一、背景介绍、现状综述
本文作者在工作中需要实现一种适用于手机端目标检测任务的神经网络,因此撰写这篇综述性报告,详细梳理目前手机端目标检测领域的神经网络应用现状。
1959年,Hubel和Wiesel发现人类视觉系统中的可视皮层是采用分层机制处理信息的。受此启发,人们提出了卷积神经网络(Convolutional Neural Network,简称CNN)的概念[1],并做了大量模拟实验。1994年,Yann LeCun等人开发出一种5层的卷积神经网络(LeNet-5)并成功用于手写数字的识别,这是世界上最早的卷积神经网络之一。在此之后,人们不断开发出一系列新颖的CNN算法模型和应用模型,实现了很高的目标检测精度[1]。
在当前,云计算、大数据、移动互联网已普及,物联网的研究和应用也在不断进步。人们在目标检测的实践中意识到,要实现物联网的“智能”,一种较合理的方式是在云端利用大数据集训练好模型,然后将模型压缩后部署到手机、嵌入式设备等端设备上。由于端设备的计算力有限、应用的实时性要求高,因此这些模型不能占用太多资源,以确保速度快,但是又要保证有较高精度。这就对当前的CNN算法模型和应用模型提出了很高要求。
按照模型结构来分的话,当前的CNN算法模型主要分为二阶段(two-stage)算法模型和一阶段(one-stage)算法模型两类。也有一些算法模型适当综合了两种算法模型的长处。
二阶段算法模型,在第一阶段提取出若干可能包含目标的候选区域(称为region proposals),这样就去除了大量背景信息。在第二阶段使用卷积神经网络对候选目标区域进一步分类。由于此时的候选区域已经较少了,所以分类比较容易,精度比较高。但是由于分为两阶段,所以速度较慢。代表性算法模型有:RCNN,SPP-net,fast-RCNN,faster-RCNN,FPN等。二阶段算法由于实时性不够,一般不适用于手机端目标检测。
一阶段算法,则是把目标分类和检测框回归同时实现,具体做法是利用感受野较大的深度网络直接在原图上对目标区域提取特征,并利用特征对目标的bounding box进行回归。由于不需要预先提取region proposal,因此速度较快。但是由于anchor boxes数量很多,存在所谓的“前景——背景”类别不平衡问题(属于背景的anchor boxes数量上明显超过属于目标物的anchor boxes),导致最后目标检测精度比较低。代表性算法模型有:SSD, YOLO。一阶段算法在保持较高检测精度的同时,很好满足了实时性要求,适用于手机端目标检测。后续将详细介绍SSD、YOLO。
综合性算法结合了前两种算法模型的长处。代表性模型有:RetinaNet。综合性算法在经过工程优化后,也适用于手机端目标检测。后续也将详细介绍RetinaNet。
另外,在具体的应用模型领域,近年来也涌现出越来越多的手机端神经网络,代表模型有:MobileNet、ShuffleNet、SqueezeNet等。在第三部分将展开介绍。
二、适用于手机端目标检测的神经网络算法模型
2.1、SSD(Single Shot MultiBox Detector):
属于一阶段(one-stage)算法模型。是一种前向传播网络。典型架构如下图1所示[2]。SSD采用RPN的特征金字塔思想,利用多个卷积层取得大小不同的feature maps,并在这些feature maps上同时进行分类和回归。具体做法是在不同尺寸的feature map上产生很多bounding boxes(目标预选框,简记为bbox),然后将不同feature map产生的bbox统一送入NMS(非最大抑制)层进行“过滤”,最后针对每种检测物体保留一个最可能的bbox作为目标检测框。SSD算法在速度上比Faster-RCNN快很多,比较适合对实时性要求较高的场景;但其检测精度比Faster-RCNN差,尤其对于小目标的检测精度差很多。