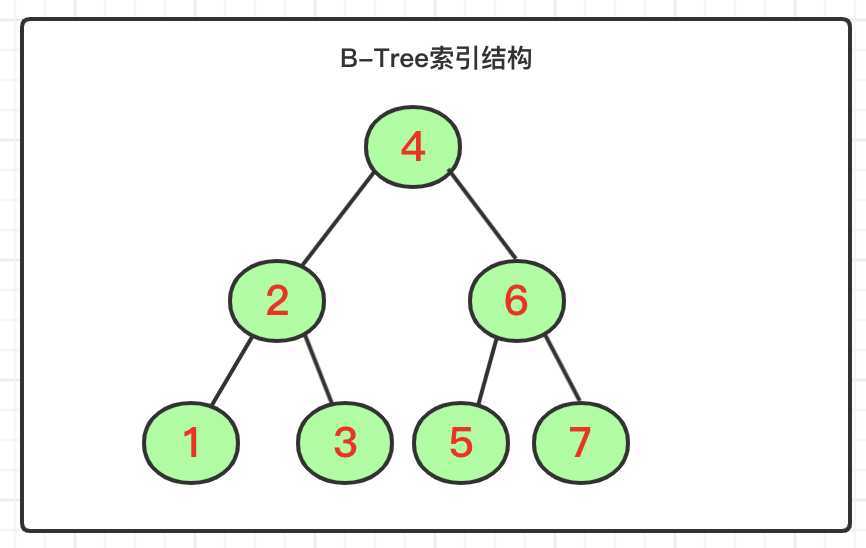
该结构是典型的二叉树结构,特点:数据值按照顺序存储的,每个叶子节点到根部的距离是相同的,注意这里描述的是索引结构图。
实际存储结构上,数据顺序存储,每个节点包含索引值,索引指向的数据行的值,指向子页的指针,指向叶子页的指针,这样才能把索引和数据结构组织起来,结构如图:
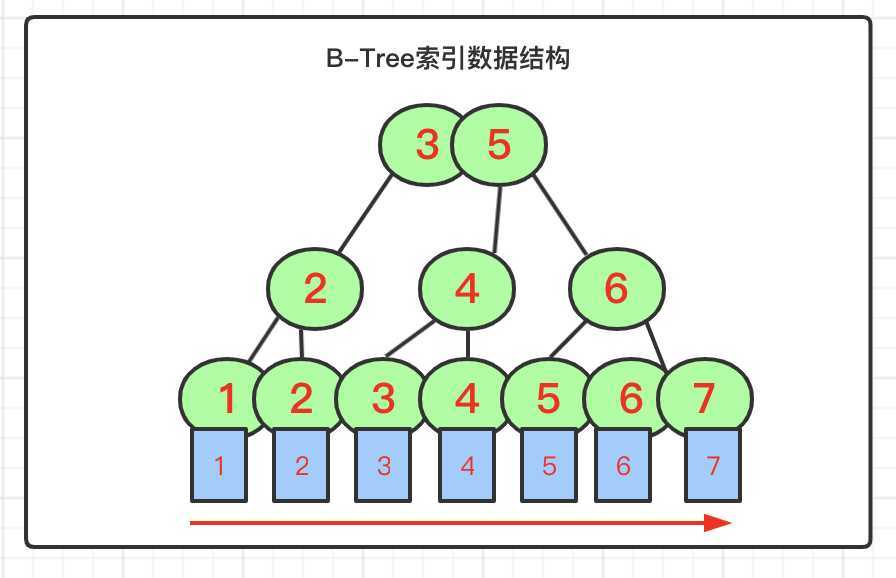
这样完整描述B-Tree索引的数据特点,基于树搜索提升效率,减少扫描数据,数据被顺序的组织起来,按照索引值顺序排列。
索引的根本作用,减少扫描的数据量,提升查询效率,基于B-Tree索引的结构的查询规则基本如下:
注意:必须要强调一点,查询必须是在执行索引的基础上,才是该逻辑,正常的开发中多分析一下查询语句,有时候可能只是自己感觉查询索引是执行的,实际可能是失效的。
好的索引设计十分重要,但是查询的时候很可能因为触发各种索引失效机制,导致SQL语句不执行索引搜索,严重损失性能,所以基于业务下数据查询特点,设计相对好用的索引结构,是十分关键的,这里涉及很多场景问题,后续再详细记录。
索引有时候并不是最好的解决方式,当数据量庞大的时候,索引也会占据庞大的存储空间,这里提供一个业务测试场景,仅供参数:单表三个字符类型字段,两个字段使用索引结构,存储数据在700W量级,在A和B两个数据库,A数据库有索引结构,B数据库没有索引,A库占用的空间是B库的1.6倍,写入千万数据的速度也比B数据库慢9分钟。
这里只想说明一点:索引虽然好,使用妥当才能发挥作用。
GitHub·地址
https://github.com/cicadasmile/mysql-data-base
GitEE·地址
https://gitee.com/cicadasmile/mysql-data-base

推荐阅读:MySQL系列
MySQL进阶篇(02):索引体系划分,B-Tree结构说明
原文:https://www.cnblogs.com/cicada-smile/p/13068677.html