在错综复杂的网络,并不一定所有的数据能正常的数据传输,万一数据在传输过程中丢失了呢?
TCP要保证所有的数据包都可以到达,所以,必需要有重传机制。
常见的重传机制:
而所有重传的机制都需要依赖通过序列号Seq与确认应答ACK。
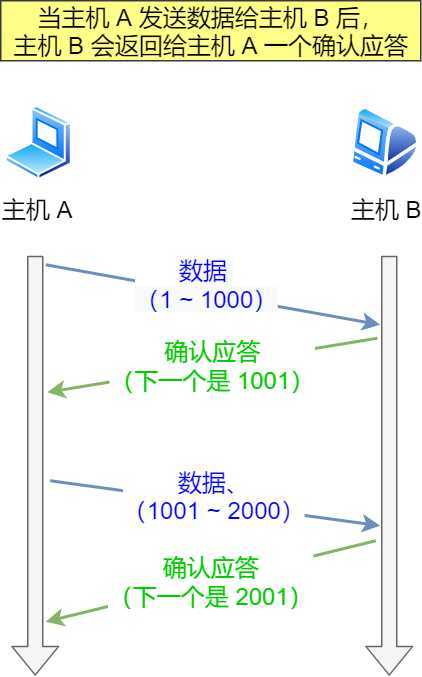
在 TCP 中,当发送端的数据到达接收主机时,接收端主机会返回一个确认应答消息,表示已收到消息。
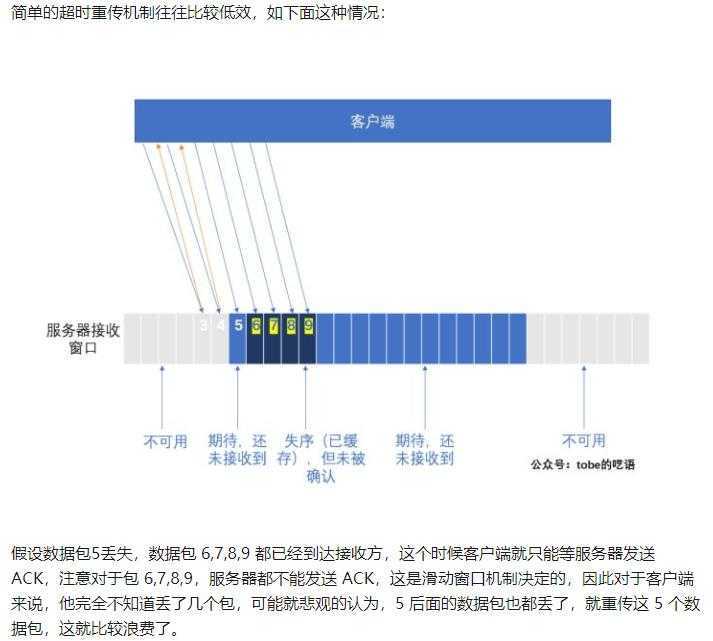
发送端发了1,2,3,4,5一共五份数据,接收端收到了1,2,于是回ack 3,然后收到了4(注意此时3还没收到),此时的TCP会怎么办?我们要知道,因为正如前面所说的,SeqNum和Ack是以字节数为单位,所以ack的时候,不能跳着确认,只能确认最大的连续收到的包,不然,发送端就以为之前的都收到了。
超时重传的处理方式:接收端不再回ack(直到收到数据3),发送端死等ack 3,当发送端发现收不到3的ack超时后,会重传3。一旦接收端收到3后,会ack 回 4——意味着3收到了,期待下一个数据4。
但是,这种方式会有比较严重的问题,那就是因为要死等3,所以会导致4和5即便已经收到了,而发送端也完全不知道发生了什么事,因为没有收到Ack,所以,发送方可能会悲观地认为也丢了,所以有可能也会导致4和5的重传。
对此有两种选择:
TCP 会在以下两种情况发生超时重传:

我们先来了解一下什么是 RTT(Round-Trip Time 往返时延),从下图我们就可以知道:
 RTT
RTT
RTT 就是数据从网络一端传送到另一端所需的时间,也就是包的往返时间。
超时重传时间是以 RTO (Retransmission Timeout 超时重传时间)表示。
假设在重传的情况下,超时时间 RTO 「较长或较短」时,会发生什么事情呢?