这是由于SSD使用VGG-16中的Conv4_3层提取小目标特征,Conv4_3层在架构里位置靠前,输入SSD的图片又做过缩小,导致Conv4_3层相对于原图的感受野较小,而且小目标本身像素信息也少,因而提取到的小目标特征不充分。有很多方法来改进小目标检测[3],一种常见思路是将浅层特征和深层特征进行融合[3]。SSD的思想贡献:采用多尺度特征层融合的方法,可以在保证较高检测精度的同时,有效减少网络的层次,确保模型较小、速度较快。 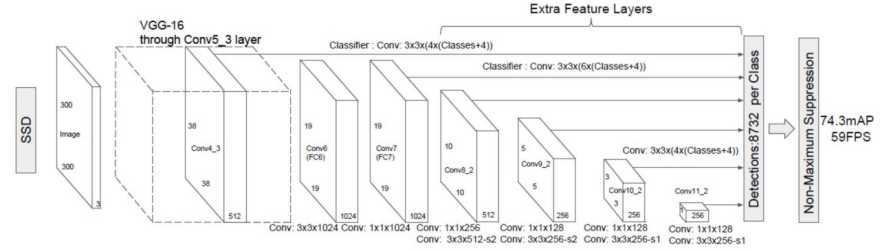
图1——SSD典型架构[2]
SSD的目标检测过程举例如下图2所示[2]。 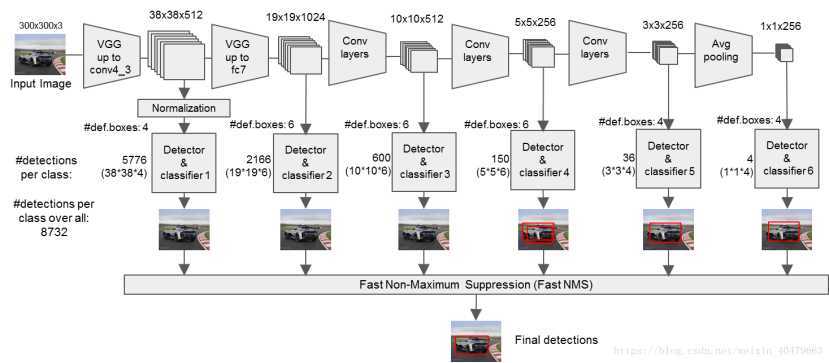
图2——SSD目标检测过程举例[2]
2.2、YOLO(You Only Look Once):
属于一阶段(one-stage)算法模型。自从2016年被提出以来,已经迭代了v1、v2、v3、v4等四个版本。这里以工业界使用较多的YOLOv3为例,简单分析YOLO的主要思想。YOLOv3采用DarkNet-53作为主干网络。典型的DarkNet-53使用了53层卷积层,卷积层包含了一个Conv2d层、一个BatchNorm层、一个改进的LeakyReLU激活函数。DarkNet-53使用了残差结构,以克服梯度消失带来的深度网络性能退化。YOLOv3也借鉴了特征金字塔思想和anchor box目标预选框思想,在3个尺度的feature map上,每个单元格各分配3个不同大小的anchor boxes。3个feature maps进行融合,具体做法是将较深层的feature map进行上采样,以相同的大小和较浅层次的feature map进行特征融合,最后在融合的feature map上进行分类和bounding box回归。一种YOLOv3的结构图如下图3所示[4]。 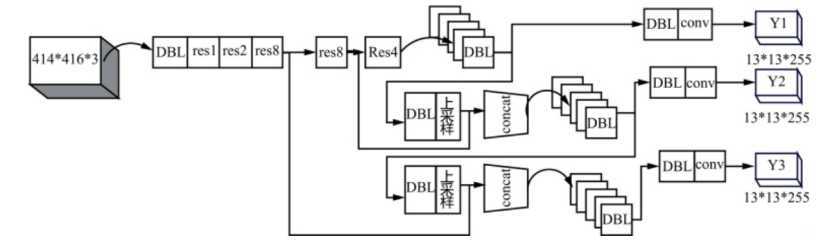
图3——YOLOv3的典型架构[4]
YOLOv3和SSD比较,有很多不同[5]。在主干网络上,典型SSD应用了VGG16,也可以替换为MobileNet等,YOLOv3则使用了DarkNet-53,拥有了更深的网络深度,从而能更有效地提取到包括小目标在内的目标特征,和SSD相比提升了小目标检测精度,同时大量使用残差结构以避免网络退化。YOLOv3和SSD都借鉴了Faster-RCNN的anchor box思想,但具体实现的思路不一样:YOLOv3采用K-mean聚类算法产生anchor box,更为精确,而SSD则是根据一组固定规则手动设置出anchor box。另外,两者在输入图像的resize处理方式上、bounding box的预测方法上、输出分类的函数选择上等方面都有不同的策略[5]。
YOLOv3的主要思想贡献,一是多尺度特征融合,这点和SSD类似;二是为了提高对小目标的检测精度,同时又保持较快的速度,使用了深度适中的残差结构网络DarkNet-53,能提取到更多小目标特征,有效改善了一阶段算法模型对小目标检测精度差的问题;三是对每个目标候选框增加了概率性预测,用于判断其属于“前景”框还是“背景”框[6],可一定程度地优化“前景——背景”类别不平衡问题,提高检测精度;四是YOLOv3、YOLOv4的具体实现包含了很多工程优化的tricks,在工业实践中值得借鉴。
2.3、RetinaNet:
属于综合了一阶段算法和二阶段算法优点的模型。Tsung-Yi Lin等人认为图像中极为不均衡的目标-背景数据分布是导致一阶段算法检测精度低的主要原因[9],即所谓“前景——背景”类别不平衡问题。为了解决该问题,RetinaNet对交叉熵损失函数进行修正,提出了“聚焦损失函数(Focal Loss)”。通过降低网络训练过程中简单背景样本的学习权重,RetinaNet做到了对目标难样本的“聚焦”和对网络学习能力的重新分配[9],从而使一阶段算法模型的检测速度和精度全面超越基于region proposals的二阶段算法模型。
