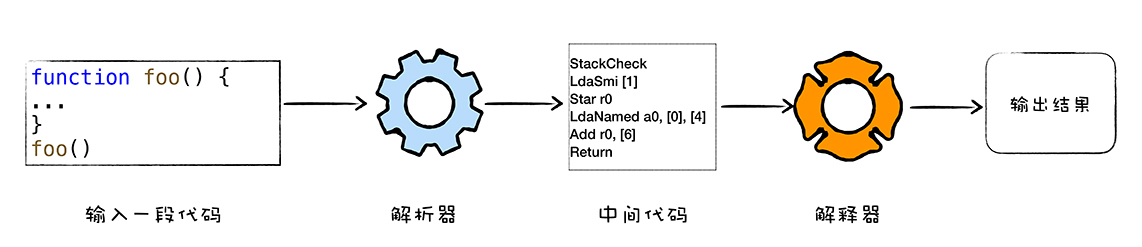
解释执行,需要先将输入的源代码通过解析器编译成中间代码,之后直接使用解释器解释执行中间代码,然后直接输出结果。
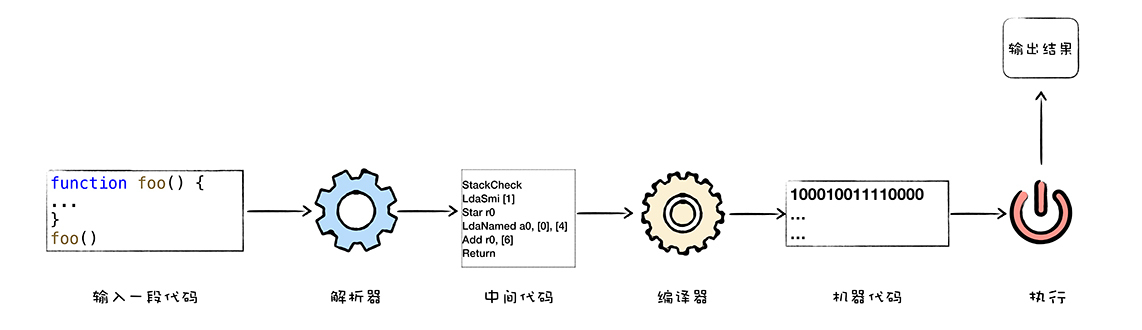
编译执行。采用这种方式时,也需要先将源代码转换为中间代码,然后我们的编译器再将中间代码编译成机器代码。通常编译成的机器代码是以二进制文件形式存储的,需要执行这段程序的时候直接执行二进制文件就可以了。还可以使用虚拟机将编译后的机器代码保存在内存中,然后直接执行内存中的二进制代码。
解释执行的启动速度快,但是执行时的速度慢,而编译执行的启动速度慢,但是执行时的速度快。
V8 并没有采用某种单一的技术,而是混合编译执行和解释执行这两种手段。
我们把这种混合使用编译器和解释器的技术称为 JIT(Just In Time) 技术。
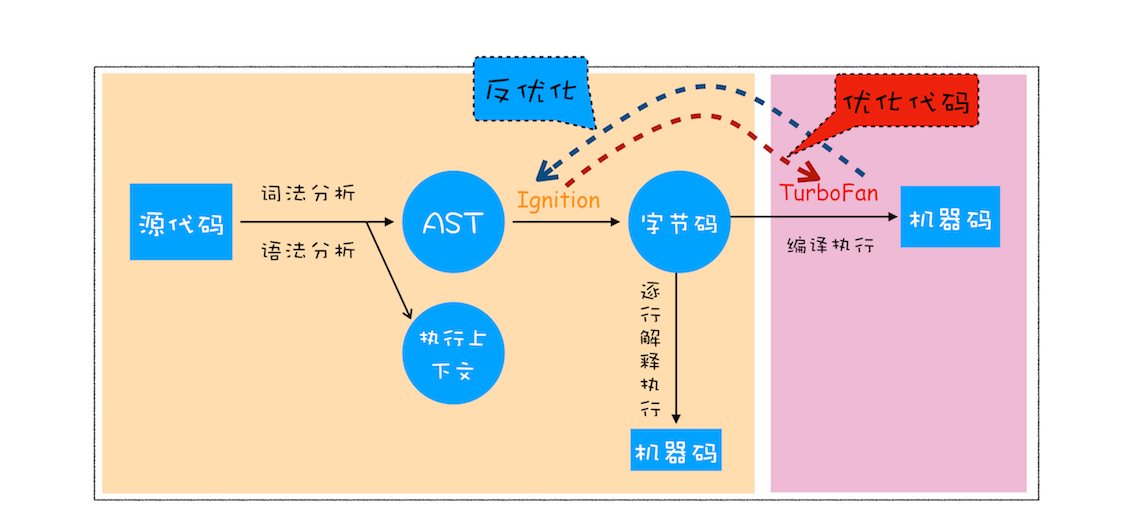
第一阶段是分词(tokenize),又称为词法分析,其作用是将一行行的源码拆解成一个个 token。所谓 token,指的是语法上不可能再分的、最小的单个字符或字符串。
第二阶段是解析(parse),又称为语法分析,其作用是将上一步生成的 token 数据,根据语法规则转为 AST。 如果源码符合语法规则,这一步就会顺利完成。但如果源码存在语法错误,这一步就会终止,并抛出一个“语法错误”。