 超时时间较长与较短
超时时间较长与较短
上图中有两种超时时间不同的情况:
精确的测量超时时间 RTO 的值是非常重要的,这可让我们的重传机制更高效。
根据上述的两种情况,我们可以得知,超时重传时间 RTO 的值应该略大于报文往返 RTT 的值。
 RTO 应略大于 RTT
RTO 应略大于 RTT
至此,可能大家觉得超时重传时间 RTO 的值计算,也不是很复杂嘛。
好像就是在发送端发包时记下 t0 ,然后接收端再把这个 ack 回来时再记一个 t1,于是 RTT = t1 – t0。没那么简单,这只是一个采样,不能代表普遍情况。
实际上「报文往返 RTT 的值」是经常变化的,因为我们的网络也是时常变化的。也就因为「报文往返 RTT 的值」 是经常波动变化的,所以「超时重传时间 RTO 的值」应该是一个动态变化的值。
我们来看看 Linux 是如何计算 RTO 的呢?
估计往返时间,通常需要采样以下两个:
RFC6289 建议使用以下的公式计算 RTO:
 RFC6289 建议的 RTO 计算
RFC6289 建议的 RTO 计算
其中 SRTT 是计算平滑的RTT ,DevRTR 是计算平滑的RTT 与 最新 RTT 的差距。
在 Linux 下,α = 0.125,β = 0.25, μ = 1,∂ = 4。别问怎么来的,问就是大量实验中调出来的。
如果超时重发的数据,再次超时的时候,又需要重传的时候,TCP 的策略是超时间隔加倍。
也就是每当遇到一次超时重传的时候,都会将下一次超时时间间隔设为先前值的两倍。两次超时,就说明网络环境差,不宜频繁反复发送。
超时触发重传存在的问题是,超时周期可能相对较长。那是不是可以有更快的方式呢?
于是就可以用「快速重传」机制来解决超时重发的时间等待。
不以时间驱动,而以数据驱动重传。
接收端如果没有收到期望的数据,而收到后续乱序的包,也给客户端回复 ACK,只不过是重复的 ACk,回复相同的ACK三次以后触发快速重传。
也就是说,如果,包没有连续到达,就ack最后那个可能被丢了的包,如果发送方连续收到3次相同的ack,就重传。Fast Retransmit的好处是不用等timeout了再重传。
比如:如果发送方发出了1,2,3,4,5份数据,第一份先到送了,于是就ack回2,结果2因为某些原因没收到,3到达了,于是还是ack回2,后面的4和5都到了,但是还是ack回2,因为2还是没有收到,于是发送端收到了三个ack=2的确认,知道了2还没有到,于是就马上重转2。然后,接收端收到了2,此时因为3,4,5都收到了,于是ack回6。示意图如下:
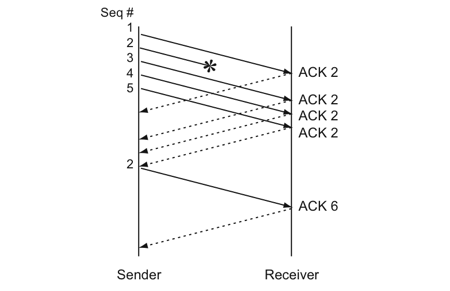
Fast Retransmit只解决了一个问题,就是timeout的问题,它依然面临一个艰难的选择,就是,是重传之前的一个还是重传所有的问题。对于上面的示例来说,是重传#2呢还是重传#2,#3,#4,#5呢?因为发送端并不清楚这连续的3个ack(2)是谁传回来的?也许发送端发了20份数据,是#6,#10,#20传来的呢。这样,发送端很有可能要重传从2到20的这堆数据(这就是某些TCP的实际的实现)。
SACK(Selective Acknowledgment),在快速重传的基础上,返回最近收到的报文段的序列号范围,这样客户端就知道,哪些数据包已经到达服务器了。
如下图,发送方收到了三次同样的 ACK 确认报文,于是就会触发快速重发机制,通过 SACK 信息发现只有 200~299 这段数据丢失,则重发时,就只选择了这个 TCP 段进行重复。
 选择性确认
选择性确认
如果要支持 SACK,必须双方都要支持。在 Linux 下,可以通过 net.ipv4.tcp_sack 参数打开这个功能(Linux 2.4 后默认打开)。
DSACK,即重复 SACK,这个机制是在 SACK 的基础上,额外携带信息,告知发送方有哪些数据包自己重复接收了。DSACK 的目的是帮助发送方判断,是否发生了包失序、ACK 丢失、包重复或伪重传。让 TCP 可以更好的做网络流控。
栗子一号:ACK 丢包
 ACK 丢包
ACK 丢包
D-SACK。栗子二号:网络延时
 网络延时
网络延时
可见,D-SACK 有这么几个好处:
在 Linux 下可以通过 net.ipv4.tcp_dsack 参数开启/关闭这个功能(Linux 2.4 后默认打开)。
笔记整理:
【图解】你还在为 TCP 重传、滑动窗口、流量控制、拥塞控制发愁吗?看完图解就不愁了
原文:https://www.cnblogs.com/-wenli/p/13080675.html