一致性哈希算法的一般用于数据存储路由。当然既然他只是一种算法,也可以用于其他任何方方面面,这里主要还是介绍它的算法实现和数据存储路由的代码实现。在网上看过了很多介绍和实现,其实也挺简单的。
当我们需要在分布式环境下存储数据时,假设有5台服务器作为redis缓存服务器, 当我们要存data1时怎么确定存储在哪一个服务器呢? 传统方法就是对这个data1算出hashcode,然后对这个hashcode%5得出余数,那么这个余数就决定了是这5台redis中的哪一台。这样简单快捷就做到了数据存储路由的目的,这确实也没有BUG。 但是!!缺存在一个操蛋的问题,那就是如果某一天公司上市了,数据量变大了需要增加服务器,那用以前数据的hashcode%6得出的余数,用来去对应服务器取将会取不到。这么做相当于直接清空了所有缓存!!那岂不是服务器要爆炸了,然后导致亏损,,,连续3年,,,退市,,,可怕,刚刚上市就面临退市!
那一致性哈希算法又是怎么回事呢? 一般的一致性哈希算法是
step1.构建一个首为0,尾为2的32次方减1的圆环。
step2.把服务器对应到这个圆环上的某一个值 A,B,C,D,E(假设这是五台服务器IP算出的Hash值)。
step3.对把数据的hashcode%(2的32次方) M。
step4.比较M 与 服务器的Hash值。相等则存在相等的服务器上 或者介于两个值之间的则存在前面的服务器上
如图:
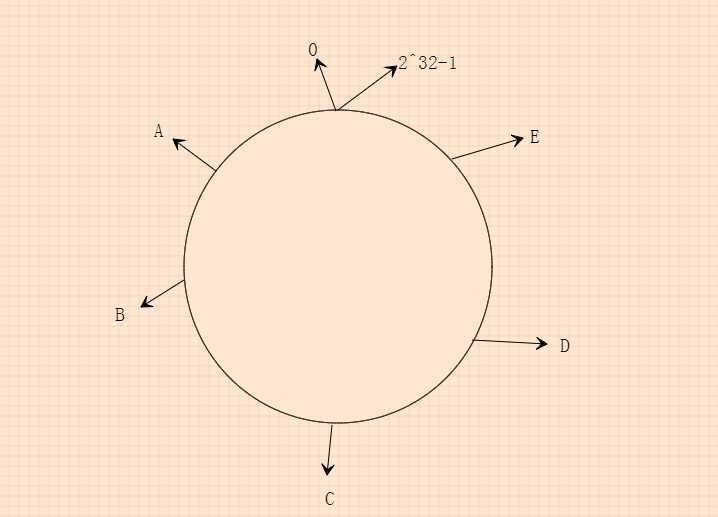
当 M 值处于A-E之间是数据存在E服务器上,B-A之间时存在A服务器上,以此类推。取的时候也是按照这个规则取。
如果添加一个节点,假设在C-D之间,就只需要迁移一部分D的数据到新的节点,而不会影响到其他,另外,这样还有问题,就是当服务器节点太少导致Hash分配不均时,可能会导致失去平衡性。
比如只有两台服务器,然后存储的数据的hashcode老是落在其中一台服务器上,那么这台服务器的压力就会很大,而另一台又会很空闲。这个时候就引入了虚拟节点解决这个问题。
及将每个服务器计算出多个hashcode,如:A#,A$,A&,B#,B$,B&。这样就会多出很大服务器节点,使得数据分配均匀。当数据落在A开头的虚拟节点上时,就把数据存在A中,当数据落在B开头的虚拟节点上时,就把数据存在B中
另外。我在一篇博文中看到的,还可以用树来存储服务器节点,只需要增加一个最大叶子节点和最小叶子节点之间的关系即可,效果是一样的,主要还是要构建一个封闭,循环的结构,然后再通过hashcode路由。
Obj模拟普通数据,有key,value属性
public class Obj { private String key; private String value; public Obj(String key, String value) { this.key = key; this.value = value; } }
ServerNode模拟服务器节点。拥有name和data属性,并且有put,get和获取hashcode的方法。
public class ServerNode implements Comparable<ServerNode> { private String name; private List<Obj> data; public void put(Obj obj) { data.add(obj); } public Obj get(String key){ for (Obj o :data) { if (key.equals(o.getKey())){ return o; } } return null; } public int getHashCode() { return name.hashCode() % (int) Math.pow(2, 32);//对名称取哈希并且对2^32次方取余,保证哈希落在圆环上 } //getter,setter省略 }
ServerStorageTemplate。数据存取的具体工具类。拥有添加服务器节点,添加数据,查找数据的功能,查找数据代码省略,逻辑和添加一致
public class ServerStorageTemplate { private List<ServerNode> serverNodes; public void addServerNode(ServerNode serverNode) { serverNodes.add(serverNode); } public void put(Obj obj) { Collections.sort(serverNodes); int objHash = obj.getKey().hashCode(); int pow = (int) Math.pow(2, 32); int index = objHash % pow; putData(obj, index); } private void putData( Obj obj, int index) { ServerNode head = this.serverNodes.get(0); ServerNode end = this.serverNodes.get(serverNodes.size() - 1); if (index < head.getHashCode() || index > end.getHashCode()) {//当值小于头节点或者大于尾节点时,存在尾节点 serverNodes.get(serverNodes.size() - 1).put(obj); } for (int i = 0; i < serverNodes.size() - 1; i++) {//遍历选择合适得节点 ServerNode serverNode = serverNodes.get(i); ServerNode next = serverNodes.get(i + 1); if (serverNode.getHashCode() < index && index < next.getHashCode()) { serverNode.put(obj); } } } //get方法省略。。。和put逻辑一致 }
然后就是测试代码了。只是通过简单的测试和打印,确认这个方案确实有用。
public static void main(String[] args) { ServerStorageTemplate serverStorageTemplate = new ServerStorageTemplate(); serverStorageTemplate.addServerNode(new ServerNode("10")); serverStorageTemplate.addServerNode(new ServerNode("40")); serverStorageTemplate.addServerNode(new ServerNode("70")); serverStorageTemplate.addServerNode(new ServerNode("90")); serverStorageTemplate.put(new Obj("11","aaaaaa")); serverStorageTemplate.put(new Obj("44","bbbbbb")); serverStorageTemplate.put(new Obj("77","cccccc")); serverStorageTemplate.put(new Obj("99","dddddd")); Obj obj = serverStorageTemplate.get("44"); System.out.println(obj);//Obj{key=‘44‘, value=‘bbbbbb‘} serverStorageTemplate.addServerNode(new ServerNode("42"));//null Obj obj1 = serverStorageTemplate.get("44"); System.out.println(obj1); System.out.println(serverStorageTemplate); }
设计的数据都比较特殊,11这个数据落在10服务器上,44落在40服务器上,,,以此类推。(然后对44这个数据时能够取到的) 然后如果在加一个节点,我们会发现如果加的节点名是100以外的,就会对整个数据和存储没有影响。如果加的节点是42那么,
再去取44这个数据就取不到,因为44这个数据存在40服务器上,但是取的时候是到新节点42去取肯定就取不到。
对于普通哈希算法,新增或者删除节点,会老是出现数据路由出错,查找不到数据,而一致性哈希算法只会影响新增节点前后的两个节点的部分数据
补充:为啥取模的时候使用2^32呢,因为常规下的hashcode的取值范围是-2^31 到 2^31-1。
原文:https://www.cnblogs.com/charlie-xiong/p/13073986.html