Babel 的工作原理就是先将 ES6 源码转换为 AST,然后再将 ES6 语法的 AST 转换为 ES5 语法的 AST,最后利用 ES5 的 AST 生成 JavaScript 源代码。
除了 Babel 外,还有 ESLint 也使用 AST。ESLint 是一个用来检查 JavaScript 编写规范的插件,其检测流程也是需要将源码转换为 AST,然后再利用 AST 来检查代码规范化的问题。
其实一开始 V8 并没有字节码,而是直接将 AST 转换为机器码,但是随着 Chrome 在手机上的广泛普及,特别是运行在 512M 内存的手机上,内存占用问题也暴露出来了,因为 V8 需要消耗大量的内存来存放转换后的机器码。为了解决内存占用问题,V8 团队大幅重构了引擎架构,引入字节码,
字节码就是介于 AST 和机器码之间的一种代码。但是与特定类型的机器码无关,字节码需要通过解释器将其转换为机器码后才能执行。

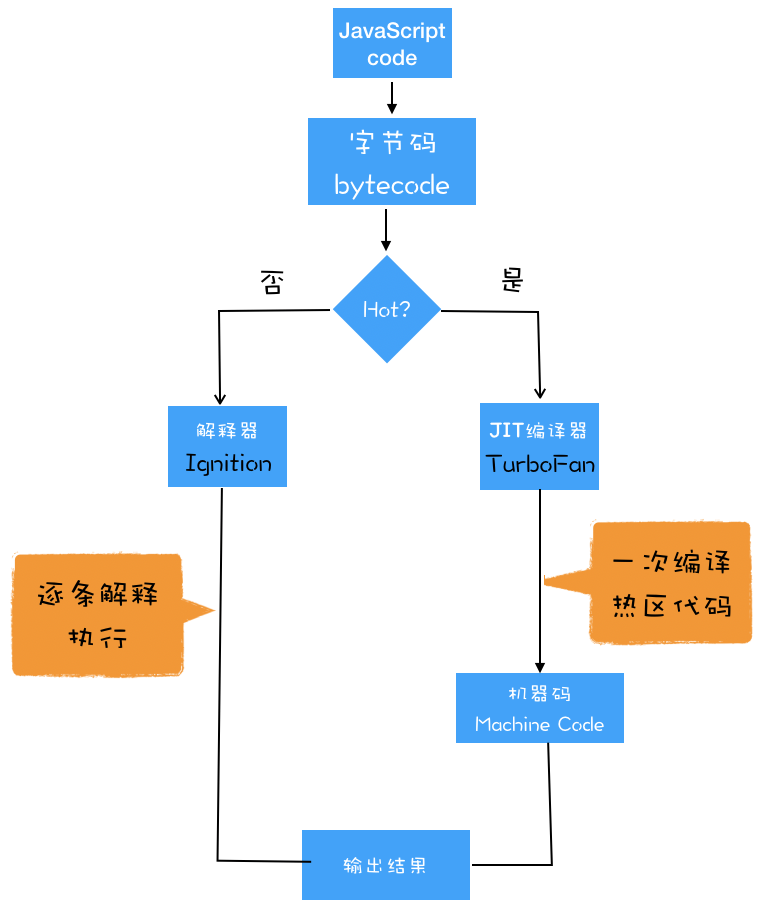
即时编译(JIT)技术。具体到 V8,
就是指解释器 Ignition 在解释执行字节码的同时,收集代码信息,
当它发现某一部分代码变热了之后,
TurboFan 编译器便闪亮登场,把热点的字节码转换为机器码,并把转换后的机器码保存起来,以备下次使用。
原文:https://www.cnblogs.com/xuchengrui/p/13080602.html