下面简单介绍下Focal Loss的细节。通过在二分类交叉熵前面加入调节因子,可得y=1的交叉熵Loss公式:,其中pt是指模型预测的y=1的概率,γ是一个较大的正数,被称为focusing parameter。由于背景属于较易识别的样本,其对应pt较高,代入公式后Loss值较小;待检测目标是前景,属于难样本,其对应pt较小,对应Loss值较大。通过这种方法,难样本对于Loss值有较大贡献,从而给予了难样本较大的学习权重[7]。
RetinaNet的网络架构如下图4所示[7,8]。首先采用ResNet+FPN对原图提取多尺度特征,并对多尺度feature maps进行融合,得到特征金字塔。然后对金字塔的每一层,都使用两个由RPN改造得来的子网络,分别进行分类和bounding box回归。最后对金字塔各层得到的预测结果进行融合,并使用NMS层进行过滤得到最终结果。刚才解释的Focal Loss方法,位于分类子网络里。 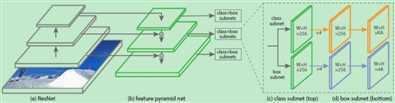
图4——RetinaNet的典型架构[7,8]
RetinaNet的主要思想贡献是:提出了Focal Loss概念,以解决“前景——背景”类别不平衡问题,从而提高检测精度[7,8,9]。
三、适用于手机端目标检测的神经网络应用模型
3.1、MobileNet:
是面向移动端和嵌入式设备的神经网络应用模型。MobileNet采用了分组卷积(Group Convolution)的思路来降低卷积计算量。所谓“分组卷积”,是指将输入图的不同特征图进行分组,然后用不同卷积核对不同分组进行卷积计算,属于一种通道稀疏连接方式[10,11,12,13]。具体讲,MobileNet用深度卷积(depthwise convolution)和逐点卷积(pointwise convolution)的组合来替代标准卷积,以减少计算量。还引入了两个超参数:宽度乘子α和分辨率乘子ρ,分别用于改变通道数和特征图分辨率,便于控制模型大小以减少参数量。所有层都引入BatchNorm和ReLU激活函数。最后一层使用softmax做概率分类[10]。MobileNet的思想贡献:用深度卷积和逐点卷积来代替标准卷积,有效减少计算量。
3.2、ShuffleNet:
和MobileNet类似的地方是,ShuffleNet也使用了分组卷积(Group Convolution)思想,采用的是逐点组卷积(pointwise group convolution)。ShuffleNet还采用了通道混洗(Channel Shuffle)的思路来实现不同特征分组之间的信息交换。具体过程如下图5所示[11]。其实质就是打乱feature分组,使后续的group convolution获得来自不同分组的feature信息。
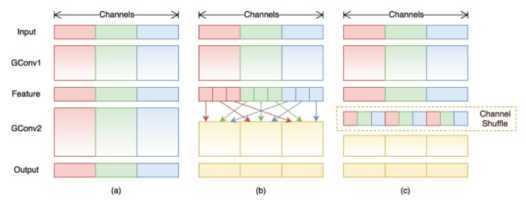
图5——Channel Shuffle示意图[11]
ShuffleNet的本质是一个加入了分组卷积(Group Convolution)和通道混洗(Channel Shuffle)的简化版ResNet。 ShuffleNet继承了ResNet的BottleNeck结构,可更加有效地提取特征信息,同时继承了残差结构,有效防止网络性能退化。
ShuffleNet的思想贡献:一是分组卷积;二是通道混洗。
3.3、SqueezeNet:
SqueezeNet的一个重要特点就是卷积模块化。其基本单元是一种被称为Fire module的模块化卷积单元。Fire模块包含两层卷积计算:一是采用1x1卷积核的squeeze层;二是混合使用1x1和3x3卷积核的expand层[14]。整个SqueezeNet就是使用Fire基本模块堆积而成的,SqueezeNet还借鉴了ResNet的残差结构,引入了“短路”机制。SqueezeNet在所有层都使用ReLU激活函数。
SqueezeNet的另一个重要特点就是对模型的压缩效果较好。其模型压缩采用的技术有SVD分解,网络剪枝(network pruning)和量化(quantization)等。实验结果表明,和二阶段算法应用模型AlexNet相比,accuracy精度性能相当,但是模型缩小了50倍。
SqueezeNet的思想贡献:为手机端神经网络模型的设计提供了一个将卷积模块化和模型压缩很好地结合起来的范例。
四、总结
本文梳理了适用于手机端目标检测的神经网络算法模型和应用模型。在算法模型领域,对端到端的一阶段目标检测算法的研究正在不断深入,一阶段算法正在通过多尺度特征融合、吸收二阶段算法的优点、加入工程优化tricks等方法,不断地得到进步,未来在手机端、物联网终端,改进型的一阶段算法会成为主流。在应用模型领域,围绕着“结构优化”和“模型压缩”两个点展开了研究。在结构优化方面,产生了分组卷积、卷积模块化、残差结构等优化手段,有效降低了计算量、增强了网络鲁棒性;在模型压缩方面,使用SVD分解、网络剪枝、量化等手段,可有效压缩模型大小,提高检测速度。
根据上面的综述信息,结合工作的实际需求,本文作者拟使用MobileNet+SSD的神经网络结构。其中,使用MobileNet替代VGG16来做主干网络。也需要根据实际图片中的目标区域的大小,调整anchor box设置时的默认宽、长。
———————————————————————————————————————
参考文档:
[1] 范丽丽等,基于深度卷积神经网络的目标检测研究综述,《光学 精密工程》,2020年5月第5期第28卷
[2] 技术博客:https://blog.csdn.net/weixin_40479663/article/details/82953959
[3] 王冬丽等,基于特征融合的SSD视觉小目标检测,《计算机工程与应用》网络首发论文,2020年5月12日
[4] 戴舒等,基于YOLO算法的行人检测方法,《无线电通信技术》,2020 46( 3) : 360-365
[5] 技术博客:https://blog.csdn.net/BlowfishKing/article/details/80485006
[6] 曹燕等,基于深度学习的目标检测算法研究综述,《计算机与现代化》,2020年第5期
[7] 知乎专栏:https://zhuanlan.zhihu.com/p/67768433
[8] 技术博客:https://blog.csdn.net/weixin_31866177/article/details/81155826
[9] 技术博客:https://www.csdn.net/gather_2c/MtTaQg5sNjI2MTUtYmxvZwO0O0OO0O0O.html
[10] 薛俊韬等,基于MobileNet的多目标跟踪深度学习算法,《控制与决策》网络首发论文,2020年5月12日
[11] 技术博客:https://www.cnblogs.com/hellcat/p/10318630.html
[12] 知乎专栏:https://zhuanlan.zhihu.com/p/35405071
[13] 技术博客:https://blog.csdn.net/u011974639/article/details/79200559
[14] 知乎专栏:https://zhuanlan.zhihu.com/p/31558773
原文:https://www.cnblogs.com/hillsea/p/13069110.html