爬取CVPR数据代码

import re import requests import urllib.request import os import argparse parser = argparse.ArgumentParser(description="test") parser.add_argument(‘--keyword‘,type=str,default=‘detection‘) #传参匹配我们想要查找论文的关键字 args = parser.parse_args() # get web context r = requests.get(‘http://openaccess.thecvf.com/CVPR2018.py‘) data = r.text # find all pdf links link_list = re.findall(r"(?<=href=\").+?pdf(?=\">pdf)|(?<=href=\‘).+?pdf(?=\">pdf)" ,data) name_list = re.findall(r"(?<=href=\").+?2018_paper.html\">.+?</a>" ,data) cnt = 1 num = len(link_list) # your local path to download pdf files localDir = ‘./CVPR2018/{}/‘.format(args.keyword) if not os.path.exists(localDir): os.makedirs(localDir) while cnt < num: url = link_list[cnt] # seperate file name from url links file_name = name_list[cnt].split(‘<‘)[0].split(‘>‘)[1] # to avoid some illegal punctuation in file name file_name = file_name.replace(‘:‘,‘_‘) file_name = file_name.replace(‘\"‘,‘_‘) file_name = file_name.replace(‘?‘,‘_‘) file_name = file_name.replace(‘/‘,‘_‘) file_name = file_name.replace(‘ ‘,‘_‘) search_list = file_name.split(‘_‘) search_pattern = re.compile(r‘{}‘.format(args.keyword),re.IGNORECASE) download_next_paper = True # print([True for i in search_list if search_pattern.findall(i)]) if ([True for i in search_list if search_pattern.findall(i)]): download_next_paper = False if download_next_paper: cnt = cnt + 1 continue file_path = localDir + file_name + ‘.pdf‘ if os.path.exists(file_path): print(‘File 【{}.pdf】 exists,skip downloading.‘.format(file_name)) cnt = cnt + 1 continue else: # download pdf files print(‘[‘+str(cnt)+‘/‘+str(num)+"] Downloading -> "+file_path) try: urllib.request.urlretrieve(‘http://openaccess.thecvf.com/‘+url,file_path) except : cnt = cnt + 1 continue cnt = cnt + 1 print("all download finished")
展示统计结果jsp
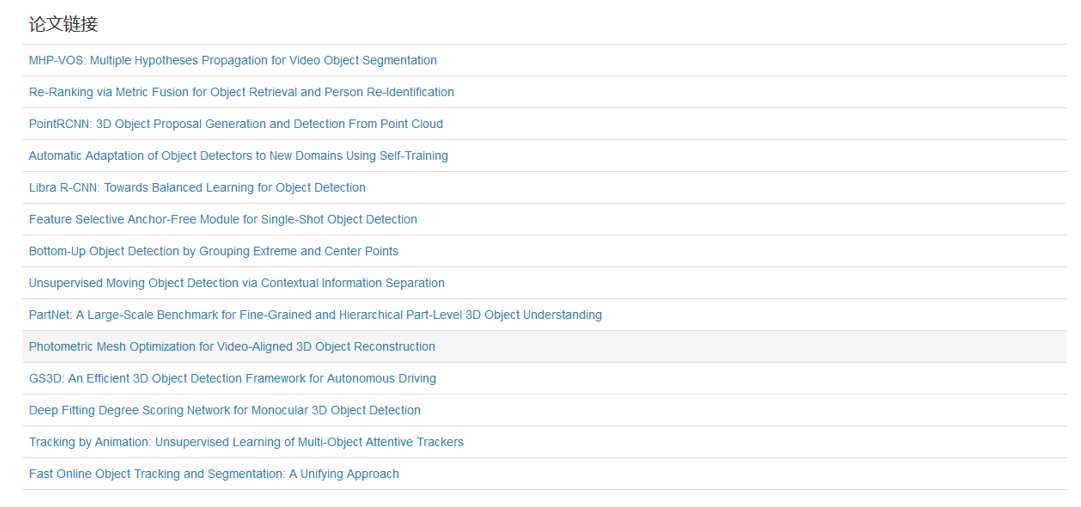
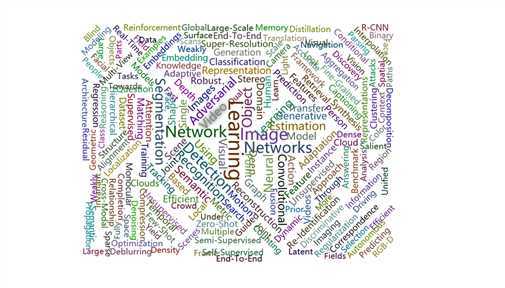
<%@ page language="java" contentType="text/html; charset=UTF-8" pageEncoding="UTF-8"%> <%@ taglib uri="http://java.sun.com/jsp/jstl/core" prefix="c"%> <!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title>顶会热词统计</title> <script src=‘https://cdn.bootcss.com/echarts/3.7.0/echarts.simple.js‘></script> <script src="./js/echarts-wordcloud.js"></script> <script src="./js/jquery-1.11.3.min.js"></script> <style> html, body, #main { width: 100%; height: 100%; margin: 0; } </style> </head> <body> <div id="main"></div> <div> <table class="table table-hover"> <thead> <tr> <td style="font-size: 20px;">论文链接</td> </tr> </thead> <tbody> <c:forEach items="${dataList}" var="data" varStatus="vs"> <tr> <td><a href="${data.lianjie}">${data.title}</a></td> </tr> </c:forEach> </tbody> </table> </div> <script> var chart = echarts.init(document.getElementById(‘main‘)); var postURL = "/PaperData/getData"; var mydata = new Array(); $.ajaxSettings.async = false; $.post(postURL, {}, function(rs) { var dataList = JSON.parse(rs); for (var i = 0; i < dataList.length; i++) { var d = {}; d[‘name‘] = dataList[i].name; d[‘value‘] = dataList[i].value; mydata.push(d); } }); $.ajaxSettings.async = true; var option = { tooltip : {}, series : [ { type : ‘wordCloud‘, gridSize : 2, sizeRange : [ 20, 50 ], rotationRange : [ -90, 90 ], shape : ‘pentagon‘, width : 800, height : 600, drawOutOfBound : false, textStyle : { normal : { color : function() { return ‘rgb(‘ + [ Math.round(Math.random() * 160), Math.round(Math.random() * 160), Math.round(Math.random() * 160) ] .join(‘,‘) + ‘)‘; } }, emphasis : { shadowBlur : 10, shadowColor : ‘#333‘ } }, data : mydata } ] }; chart.setOption(option); chart.on(‘click‘, function(params) { var url = "clickFunction?name=" + params.name; window.location.href = url; }); </script> </body> </html>
原文:https://www.cnblogs.com/chenaiiu/p/13082429.html
